一、概述
1.什么是Hive?
- hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目。 hive.apache.org
- hive是一个基于大数据技术的数据仓库技术 DataWareHouse (数仓),底层依附是HDFS,MapReduce。
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张数据库表,并提供简单的查询功能,可以将SQL语句转换成MapReduce任务进行运行。
2.数据库与数据仓库的区别?
- 数据库(DataBase): 数据量级小,存储的数据价值高(比如用户订单、用户信息等) 。
- 数据仓库(DataWareHouse): 数据体量大,存储的数据价值低(比如一些日志信息)。
3.Hive有什么好处?
Hive让程序员应用时,书写SQL(HQL)语句,最终由Hive把SQL(HQL)语句转换成MapReduce运行,这样简化了程序员的工作。
二、Hive的运行原理
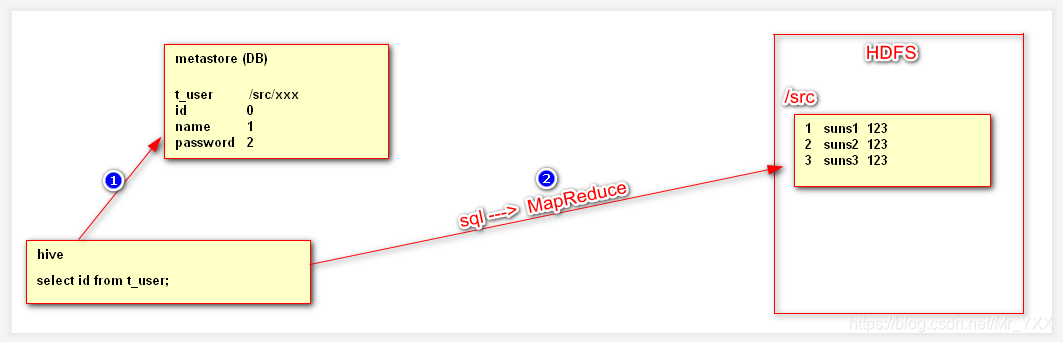
三、Hive的环境搭建
1. linux服务器 ip 映射 主机名 关闭防火墙 关闭selinux ssh免密登陆 jdk
2. 搭建hadoop环境
3. 安装Hive
3.1 解压缩hive
3.2 hive_home/conf/hive-env.sh [改名]
HADOOP_HOME=/usr/hadoop/hadoop-2.9.2
export HIVE_CONF_DIR=/usr/hive/apache-hive-0.13.1-bin/conf
3.3 在hdfs中创建2个目录
/tmp
/user/hive/warehouse
bin/hdfs dfs -mkdir /tmp
bin/hdfs dfs -mkdir /user/hive/warehouse
3.4 启动hive
bin/hive
3.5 jps 看见以下进程则代表安装成功
runjar
四、MetaStore的替换问题
Hive中的MetaStore把HDFS对应结构,与表对应结果做了映射(对应)。但是默认情况下hive的metaStore应用的是derby数据库,只支持一个client访问。
1.Hive中元数据库Derby替换成MySQL(Oracle)
- linux mysql 安装
yum -y install mysql-server
2.启动mysql服务并设置管理员密码
service mysqld start
/usr/bin/mysqladmin -u root password '123456'
3.打开mysql远程访问权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
flush privileges;
use mysql
delete from user where host like 'hadoop%';
delete from user where host like 'l%';
delete from user where host like '1%';
service mysqld restart
4.创建conf/hive-site.xml 并配置
mv hive-default.xml.template hive-site.xml
vim hive-site.xml
<!--配置连接mysql的基本信息-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://HadoopNode00:3306/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--配置使用hive命令时显示使用的库名-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--使用hive命令时显示使用的表名-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
- hive_home/lib 上传mysql driver jar包
- mysql-connector-java-5.1.39-bin.jar(在网上自行下载)
五、Hive基本操作
# 创建数据库
create database [if not exists] db_name;
# 查看所有数据库
show databases;
# 查看数据库的本质
hive中的数据库 本质是 hdfs的目录 /user/hive/warehouse/db_name
# 使用数据库
use db_name;
# 删除空数据库
drop database db_name;
drop database db_name cascade;
# 查看当前数据库下的所有表
show tables;
# 查看表的本质
hive中的表 本质是 hdfs的目录 /user/hive/warehouse/db_name/t_user
# 建表语句
create table t_user(
id int ,
name string
)row format delimited fields terminated by '\t';
#row format delimited fields terminated by '\t'的意思是列与列之间的间隔符合为制表符
# 删除表
drop table t_user;
# hive中向表导入数据
load data local inpath '/root/hive/data' into table t_user;
# hive导入数据的本质
load data local inpath '/root/hive/data' into table t_user;
1. 导入数据 本质本质上就是 hdfs 上传文件
bin/hdfs dfs -put /root/hive/data /user/hive/warehouse/db_name/t_user;
2. 上传了重复数据,hive导数据时,会自动修改文件名
3. 查询某一个张表时,Hive会把表中这个目录下所有文件的内容,整合查询出来
# SQL(类SQL 类似于SQL HQL Hive Query Language)
select * from t_user;
select id from t_user;
1. Hive把SQL转换成MapReduce (如果清洗数据 没有Reduce)
2. Hive在绝大多数情况下运行MR,但是在* limit操作时不运行MR
