概述
编辑距离(Minimum Edit Distance,MED),由俄罗斯科学家 Vladimir Levenshtein 在1965年提出,也因此而得名 Levenshtein Distance。
在信息论、语言学和计算机科学领域,Levenshtein Distance 是用来度量两个序列相似程度的指标。通俗地来讲,编辑距离指的是在两个单词<W1,W2 >之间,由其中一个单词W1转换为另一个单词W2 所需要的最少单字符编辑操作次数。
在这里定义的单字符编辑操作有且仅有三种:
- 插入(Insertion)
- 删除(Deletion)
- 替换(Substitution)
譬如,"kitten" 和 "sitting" 这两个单词,由 "kitten" 转换为 "sitting" 需要的最少单字符编辑操作有:
1.kitten → sitten (substitution of "s" for "k")
2.sitten → sittin (substitution of "i" for "e")
3.sittin → sitting (insertion of "g" at the end)
因此,"kitten" 和 "sitting" 这两个单词之间的编辑距离为 3 。
形式化定义

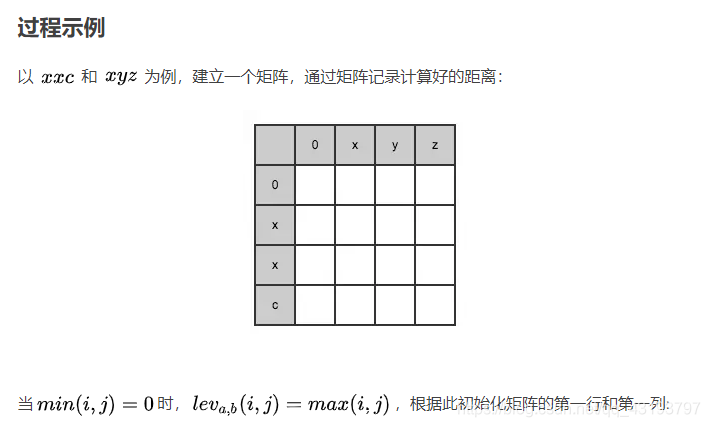
第一行(index = 0)初始化:
min(0, 0) = 0 -> lev_{a, b}(0, 0) = max(0, 0) = 0
min(0, 1) = 0 -> lev_{a, b}(0, 1) = max(0, 1) = 1
min(0, 2) = 0 -> lev_{a, b}(0, 2) = max(0, 2) = 2
min(0, 3) = 0 -> lev_{a, b}(0, 3) = max(0, 3) = 3
第一列(index = 0)初始化:
min(0, 0) = 0 -> lev_{a, b}(0, 0) = max(0, 0) = 0
min(1, 0) = 0 -> lev_{a, b}(1, 0) = max(1, 0) = 1
min(2, 0) = 0 -> lev_{a, b}(2, 0) = max(2, 0) = 2
min(3, 0) = 0 -> lev_{a, b}(3, 0) = max(3, 0) = 3 


算法实现
1 递归方式
def Levenshtein_Distance_Recursive(str1, str2):
if len(str1) == 0:
return len(str2)
elif len(str2) == 0:
return len(str1)
elif str1 == str2:
return 0
if str1[len(str1)-1] == str2[len(str2)-1]:
d = 0
else:
d = 1
return min(Levenshtein_Distance_Recursive(str1, str2[:-1]) + 1,
Levenshtein_Distance_Recursive(str1[:-1], str2) + 1,
Levenshtein_Distance_Recursive(str1[:-1], str2[:-1]) + d)
print(Levenshtein_Distance_Recursive("abc", "bd"))
>>>
2
2 动态规划
递归是从后向前分解,那与之相对的就是从前向后计算,逐渐推导出最终结果,此法被称之为动态规划,动态规划很适用于具有重叠计算性质的问题,但这个过程中会存储大量的中间计算的结果,一个好的动态规划算法会尽量减少空间复杂度。
def Levenshtein_Distance(str1, str2):
"""
计算字符串 str1 和 str2 的编辑距离
:param str1
:param str2
:return:
"""
matrix = [[ i + j for j in range(len(str2) + 1)] for i in range(len(str1) + 1)]
for i in range(1, len(str1)+1):
for j in range(1, len(str2)+1):
if(str1[i-1] == str2[j-1]):
d = 0
else:
d = 1
matrix[i][j] = min(matrix[i-1][j]+1, matrix[i][j-1]+1, matrix[i-1][j-1]+d)
return matrix[len(str1)][len(str2)]
print(Levenshtein_Distance("abc", "bd"))
>>>
2
应用与思考
编辑距离是NLP基本的度量文本相似度的算法,可以作为文本相似任务的重要特征之一,其可应用于诸如拼写检查、论文查重、基因序列分析等多个方面。但是其缺点也很明显,算法基于文本自身的结构去计算,并没有办法获取到语义层面的信息。
由于需要利用矩阵,故空间复杂度为O(MN)。这个在两个字符串都比较短小的情况下,能获得不错的性能。不过,如果字符串比较长的情况下,就需要极大的空间存放矩阵。例如:两个字符串都是20000字符,则 LD 矩阵的大小为:20000 * 20000 * 2=800000000 Byte=800MB。
作者:TSW1995
链接:https://www.jianshu.com/p/a617d20162cf
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
