多进程和多线程是工程和科研工作中常用的技术手段,在介绍二者之前我们先了解一下并发(concurrency)和并行(parallellism)。
严谨权威的定义网上比较多,我就用个人理解的方式介绍。
并行:父亲和儿子同时度过一天。
并发:我吃完早饭吃午饭,吃完午饭吃晚饭,我度过了一天。
并行与并发最大的区别就在于一个同时性,并行是具有同时性的操作,然而并发是一个伪同时性的操作。根据上面所说的例子来讲,父亲和儿子同时度过一天,这一天对于父亲和儿子都是独立的,他们各自度过了独立且完整的一天。相比较而言,我虽然吃了三顿饭度过了一天,但是这三顿饭是有先后顺序的。
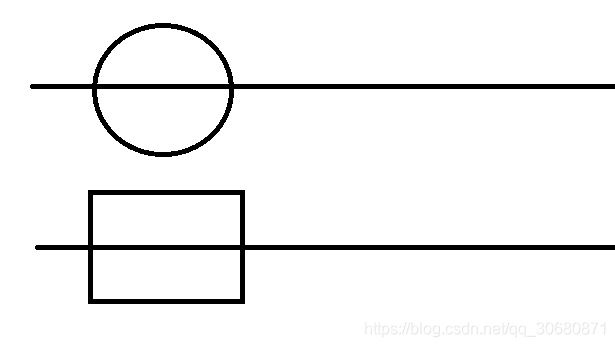
 如果用图直观表示的话,圆和矩形就是父亲和儿子,他们是同时平行的度过一天。五角星就是早、中、晚饭,虽然一天内做了这三件事,但是他们不是同时进行的,是有先后顺序的。
如果用图直观表示的话,圆和矩形就是父亲和儿子,他们是同时平行的度过一天。五角星就是早、中、晚饭,虽然一天内做了这三件事,但是他们不是同时进行的,是有先后顺序的。
并行与并发的区别:
1、同时性。并行有,并发没有,并发只是通过高速切换指令实现伪并行。
2、并行在多处理系统中存在,并发可以在单处理器和多处理器系统中存在。
言归正传,来谈多进程与多线程。
“进程是资源分配的最小单位,线程是CPU调度的最小单位”
线程可以算作进程的子集,一个进程可能由多个线程组成,多进程的数据是分开的,共享复杂但同步简单;多线程共享进程数据,共享简单但同步复杂。
同样的举个栗子。
假设有一场赛车比赛,比的是赛车共行驶的距离。多进程和多线程是两位参赛选手。
多进程:修了五条路,放了五辆跑车,同时行驶。
多线程:修了一条路,每隔五公里放一辆跑车,类似接力的形式,这条路上虽然放了很多辆车,但是始终只能有一辆在行驶。
结果显而易见,如果单纯比行驶距离,多进程是胜者,但是多进程的缺点就是进程间调用、通讯和切换开销均比多线程大(修了五条路肯定开销大啊…)。
如果不严谨的来说,多进程是具有并行性,多线程是具有并发性。
多进程代码:
from multiprocessing import Process,Pool #导入相应的包
def run(name):
print('%s runing' %name)
p1=Process(target=run,args=('anne',)) #必须加,号 ,run就是该进程需要执行的函数,args是该函数所需的参数。
p1.start()#开启进程
p1.join()#确保p1进程执行完后才执行后面的进程
以上是开启一个进程的操作,如果想开启多个进程,详情如下:

subproc_GPU = []
for iter in range(16):
p_GPU = Process(target=invert_GPU, args=(L, U))
subproc_GPU.append(p_GPU)
p_GPU.start()
for iter in subproc_GPU:
iter.join()
这样操作的话16个进程开启后再挨个join,所以会有16个进程同时执行。如果start()一个进程紧跟着就join(),那么这16个进程就会发生阻塞,就不会同时执行,详情如下:
subproc_GPU = []
for iter in range(16):
p_GPU = Process(target=invert_GPU, args=(L, U))
subproc_GPU.append(p_GPU)
p_GPU.start()
p_GPU.join()
如果需要管理进程数量和进程返回值,可以考虑使用进程池。
result_multi_2_GPU=[]
p1_2_GPU = Pool(8)
result_2_2_GPU=[]
for iter in range(8):
result1_2_GPU = p1_2_GPU.apply_async(LU_decomposition, args=(A,))
result_multi_2_GPU.append(result1_2_GPU)
array_multi_2_GPU=cp.array(result_multi_2_GPU[0].get(),dtype=float)
time.sleep(0.000000000001)
result_2_GPU = p1_2_GPU.apply_async(invert_GPU, args=(array_multi_2_GPU[0],array_multi_2_GPU[1] ))
p1_2_GPU.close()
p1_2_GPU.join()
#print(result_multi_2_GPU.get())
需要注意的是,有时候需要一个很小的time.sleep()才能创建新的进程。p.apply(work,args=(i,)) 属于同步调用,可以直接输出返回值,p.apply_async(work,args=(i,))属于异步调用,需要通过返回值调用get()函数才能输出。
多线程代码:
import threading
def run():
print("run-a")
def runsub(b):
b.start()
b.join()
print("run-b")
t = threading.Thread(target=run)
t2 = threading.Thread(target=runsub, args=(t,))
t2.start()
t2.join()
线程对象可以作为参数传递,在CPU计算时可以调用numpy,GPU计算时可以调用cupy,numpy和cupy大体函数相似,但是cupy没有mat等函数,需注意和numpy区分。
