Hive的语法细节
- HQL (SQL)
1. 基本查询
select * from table_name # 不启动mr
select id from table_name # 启动mr
2. 条件查询 where
select id,name from t_users where name = 'yx';
2.1 比较查询 = != >= <=
select id,name from t_users where age > 20;
2.2 逻辑查询 and or not
select id,name,age from t_users where name = 'yx' or age>30;
2.3 谓词运算
between and
select name,salary from t_users where salary between 100 and 300;
in
select name,salary from t_users where salary in (100,300);
is null
select name,salary from t_users where salary is null;
like(模糊查询)
select name,salary from t_users where name like 'yx%';
select name,salary from t_users where name like 'yx__';
select name,salary from t_users where name like 'yx%' and length(name) = 6;
3. 排序 order by [底层使用的是 map sort group sort compareto]
select name,salary from t_users order by salary desc;
4. 去重 distinct
select distinct(age) from t_users;
5. 分页 [Mysql可以定义起始的分页条目,但是Hive不可以]
select * from t_users limit 3;
6. 聚合函数(分组函数) count() avg() max() min() sum()
count(*) count(id) 区别
count(*) 不能排除字段值为null的值
7. group by
select max(salary) from t_users group by age;
规矩: select 后面只能写 分组依据和聚合函数 (Oracle报错,Mysql不报错,结果不对)
8. having
分组后,聚合函数的条件判断用having
select max(salary) from t_users group by age having max(salary) > 800;
9. hive不支持子查询
10. hive内置函数
show functions
length(column_name) 获得列中字符串数据长度
substring(column_name,start_pos,total_count) 截取某字段值的长度
concat(col1,col2) 联合查询
to_data('yyyy-mm-dd')
year(data) 获得年份
month(data) 获得月份
date_add
....
select year(to_date('1999-10-11')) ;
表连接查询
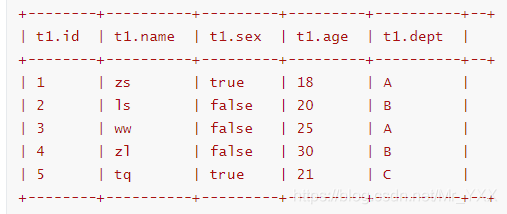
准备的数据
# 员工数据
1,zs,true,18,A
2,ls,false,20,B
3,ww,false,25,A
4,zl,false,30,B
5,tq,true,21,C
# 部门数据
A,研发部
B,市场部
C,销售部
D,后勤部
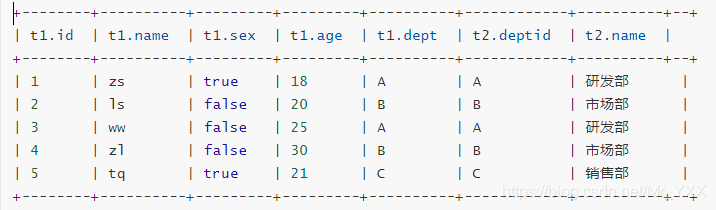
- 内连接([inner] join)左表和右表符合条件的数据进行连接操作,合为一张大表;
select * from t_employee t1 inner join t_dept t2 on t1.dept = t2.deptId;
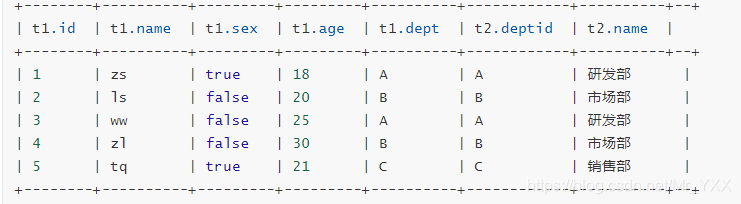
- 外连接(left | right outer join)
select * from t_employee t1 left outer join t_dept t2 on t1.dept = t2.deptId;
select * from t_employee t1 right outer join t_dept t2 on t1.dept = t2.deptId;
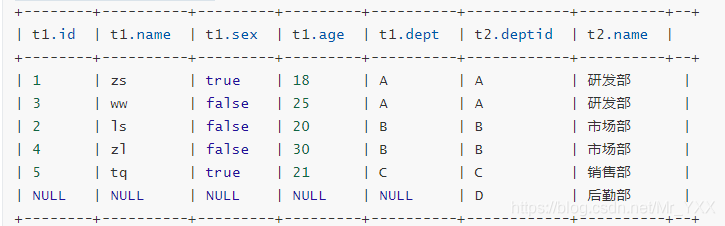
- 左半开连接(left semi join)左半开连接会返回左表的数据,前提是记录需要满足右表on的判定条件;
select * from t_employee t1 left semi join t_dept t2 on t1.dept = t2.deptId;
2 表相关的操作
- 管理表 (MANAGED_TABLE)
1. 基本管理表的创建
create table if not exists table_name(
column_name data_type,
column_name data_type
)row format delimited fields terminated by '\t' [location 'hdfs_path']
2. as 关键字创建管理表
create table if not exists table_name as select id,name from t_users [location ''];
表结构 由 查询的列决定,同时会把查询结果的数据 插入新表中
3. like 关键字创建管理表
create table if not exists table_name like t_users [location 'hdfs_path'];
表结构 和 like关键字后面的表 一致,但是没有数据是空表
细节:
1. 数据类型 int string varchar char double float boolean
2. location hdfs_path
定制创建表的位置,默认是/user/hive/warehouse/db_name.db/table_name
create table t_suns(
id,int
name,string
)row format delimited fields terminated by '\t' location /xiaohei ;
启示:日后先有hdfs目录,文件,在创建表进行操作。
3. 查看hive表结构的命令
desc table_name describe table_name
desc extended table_name
desc formatted table_name
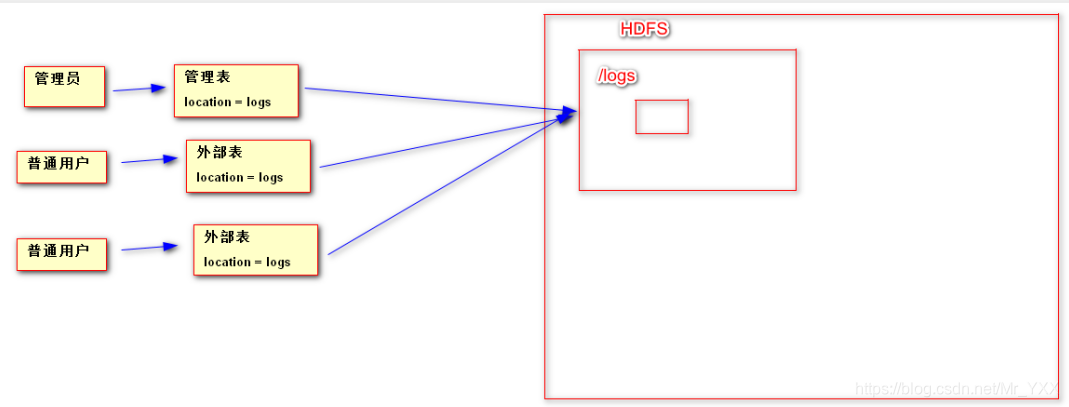
- 外部表
1. 基本
create external table if not exists table_name(
id int,
name string
) row delimited fields terminated by '\t' [location 'hdfs_path'];
2. as
create external table if not exists table_name as select id,name from t_users [location ''];
3. like
create external table if not exists table_name like t_users [location 'hdfs_path'];
1. 管理表和外部表的区别
drop table t_users_as; 删除管理表时,直接删除metastore,同时删除hdfs的目录和数据文件
drop table t_user_ex; 删除外部表时,删除metastore的数据。
2. 外部表与管理表使用方式的区别
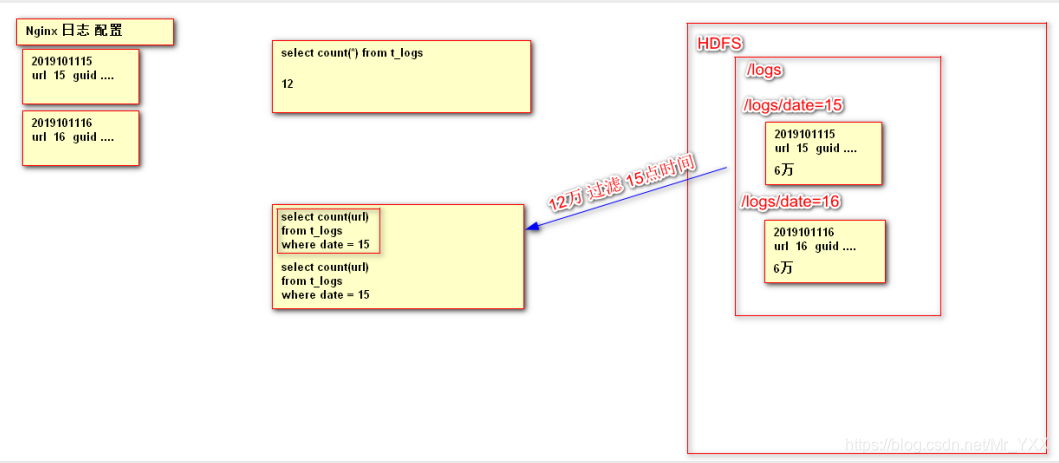
- 分区表 【查询优化】
外部表或者内部表都可以在创建时指定分区,这样的就构成了分区表;分区就是数据分片思想,将一个大数据集按照规则划分为若干个小数据集,这样在进行数据加载或者处理时会有比较好处理性能; 优化策略
思想:如下图所示
create table t_user_part(
id int,
name string,
age int,
salary int)partitioned by (data string) row format delimited fields terminated by '\t';
load data local inpath '/root/data15' into table t_user_part partition (date='15');
load data local inpath '/root/data16' into table t_user_part partition (date='16');
select * from t_user_part 全表数据进行的统计
select id from t_user_part where data='15' and age>20;
- 分桶表
分桶表指将数据集分解成容易组织管理若干个部分的技术;解决数据倾斜问题,已经大表和大表的JOIN,高效数据取样;
# 1. 创建分桶表
create table t_bucket(id int,name string) clustered by (id) into 3 buckets;
# 2. 注意 分桶表在装载数据时不能使用load
# 3. 特殊设置
# 强制使用分桶表
set hive.enforce.bucketing = true;
# 设置reducer 任务数量 = 桶的数量
set mapred.reduce.tasks = 3;
# 4. 临时表 首先将数据加载临时表中
create temporary table t_bucket_tmp(id int,name string);
load data local inpath '/usr/apache-hive-1.2.1-bin/data/bucketTmp.txt' into table t_bucket_tmp;
# 5. 将临时表中的数据转换到分桶表中
insert into t_bucket select * from t_bucket_tmp cluster by id;
- 临时表
临时表关键字:`temporary`
生命周期依赖于会话
create temporary table ttt_user(id int,name string);
3.数据的导入
#基本导入
load data local inpath 'local_path' into table table_name
#通过as关键完成数据的导入 建表的同时,通过查询导入数据
create table if not exists table_name as select id,name from t_users
#通过insert的方式导入数据 表格已经建好,通过查询导入数据。
create table t_users_like like t_users;
insert into table t_users_like select id,name,age,salary from t_users;
#hdfs导入数据
load data inpath 'hdfs_path' into table table_name
#导入数据过程中数据的覆盖(本质 把原有表格目录的文件全部删除,再上传新的)
load data inpath 'hdfs_path' overwrite into table table_name
#通过HDFS的API完成文件的上传
bin/hdfs dfs -put /xxxx /user/hive/warehouse/db_name.db/table_name
4.数据的导出
#sqoop
hadoop的一种辅助工具 HDFS/Hive <------> RDB (MySQL,Oracle)
#insert的方式(xiaohei一定不能存在,自动创建)
insert overwrite 【local】 directory '/root/xiaohei' select name from t_user;
#通过HDFS的API完成文件的下载
bin/hdfs dfsd -get /user/hive/warehouse/db_name.db/table_name /root/xxxx
#命令行脚本的方式
bin/hive --database 'db_name -f /root/hive.sql > /root/result
#Hive提供导入,导出的工具
1. export 导出
export table tb_name to 'hdfs_path'
2. import 导入
import table tb_name from 'hdfs_path'
5.Hive中的相关配置参数
#与MR相关的参数
Map --> Split ---> Block
#reduce相关个数
mapred-site.xml
<property>
<name>mapreduce.job.reduces</name>
<value>1</value>
</property>
hive-site.xml
<!--1G-->
<property>
<name>hive.exec.reducers.bytes.per.reducer</name>
<value>1000000000</value>
</property>
<!--最大reduces数量默认999-->
<property>
<name>hive.exec.reducers.max</name>
<value>999</value>
</property>
<!--在查询中是否启动MR 是如下参数配置决定的 -->
<property>
<name>hive.fetch.task.conversion</name>
<value>minimal</value>
<description>
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
</description>
</property>
6.Hive启动的相关参数
1. 启动hive终端时,临时设置hive的配置参数
bin/hive --hiveconf
2. 启动hive时,指定启动的数据库
bin/hive --database db_name
3. 启动hive时,可以执行sql命令,执行完毕后,退出
bin/hive -e 'sql'
bin/hive --database db_name -e 'sql'
bin/hive --database db_name -e 'select * from t_user' > /root/result
bin/hive --database db_name -e 'select * from t_user' >> /root/result
4. 启动hive是,如果需要执行多条sql可以把sql写在一个独立的文件里,执行。完毕退出
bin/hive -f /root/hive.sql
bin/hive --database db_name -f /root/hive.sql > /root/result
bin/hive --database db_name -f /root/hive.sql >> /root/result
7.Hive 和HBase整合
要求
- HDFS
- ZooKeeper
- HBase集群运行正常
准备HBase BigTable
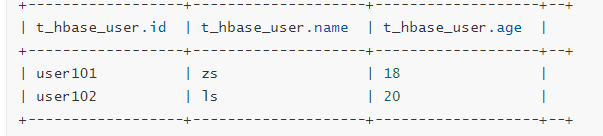
create 'b:t_user','cf1'
put 'b:t_user','user101','cf1:name','zs'
put 'b:t_user','user101','cf1:age','18'
put 'b:t_user','user102','cf1:name','ls'
put 'b:t_user','user102','cf1:name','20'
创建Hive Table 关联HBase
create external table t_hbase_user(id string,name string,age int) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,cf1:name,cf1:age') tblproperties('hbase.table.name'='b:t_user');
select * from t_hbase_user;