先扒一扒HTTP协议背景?
HTTP(HyperText Transfer Protocol) 即超文本传输协议,现在基本上所有web项目都遵从HTTP协议(协议就是一种人为的规范)。
目前绝大部分使用的都是HTTP/1.1版本(1.0太老,2.0仍在制订中。。。)。
因为HTTP协议是属于TCP/IP协议簇的,所以先简单介绍下与HTTP相关的TCP/IP知识。
TCP/IP简介。
TCP/IP是一个协议簇,是由许多协议组成的。
TCP/IP四层模型。
TCP/IP按照层次从上至下分为四层:应用层,传输层,网络层,数据链路层。(实际上最初理论上OSI模型是分的七层,我们程序猿的话通常只用分四层就行了。)
负责传输的IP协议
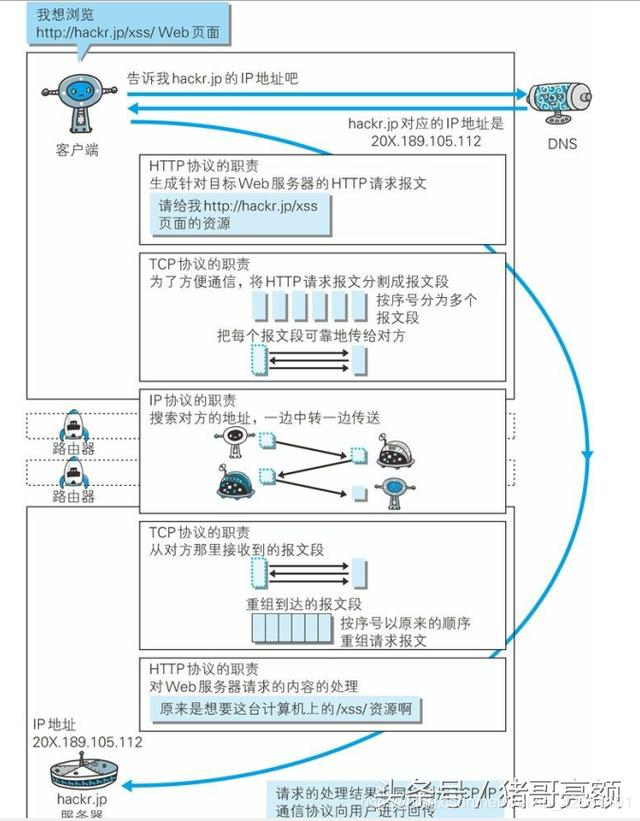
按层次分,IP(Internet Protocol)网际协议位于网络层。Internet Protocol这个名称可能听起来有点夸张,但事实正是如此,因为几乎所有使用网络的系统都会用到IP协议。TCP/IP协议族中的IP指的就是网际协议,协议名称中占据了一半位置,其重要性可见一斑。可能有人会把IP和IP 地址搞混,IP其实是一种协议的名称。
IP协议的作用是把各种数据包传送给对方。而要保证确实传送到对方那里,则需要满足各类条件。其中两个重要的条件是IP地址和MAC地址(Media Access Control Address)。IP地址指明了节点被分配到的地址,MAC地址是指网卡所属的固定地址。IP地址可以和MAC地址进行配对。IP地址可变换,但MAC地址基本上不会更改。
使用ARP协议凭借MAC地址进行通信。IP间的通信依赖MAC地址。在网络上,通信的双方在同一局域网(LAN)内的情况是很少的,通常是经过多台计算机和网络设备中转才能连接到对方。而在进行中转时,会利用下一站中转设备的MAC地址来搜索下一个中转目标。这时,会采用ARP协议(Address Resolution Protocol)。ARP 是一种用以解析地址的协议,根据通信方的IP地址就可以反查出对应的MAC地址。
没有人能够全面掌握互联网中的传输状况,即在传输过程中每一个节点只需要了解下一个节点的信息,再往下的信息就交给下个节点去处理就行了。在到达通信目标前的中转过程中,那些计算机和路由器等网络设备只能获悉很粗略的传输路线。 这种机制称为路由选择(routing),有点像快递公司的送货过程。想要寄快递的人,只要将自己的货物送到集散中心,就可以知道快递公司是否肯收件发货,该快递公司的集散中心检查货物的送达地址,明确下站该送往哪个区域的集散中心。接着,那个区域的集散中心自会判断是否能送到对方的家中。我们是想通过这个比喻说明,无论哪台计算机、哪台网络设备,它们都无法全面掌握互联网中的细节。
确保可靠性的TCP协议。
按层次分,TCP位于传输层,提供可靠的字节流服务。所谓的字节流服务(Byte Stream Service)是指,为了方便传输,将大块数据分割成以报文段(segment)为单位的数据包进行管理。而可靠的传输服务是指,能够把数据准确可靠地传给对方。一言以蔽之,TCP协议为了更容易传送大数据才把数据分割,而且TCP协议能够确认数据最终是否送达到对方。
确保数据能到达目标。为了准确无误地将数据送达目标处,TCP协议采用了三次握手(three-way handshaking)策略。用TCP协议把数据包送出去后,TCP不会对传送后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了TCP的标志(flag) ——SYN(synchronize) 和ACK(acknowledgement)。发送端首先发送一个带SYN标志的数据包给对方。接收端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息。最后,发送端再回传一个带ACK标志的数据包,代表握手结束。若在握手过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包。除了上述三次握手,TCP协议还有其他各种手段来保证通信的可靠性。
负责域名解析的DNS服务。
DNS(Domain Name System)服务是和HTTP协议一样位于应用层的协议。它提供域名到IP地址之间的解析服务。计算机既可以被赋予IP地址,也可以被赋予主机名和域名。比如www.baidu.com。因为域名更加直观,所以用户通常使用主机名或域名来访问对方的计算机,而不是直接通过IP地址访问。但要让计算机去理解名称,相对而言就变得困难了。因为计算机更擅长处理一长串数字。为了解决上述的问题,DNS服务应运而生。DNS协议提供通过域名查找IP地址,或逆向从IP地址反查域名的服务。
HTTP协议与其他TCP/IP协议是如何协作的?
RI和URL。
URI是Uniform Resource Identifier的缩写,即统一资源标识符。
RFC2396分别对这 3 个单词进行了如下定义:
Uniform :规定统一的格式可方便处理多种不同类型的资源, 而不用根据上下文环境来识别资源指定的访问方式。另外, 加入新增的协议方案(如http:或ftp:) 也更容易。
Resource :资源的定义是可标识的任何东西。 除了文档文件、 图像或服务(例如当天的天气预报) 等能够区别于其他类型的, 全都可作为资源。 另外, 资源不仅可以是单一的, 也可以是多数的集合体。
Identifier :表示可标识的对象。 也称为标识符。
综上所述,URI就是由某个协议方案表示的资源的定位标识符。 协议方案是指访问资源所使用的协议类型名称。 采用HTTP协议时, 协议方案就是http。 除此之外, 还有ftp、mailto、telnet、file等。 标准的URI协议方案有 30 种左右, 由隶属于国际互联网资源管理的非营利社团ICANN(Internet Corporation for Assigned Names and Numbers, 互联网名称与数字地址分配机构) 的IANA(Internet Assigned Numbers Authority, 互联网号码分配局) 管理颁布。
URI用字符串标识某一互联网资源, 而URL表示资源的地点(互联网上所处的位置) 。 可见URL是URI的子集。(当然通常可以大致把URL理解成URI)
URI的格式。
要想表示指定的资源, 就得使用涵盖全部必要信息的绝对URI,同样的也会有相对URI。这里以相对URL为例,就是指从浏览器中基本URL处指定的URL,形如/image/logo.gif这种形式。
接下来结合下面这个例子着重介绍一下绝对URI:

协议方案名:使用http:或https:等协议方案名获取访问资源时要指定协议类型。 不区分字母大小写, 最后附一个冒号(:)。也可使用data:或javascript:这类指定数据或脚本程序的方案名。
登录信息(认证) :指定用户名和密码作为从服务器端获取资源时必要的登录信息(身份认证) 。 此项是可选项。
服务器地址 :使用绝对URI必须指定待访问的服务器地址。 地址可以是类似baidu.com这种DNS可解析的域名, 或是192.168.1.1这类IPv4地址, 还可以是[0:0:0:0:0:0:0:1]这样用方括号括起来的IPv6地址。
服务器端口号 :指定服务器连接的网络端口号。 此项也是可选项, 若用户省略则自动使用默认端口号。
带层次的文件路径 :指定服务器上的文件路径来定位特指的资源。 这与UNIX系统的文件目录结构相似。
查询字符串 :针对已指定的文件路径内的资源, 可以使用查询字符串传入任意参数。 此项可选。
片段标识符 :使用片段标识符通常可标记出已获取资源中的子资源(文档内的某个位置) 。 但在RFC中并没有明确规定其使用方法。 该项也为可选项。
RFC : Request for Comments, 征求修正意见书。一些用来制定HTTP协议技术标准的文档,当然并不是强制性的,所以还是有一小部分应用程序并没有遵从RFC标准,这也就导致了其他应用不同标准的互联网资源可能就无法与该应用程序进行通讯了。
RFC3986列举了几种URI的常用语法格式:
tp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:[email protected]
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
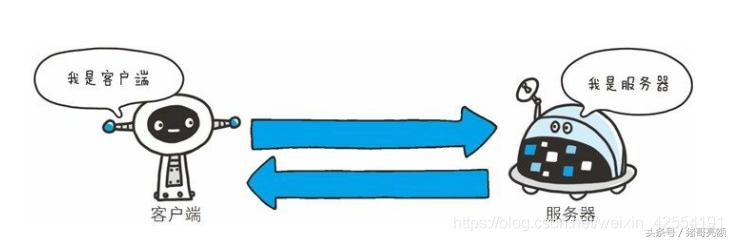
HTTP协议用于客户端和服务器端之间的通信。
HTTP协议和TCP/IP协议族内的其他众多的协议相同, 用于客户端和服务器之间的通信。请求访问文本或图像等资源的一端称为客户端, 而提供资源响应的一端称为服务器端。在两台计算机之间使用HTTP协议通信时, 在一条通信线路上必定有一端是客户端, 另一端则是服务器端。有时候, 按实际情况, 两台计算机作为客户端和服务器端的角色有可能会互换。 但就仅从一条通信路线来说, 服务器端和客户端的角色是确定的, 而用HTTP协议能够明确区分哪端是客户端, 哪端是服务器端。
通过请求和响应的交换达成通信。
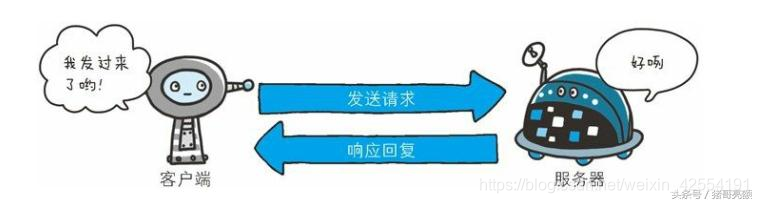
HTTP协议规定, 请求从客户端发出, 最后服务器端响应该请求并返回。 换句话说, 肯定是先从客户端开始建立通信的, 服务器端在没有接收到请求之前不会发送响应。
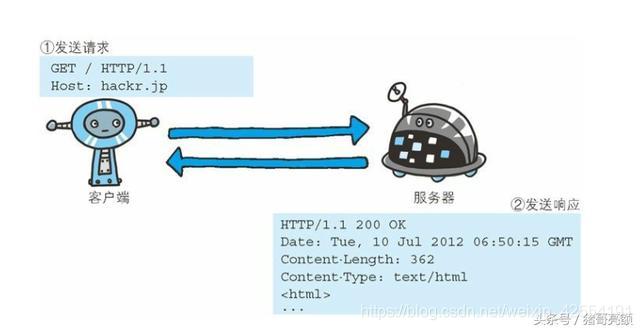
起始行开头的GET表示请求访问服务器的类型, 称为方法(method) 。 随后的字符串/index.htm指明了请求访问的资源对象,也叫做请求URI(request-URI) 。 最后的HTTP/1.1, 即HTTP的版本号, 用来提示客户端使用的HTTP协议功能。综合来看, 这段请求内容的意思是: 请求访问某台HTTP服务器上的/index.htm页面资源。
请求报文是由请求方法、 请求URI、 协议版本、 可选的请求首部字段和内容实体构成的。
HTTP是不保存状态的协议。
HTTP是一种不保存状态, 即无状态(stateless) 协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。 也就是说在HTTP这个级别, 协议对于发送过的请求或响应都不做持久化处理。
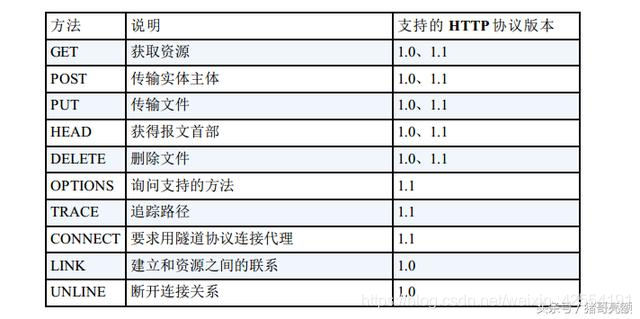
下表列出了HTTP/1.0和HTTP/1.1支持的方法。 另外, 方法名区分大小写, 注意要用大写字母。
使用 Cookie 的状态管理。
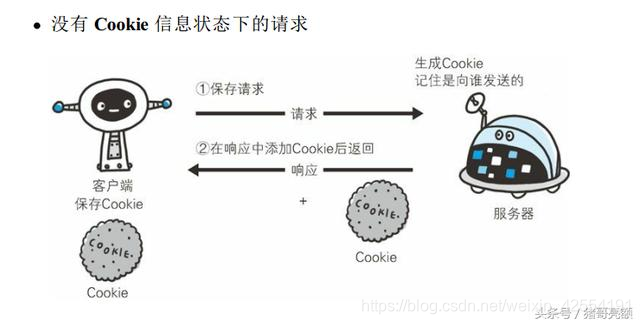
HTTP 是无状态协议, 它不对之前发生过的请求和响应的状态进行管理。 也就是说, 无法根据之前的状态进行本次的请求处理。假设要求登录认证的 Web 页面本身无法进行状态的管理(不记录已登录的状态) , 那么每次跳转新页面不是要再次登录, 就是要在每次请求报文中附加参数来管理登录状态。不可否认, 无状态协议当然也有它的优点。 由于不必保存状态, 自然可减少服务器的 CPU 及内存资源的消耗。 从另一侧面来说, 也正是因为 HTTP 协议本身是非常简单, 所以才会被应用在各种场景里。
保留无状态协议这个特征的同时又要解决类似的矛盾问题, 于是引入了 Cookie 技术。 Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息, 通知客户端保存 Cookie。当下次客户端再往该服务器发送请求时, 客户端会自动在请求报文中加入 Cookie 值后发送出去。服务器端发现客户端发送过来的 Cookie 后, 会去检查究竟是从哪一个客户端发来的连接请求, 然后对比服务器上的记录, 最后得到之前的状态信息。
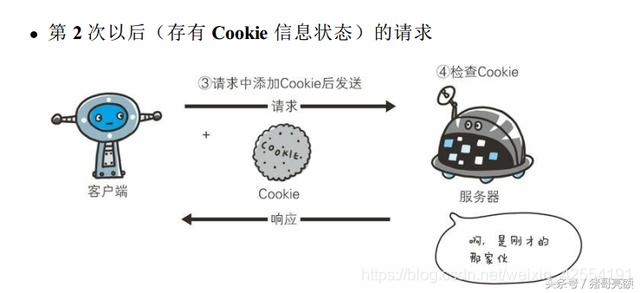
上图展示了发生 Cookie 交互的情景, HTTP 请求报文和响应报文的内容如下。
有关请求报文和响应报文内 Cookie 对应的首部字段, 请参考之后的章节。
HTTP 报文内的 HTTP 信息。
HTTP 通信过程包括从客户端发往服务器端的请求及从服务器端返回客户端的响应。 本章就让我们来了解一下请求和响应是怎样运作的。
HTTP 报文。
用于 HTTP 协议交互的信息被称为 HTTP 报文。 请求端(客户端) 的 HTTP 报文叫做请求报文, 响应端(服务器端) 的叫做响应报文。HTTP报文本身是由多行(用 CR+LF 作换行符) 数据构成的字符串文本。HTTP 报文大致可分为报文首部和报文主体两块。 两者由最初出现的空行(CR+LF) 来划分。 通常, 并不一定要有报文主体。
原文链接:https://www.cnblogs.com/daijiabao/p/11183265.html
