1. 以前面的一个例子进行引入:
在led驱动程序中,故意使用其物理地址
Unable to handle kernel paging request at virtual address 56000050
//无法处理内核页面请求的虚拟地址56000050
pgd = c3850000
[56000050] *pgd=00000000
Internal error: Oops: 5 [#1]
//内部错误oops
Modules linked in: 26th_segmentfault
//表示内部错误发生在26th_segmentfault.ko驱动模块里
CPU: 0 Not tainted (2.6.22.6 #2)
PC is at first_drv_open+0x78/0x12c [26th_segmentfault]
//PC值:程序运行成功的最后一次地址,位于first_drv_open()函数里,偏移值0x78,该函数总大小0x12c
LR is at 0xc0365ed8 //LR值
/*发生错误时的各个寄存器值*/
pc : [<bf000078>] lr : [<c0365ed8>] psr: 80000013
sp : c3fcbe80 ip : c0365ed8 fp : c3fcbe94
r10: 00000000 r9 : c3fca000 r8 : c04df960
r7 : 00000000 r6 : 00000000 r5 : bf000de4 r4 : 00000000
r3 : 00000000 r2 : 56000050 r1 : 00000001 r0 : 00000052
Flags: Nzcv IRQs on FIQs on Mode SVC_32 Segment user
Control: c000717f Table: 33850000 DAC: 00000015
Process 26th_segmentfau (pid: 813, stack limit = 0xc3fca258)
//发生错误时,进程名称为26th_segmentfault
Stack: (0xc3fcbe80 to 0xc3fcc000) //栈信息,从栈底0xc3fcbe80到栈顶0xc3fcc000
be80: c06d7660 c3e880c0 c3fcbebc c3fcbe98 c008d888 bf000010 00000000 c04df960
bea0: c3e880c0 c008d73c c0474e20 c3fb9534 c3fcbee4 c3fcbec0 c0089e48 c008d74c
bec0: c04df960 c3fcbf04 00000003 ffffff9c c002c044 c380a000 c3fcbefc c3fcbee8
bee0: c0089f64 c0089d58 00000000 00000002 c3fcbf68 c3fcbf00 c0089fb8 c0089f40
bf00: c3fcbf04 c3fb9534 c0474e20 00000000 00000000 c3851000 00000101 00000001
bf20: 00000000 c3fca000 c04c90a8 c04c90a0 ffffffe8 c380a000 c3fcbf68 c3fcbf48
bf40: c008a16c c009fc70 00000003 00000000 c04df960 00000002 be84ce38 c3fcbf94
bf60: c3fcbf6c c008a2f4 c0089f88 00008588 be84ce84 00008718 0000877c 00000005
bf80: c002c044 4013365c c3fcbfa4 c3fcbf98 c008a3a8 c008a2b0 00000000 c3fcbfa8
bfa0: c002bea0 c008a394 be84ce84 00008718 be84ce30 00000002 be84ce38 be84ce30
bfc0: be84ce84 00008718 0000877c 00000003 00008588 00000000 4013365c be84ce58
bfe0: 00000000 be84ce28 0000266c 400c98e0 60000010 be84ce30 30002031 30002431
Backtrace: //回溯信息
[<bf000000>] (first_drv_open+0x0/0x12c [26th_segmentfault]) from [<c008d888>] (chrdev_open+0x14c/0x164)
r5:c3e880c0 r4:c06d7660
[<c008d73c>] (chrdev_open+0x0/0x164) from [<c0089e48>] (__dentry_open+0x100/0x1e8)
r8:c3fb9534 r7:c0474e20 r6:c008d73c r5:c3e880c0 r4:c04df960
[<c0089d48>] (__dentry_open+0x0/0x1e8) from [<c0089f64>] (nameidata_to_filp+0x34/0x48)
[<c0089f30>] (nameidata_to_filp+0x0/0x48) from [<c0089fb8>] (do_filp_open+0x40/0x48)
r4:00000002
[<c0089f78>] (do_filp_open+0x0/0x48) from [<c008a2f4>] (do_sys_open+0x54/0xe4)
r5:be84ce38 r4:00000002
[<c008a2a0>] (do_sys_open+0x0/0xe4) from [<c008a3a8>] (sys_open+0x24/0x28)
[<c008a384>] (sys_open+0x0/0x28) from [<c002bea0>] (ret_fast_syscall+0x0/0x2c)
Code: bf000094 bf0000b4 bf0000d4 e5952000 (e5923000)
Segmentation fault

驱动程序出错,会将寄存器的一些值打印出来。在内核出现段错误时,内核会打印出一大堆信息,但是在应用程序中发生段错误时,并不会打印那些信息。本篇博客我们就来探讨这个问题。当在应用程序中发现段错误时,通过修改或配置内核,打印出尽可能多的信息。
2.到内核源码中搜索:Unable to handle kernel
cd arch/arm
grep -nr "Unable to handle kernel " *
通过搜索发现,在Fault.c中:
__do_kernel_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/*
* Are we prepared to handle this kernel fault?
*/
if (fixup_exception(regs))
return;
/*
* No handler, we'll have to terminate things with extreme prejudice.
*/
bust_spinlocks(1);
printk(KERN_ALERT
"Unable to handle kernel %s at virtual address %08lx\n",
(addr < PAGE_SIZE) ? "NULL pointer dereference" :
"paging request", addr);
show_pte(mm, addr);
die("Oops", regs, fsr);
bust_spinlocks(0);
do_exit(SIGKILL);
}
在__do_kernel_fault函数中被打印出来,__do_kernel_fault又是在哪被调用的呢?
在Fault.c中的do_bad_area函数中被调用,如下所示:
void do_bad_area(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk = current;
struct mm_struct *mm = tsk->active_mm;
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
if (user_mode(regs))
__do_user_fault(tsk, addr, fsr, SIGSEGV, SEGV_MAPERR, regs);
else
__do_kernel_fault(mm, addr, fsr, regs);
}
进入__do_user_fault函数中,看看有没有相关的打印信息:
static void
__do_user_fault(struct task_struct *tsk, unsigned long addr,
unsigned int fsr, unsigned int sig, int code,
struct pt_regs *regs)
{
struct siginfo si;
#ifdef CONFIG_DEBUG_USER
if (user_debug & UDBG_SEGV) {
printk(KERN_DEBUG "%s: unhandled page fault (%d) at 0x%08lx, code 0x%03x\n",
tsk->comm, sig, addr, fsr);
show_pte(tsk->mm, addr);
show_regs(regs);
}
#endif
}
在__do_user_fault中有打印信息,不过还需要做以下几件工作:
(1)配置内核,设置变量CONFIG_DEBUG_USER;
在make menuconfig里搜索DEBUG_USER,如下图所示:

重新编译内核,烧写
(2)设置user_debug
#ifdef CONFIG_DEBUG_USER
unsigned int user_debug;
static int __init user_debug_setup(char *str)
{
get_option(&str, &user_debug);
return 1;
}
__setup("user_debug=", user_debug_setup);
#endif
user_debug的初始值为0,因此就不会打印任何东西。那我们如何去设置这个变量呢?
__setup("user_debug=", user_debug_setup)
bootloader在启动内核的时候,会传入一些参数。
set bootargs console=ttySAC0 user_debug=0xff
显然当uboot传递进来的命令行字符里含有"user_debug="时,便会调用user_debug_setup()->get_option(),最终会将"user_debug="后面带的字符串提取给user_debug变量.
比如:当命令行字符里含有"user_debug=0xff"时,则user_debug变量等于0xff
(3)UDBG_SEGV 是什么,搜索后发现是一个宏:#define UDBG_SEGV (1 << 3) //UDBG_SEGV表示bit3
#define UDBG_UNDEFINED (1 << 0) //用户态的代码出现未定义指令(UNDEFINED)
#define UDBG_SYSCALL (1 << 1) //用户态系统调用已过时(SYSCALL)
#define UDBG_BADABORT (1 << 2) //用户态数据错误已中止(BADABORT)
#define UDBG_SEGV (1 << 3) //用户态的代码出现段错误(SEGV)
#define UDBG_BUS (1 << 4) //用户态访问忙(BUS)
从上面的定义分析得出,我们只需要将user_debug设为0xff,上面的所有条件就都成立.
比如:当用户态的代码出现段错误时,由于user_debug bit3=1,所以打印出oops.
3.试验
使用新的内核以及重新设定启动参数,进行试验
如下图所示,执行错误的应用程序,只打印了各个寄存器值,以及函数调用关系,而没有栈信息:
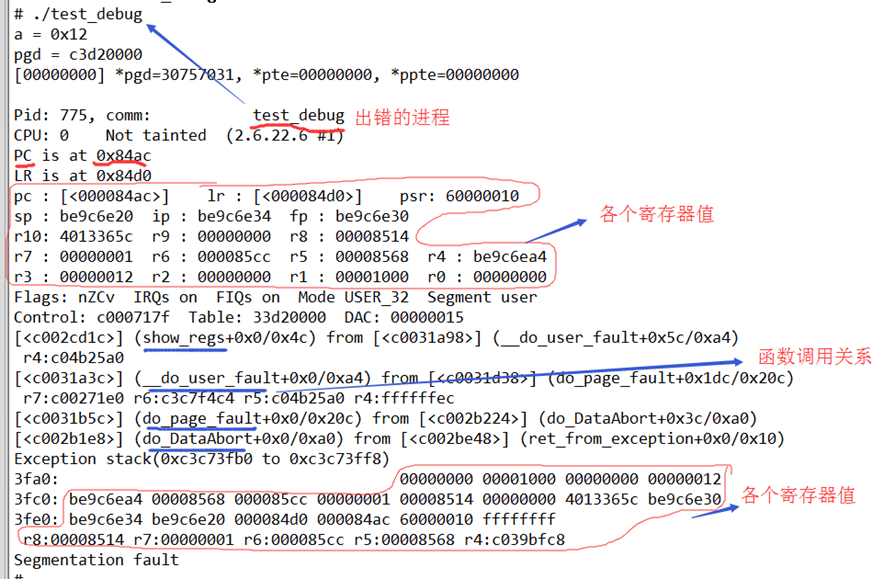
我感觉这种调试没有什么用,完全可以用gdb去解决。这仅仅是一种方法而已。
4.接下来,继续修改内核,使应用程序的oops也打印栈信息出来
4.1在驱动的oops里有"Stack: "这个字段,搜索"Stack: "看看,位于哪个函数
cd arch/arm/
grep -nr "Stack" *
你会发现在traps.c文件中,如下所示:
static void __die(const char *str, int err, struct thread_info *thread, struct pt_regs *regs)
{
struct task_struct *tsk = thread->task;
static int die_counter;
printk("Internal error: %s: %x [#%d]" S_PREEMPT S_SMP "\n",
str, err, ++die_counter);
print_modules();
__show_regs(regs);
printk("Process %s (pid: %d, stack limit = 0x%p)\n",
tsk->comm, tsk->pid, thread + 1);
if (!user_mode(regs) || in_interrupt()) {
dump_mem("Stack: ", regs->ARM_sp,
THREAD_SIZE + (unsigned long)task_stack_page(tsk));
dump_backtrace(regs, tsk);
dump_instr(regs);
}
}
这个__die()会被die()调用,die()又会被__do_kernel_fault()调用,而我们应用程序调用的__do_user_fault()里没有die()函数,所以没有打印出Stack栈信息
上面的dump_mem():
dump_mem("Stack: ", regs->ARM_sp,THREAD_SIZE + (unsigned long)task_stack_page(tsk)); //打印stack栈信息
主要是通过sp寄存器里存的栈地址,每打印一个栈地址里的32位数据, 栈地址便加4(一个地址存8位,所以加4)。
接下来我们便通过这个原理,来修改应用程序调用的__do_user_fault()
4.2在__do_user_fault(),添加以下带红色的字:
static void
__do_user_fault(struct task_struct *tsk, unsigned long addr,
unsigned int fsr, unsigned int sig, int code,
struct pt_regs *regs) /*发生错误时,结构体pt_regs中包含有发生错误的瞬间各个寄存器的值。现在想把栈打印出来,这个栈可以从寄存器中得到*/
{
struct siginfo si;
unsigned long val ;
int i=0;
#ifdef CONFIG_DEBUG_USER
if (user_debug & UDBG_SEGV) {
printk(KERN_DEBUG "%s: unhandled page fault (%d) at 0x%08lx, code 0x%03x\n",
tsk->comm, sig, addr, fsr);
show_pte(tsk->mm, addr);
show_regs(regs);
printk("Stack: \n");
while(i<1024) /*打印1k*/
{
/* copy_from_user()只是用来检测该地址是否有效,如有效,便获取地址数据,否则break */
/*如果copy_from_user返回0表示正确,否则错误*/
if(copy_from_user(&val, (const void __user *)(regs->ARM_sp+i*4), 4)) /*每次拷4个字节*/
break;
printk("%08x ",val); //打印数据
i++;
if(i%8==0) /换行/
printk("\n");
}
printk("\n END of Stack\n");
}
#endif
tsk->thread.address = addr;
tsk->thread.error_code = fsr;
tsk->thread.trap_no = 14;
si.si_signo = sig;
si.si_errno = 0;
si.si_code = code;
si.si_addr = (void __user *)addr;
force_sig_info(sig, &si, tsk);
}
栈的打印是从底往上打印。
5.重新烧写内核,试验
如下图所示:

接下来,便来分析PC值,Stack栈,到底如何调用的
6.首先来分析PC值,确定错误的代码
1)生成反汇编:
arm-linux-objdump -D test_debug > test_debug.dis
2)搜索PC值84ac,如下图所示:

从上面看出,主要是将0x12(r3)放入地址0x00(r2)中
而0x00是个非法地址,所以出错
7.分析Stack栈信息,确定函数调用过程
7.1分析过程中,遇到main()函数的返回地址为:LR=40034f14
内核的虚拟地址是c0004000~c03cebf4,而反汇编里也没有该地址,所以这是个动态库的地址.
需要用到静态链接方法,接下来重新编译,反汇编,运行:
#arm-linux-gcc -o -static test_debug test_debug.c
//-static 静态链接,生成的文件会非常大, 好处在于不需要动态链接库,也可以运行
#arm-linux-objdump -D test_debug > test_debug.dis
7.2最终, 找到main()函数的返回地址在__lobc_start_main()里
__lobc_start_main()->
main()->
A()->
B()->
C() //将0x12(r3)放入地址0x00(r2)中
参考原文博客:https://www.cnblogs.com/lifexy/p/8045191.html