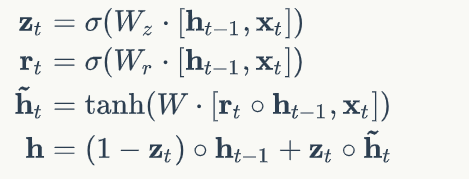SE-Net
在通道方向上的注意力机制
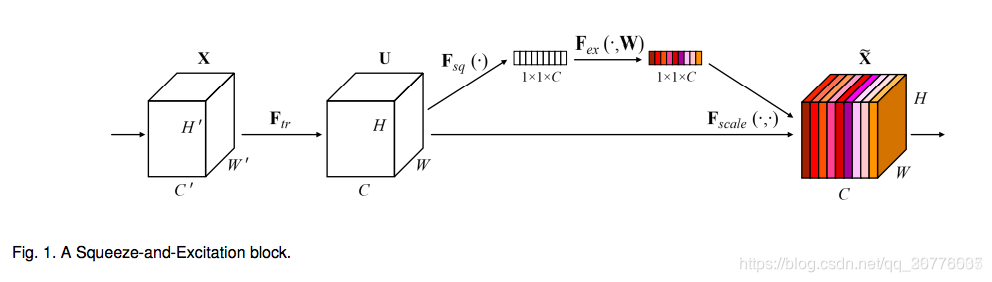
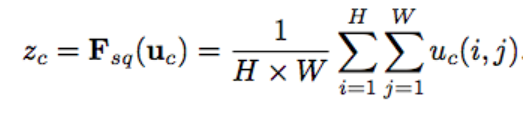
- 流程
首先对图片进行卷积运算,然后对于feature map进行global average pooling(squeeze),把它变成1x1xC的向量,然后通过两层FC(excitation),乘以它初始的feature map,作为下一级的输入。 - 为啥加两个FC
加上两个FC的原因是,如果他只对feature map做pooling,只是对当前的image的scale做了处理,但是真实的scale是整个数据集的scale,所以要加上FC,让他适应于整个数据集。 - 如何压缩参数
第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。 - 作用深度
在早期的层中,它以一种与类无关的方式激发feature,从而增强了共享的底层表示。后面较深的层中逐渐趋于无效。
FCN
- 卷积化
把最后一层的全连接换成卷积层,输出的即为H’xW’的heatmap
像素级别的分类 - 上卷积
把feature大小恢复到原图片大小以供分割 - 跳跃结构 skip layers
因为最后一层pooling之后损失了很多信息,把前几层的pooling后的特征图拿过来补充
RNN Recurrent Neural Network
前向传播
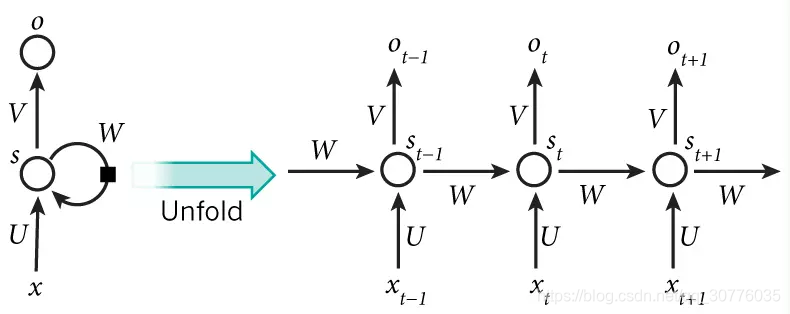
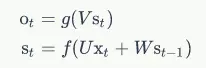
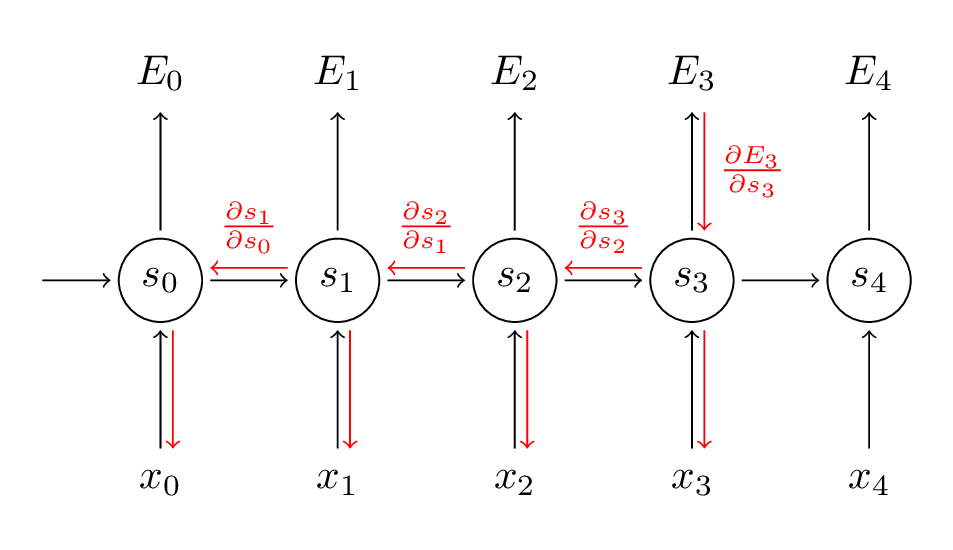
BPTT bp through time
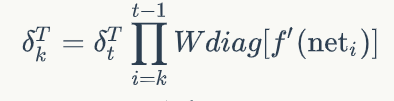
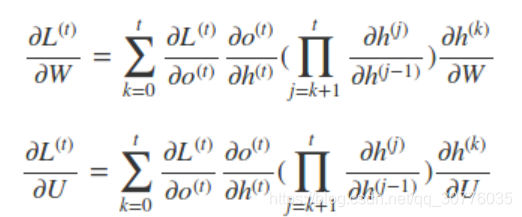
RNN 短时记忆问题
反向回传的时候一直×w矩阵
在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W*激活函数导数. 如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing. 反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做梯度爆炸, 这就是普通 RNN 没有办法回忆起久远记忆的原因.
如何解决梯度爆炸
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。原理请参考上一篇文章零基础入门深度学习(4) - 卷积神经网络的激活函数一节。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。我们将在以后的文章中介绍这两种网络。
参考资料:
实现
详解
Long Short Term Memory networks 长短时记忆网络
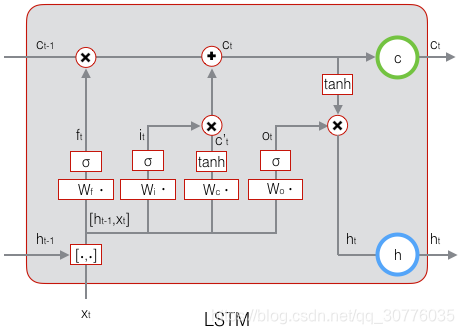
遗忘门
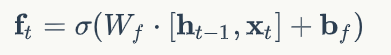
输入门
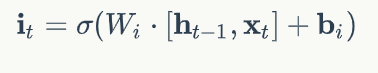
输出门
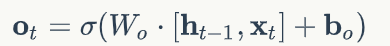
当前输入的状态计算:

当前状态计算:
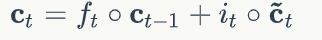
最终输出:

GRU
Gated Recurrent Unit
在LSTM基础上 只设置重置门(Reset Gate
)和更新门(Update Gate
)
单元状态和输出合成为一个