下载文件elf文件,运行输入flag,用ida打开逆向算法:
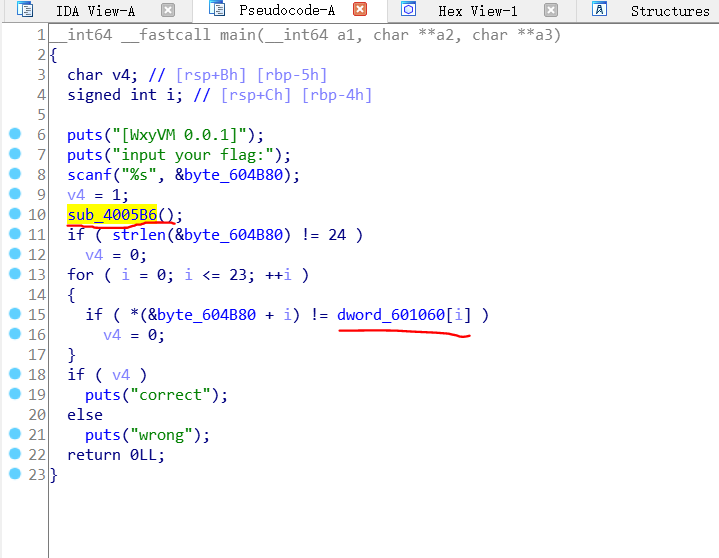
不是很复杂,可以看出flag长度需要24,最终会和已给出dword_601060进行比较,一致则成功,那么现在只需要看上面的sub_4005B6()和函数了:

跟进两个地址进去看一下,发现有已经给出的处理所需数据,只是比较多,有15000个,想了想最后还是决定把数据提出来(其实是没其他办法了==)
提数据:
最后的比对的24个16进制数可以直接手写出来,注意因为是dword类型的,左移只取每4个字节的最后一个字节数据:
0xc4,0x34,0x22,0xb1,0xd3,0x11,0x97,0x7,0xdb,0x37,0xc4,0x6,0x1d,0xfc,0x5b,0xed,0x98,0xdf,0x94,0xd8,0xb3,0x84,0xcc,0x8
然后是那15000个数据,按上图方式复制下载发现需要提取的数据都是很整齐得占据了3个位置:
用c++写的:
#include "iostream" #include "stdio.h" #include "cstring" using namespace std; int main(){ freopen("test.txt", "r", stdin); ///test.txt是复制后保存的原文本,15000行,一行一个数据 freopen("outans.txt", "w", stdout); //outans.txt为提取的数据 char s[200], out[5]; while(cin.getline(s, 200)){ out[0] = s[43], out[1] = s[44], out[2] = s[45], out[3] = 0; cout<<"0x"<<out<<','; } return 0; }
最后用有替换功能的编辑器比如notepad++打开outans.txt文件,替换一下空格和’h'字符为空就行了;
最后是逆推py脚本:
1 # -*- coding: utf-8 -*- 2 final = [0xc4,0x34,0x22,0xb1,0xd3,0x11,0x97,0x7,0xdb,0x37,0xc4,0x6,0x1d,0xfc,0x5b,0xed,0x98,0xdf,0x94,0xd8,0xb3,0x84,0xcc,0x8] 3 tmp = [0x1,0x10,0x25,0x3,0x0D,0x0A,0x2,0x0B,0x28,0x2,0x14,0x3F,0x1,0x17,0x3C,0x1,0x0,0x69,0x1,0x12,0x3F,......] 4 i = 14997 5 while i >= 0: 6 v0 = tmp[i] 7 v3 = tmp[i+2] 8 if v0 == 1: 9 final[tmp[i+1]] -= v3 10 elif v0 == 2: 11 final[tmp[i+1]] += v3 12 elif v0 == 3: 13 final[tmp[i+1]] ^= v3 14 elif v0 == 4: 15 final[tmp[i+1]] /= v3 16 elif v0 == 5: 17 final[tmp[i+1]] ^= final[tmp[i+2]] 18 final[tmp[i+1]] &= 0xff //需要注意的地方,因为ascii字符码范围为0~127,可能发生越界 19 i -= 3 20 21 for x in final: 22 print(chr(x), end = '')
得到flag:nctf{Embr4ce_Vm_j0in_R3}
被数据范围坑了好久,以后要多多注意。