抖音视频下载爬虫编写的完整过程!爬取app的过程
工具:
charles(类似fiddler) chrome debug调试台 jupyter notebook
分析APP情况
准备好charles的手机ssl证书,设置好代理启动charles开始抓取抖音app数据。经过分析可以看到如下结果 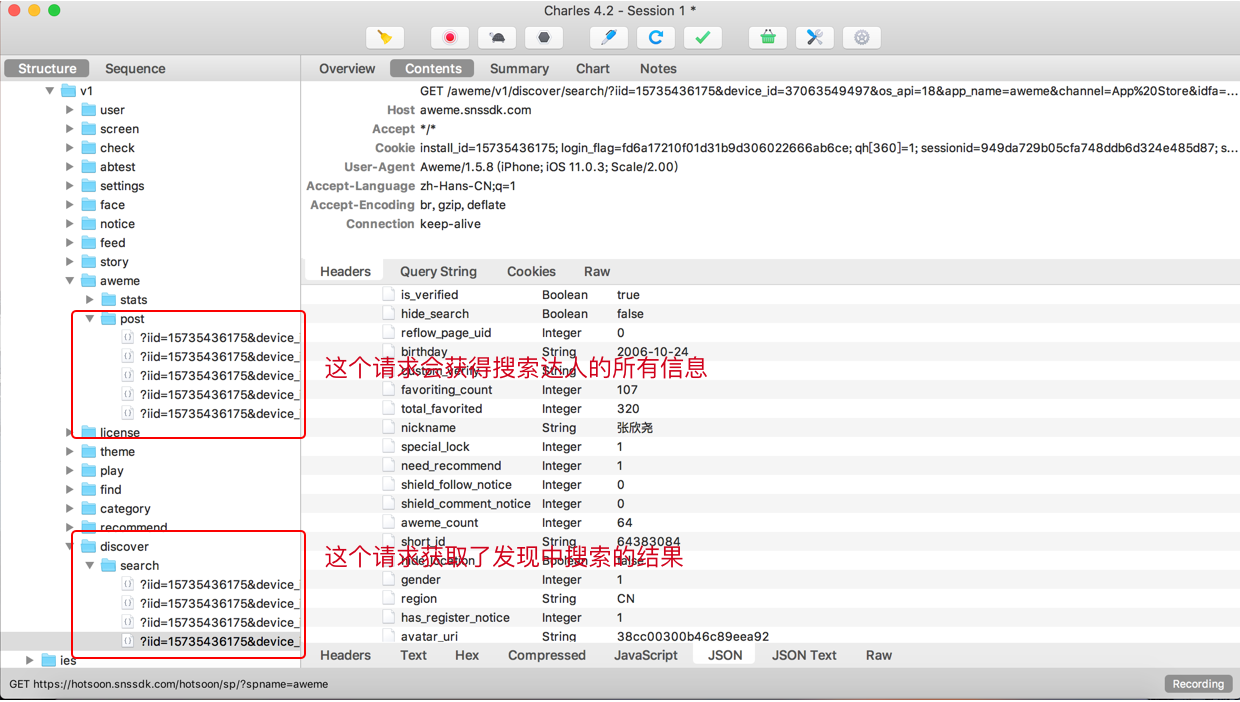
可以获得两个get请求!
https://aweme.snssdk.com/aweme/v1/discover/search/?iid=15735436175&device_id=37063549497&os_api=18&app_name=aweme&channel=App%20Store&idfa=08621BB7-65C3-454D-908A-D02F565D85F1&device_platform=iphone&build_number=15805&vid=6BD753D7-C89A-4BEF-9C3D-7192E26CF330&openudid=ee5f41b63ff4704166b2f2d8920267fcd109136b&device_type=iPhone6,2&app_version=1.5.8&version_code=1.5.8&os_version=11.0.3&screen_width=640&aid=1128&ac=WIFI&count=10&cursor=0&keyword=关键词&type=1&cp=9646915915dce7fbe1&as=a115d95e314449fffd&ts=时间戳
https://aweme.snssdk.com/aweme/v1/aweme/post/?iid=15735436175&device_id=37063549497&os_api=18&app_name=aweme&channel=App%20Store&idfa=08621BB7-65C3-454D-908A-D02F565D85F1&device_platform=iphone&build_number=15805&vid=6BD753D7-C89A-4BEF-9C3D-7192E26CF330&openudid=ee5f41b63ff4704166b2f2d8920267fcd109136b&device_type=iPhone6,2&app_version=1.5.8&version_code=1.5.8&os_version=11.0.3&screen_width=640&aid=1128&ac=WIFI&count=视频数量&max_cursor=0&min_cursor=0&user_id=用户ID&cp=e7329b5ccceae5cbe1&as=a125ee5e8cd3393c4e&ts=时间戳
#以上链接进行了处理以便不能直接访问。
大体逻辑是通过搜索获得用户名列表,在判断用户名列表是不是想要的那位达人,获取他的user_id、count,然后通过第二链接获得用户的分享链接,再通过分享链接页面爬取视频。
编写代码
class DouYin(object):
def __init__(self):
print(sys.getdefaultencoding(),"抖音下载!")
#urllib3连接错误时抛出exceptions.SSLError
http = urllib3.PoolManager(cert_reqs = 'CERT_REQUIRED', ca_certs = certifi.where())
#获得总分享视频url地址,返回视频名字,视频数,分享视频链接列表
def get_video_url(self,nickname):
video_name = []
video_urls = []
user_agent = 'Aweme/1.5.8 (iPhone; iOS 11.0.3; Scale/2.00)'
header = {'User-Agent':user_agent}
search_url = "https://aweme.snssdk.com/aweme/v1/discover/search/?iid=15735436175&device_id=37063549497&os_api=18&app_name=aweme&channel=App%20Store&idfa=08621BB7-65C3-454D-908A-D02F565D85F1&device_platform=iphone&build_number=15805&vid=6BD753D7-C89A-4BEF-9C3D-7192E26CF330&openudid=ee5f41b63ff4704166b2f2d8920267fcd109136b&device_type=iPhone6,2&app_version=1.5.8&version_code=1.5.8&os_version=11.0.3&screen_width=640&aid=1128&ac=WIFI&count=10&cursor=0&keyword={0}&type=1&cp=9646915915dce7fbe1&as=a115d95e314449fffd&ts={1}".format(quote(nickname),int(time.time()))
print(search_url)
req = http.request('GET',search_url)
html = json.loads(req.data.decode('utf-8'))
for each in html['user_list']:
if each['user_info']['nickname'] == nickname:
aweme_count = each['user_info']['aweme_count']
user_id = each['user_info']['uid']
user_url = 'https://aweme.snssdk.com/aweme/v1/aweme/post/?iid=15735436175&device_id=37063549497&os_api=18&app_name=aweme&channel=App%20Store&idfa=08621BB7-65C3-454D-908A-D02F565D85F1&device_platform=iphone&build_number=15805&vid=6BD753D7-C89A-4BEF-9C3D-7192E26CF330&openudid=ee5f41b63ff4704166b2f2d8920267fcd109136b&device_type=iPhone6,2&app_version=1.5.8&version_code=1.5.8&os_version=11.0.3&screen_width=640&aid=1128&ac=WIFI&count={0}&max_cursor=0&min_cursor=0&user_id={1}&cp=e7329b5ccceae5cbe1&as=a125ee5e8cd3393c4e&ts={2}'.format(aweme_count,user_id,int(time.time()))
r = http.request('GET',user_url,headers = header)
htm = json.loads(r.data.decode('utf-8'))
for each in htm['aweme_list']:
share_desc = each['share_info']['share_desc']
if '抖音-原创音乐短视频社区' == share_desc:
print(each)
video_names.append(each[cha_list][0]['cha_name']+'.mp4')
else:
video_names.append(share_desc+'.mp4')
video_url.append(each['share_info']['share_url'])
return video_names,video_urls,aweme_count
#获得下载视频地址
def get_download_url(self,video_url):
#video_url = 'https://www.douyin.com/share/video/6479379598709624078/?region=CN&mid=6477398356422789901'
req = http.request('GET',video_url).data.decode('utf-8')
video_url_data = re.findall('var data = \[(.*?)\];', str(req))[0]
video_html = json.loads(video_url_data)
download_url = video_html['video']['real_play_addr']
return download_url
#下载视频
def vedio_download(self,video_name,video_url):
size = 0
with closing(http.request('GET',video_url,preload_content=False)) as response:
chunk_size = 1024
content_size =int(response.headers['content-length'])
if response.status == 200:
print('[文件大小]:%0.2f MB' % (content_size / chunk_size / 1024))
with open(filename,'wb') as file:
for data in response.stream(chunk_size):
file.write(data)
size +=len(data)
file.flush()
sys.stdout.flush()
response.release_conn()
def run(self,nickname):
vedio_names, video_urls, aweme_count = self.get_video_url(nickname)
if nickname not in os.listdir():
os.mkdir(nickname)
print("视频下载中:\n")
for num in range(aweme_count):
video_url = self.get_download_url(video_url[num])
self.video_download(video_names[num],video_url)
if __name__ == '__main__':
douyin =DouYin()
nickname = r'王同学'
douyin.run(nickname)
浏览器老是崩溃,更多参考详情我的博客吧https://www.nigaea.com/dataanalysis/170.html
