一、HashMap底层原理
1. 默认加载因子(loadFactor) 0.75,为什么?
- 何时扩容:当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容。
- 为什么非要0.75?过高会导致更多哈希碰撞,过低会导致空间利用率低。根据源码注释来看,节点在hash桶中的分布大致遵循泊松分布,在加载因子为0.75时,每个碰撞位置链表长度超过8个的概率便小于千万分之一。
2.链表转红黑树的阈值=8,为什么?
- 和加载因子的原因相同,因为在加载因子=0.75时,长度为8以上的几率非常的低。而在8个以下,其实链表和红黑树时间相差并不多,转换为树也要耗时,所以在小于8时没有转换的必要。
- 同时要注意,如果数组的长度小于
MIN_TREEIFY_CAPACITY(默认64),那么此时如果达到阈值,不会转为红黑树,而是会扩容。 - 当红黑树的节点数小于6时,又会转为链表
3.初始容量为什么必须是2的指数次幂?
- Java7中,在put操作时,如果数组为空,则会调用inflateTable(),在里面会把传入的容量大小转化为2的指数次幂,向上取。
- 原因:HashMap将哈希值转化为数组下标的操作是通过位运算,来达到取模的效果。为此,长度必须为2的指数次幂,否则会发生数组越界以及哈希碰撞。
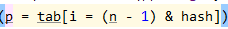
4.结构:数组+链表+红黑树
- 数组:查找非常快,只需O(1);但是插入和删除为O(n)。
- 链表:插入删除只需O(1),查询需要O(n)。
- 红黑树:查找、插入、删除,最坏情况下也为O(logn)。
5.HashMap线程不安全
- jdk1.7中,在高并发场景下,多线程扩容,导致链表可能形成环。因为链表插入时采用头部插入,所以在扩容时,链表的顺序会倒转,而一旦两个线程同时开始扩容,一个线程已经完成扩容,而另一个线程以为扩容未完成而继续,此时就会发生链表形成一个环。同样的,put时也会发生的更新丢失问题。
- jdk1.8采用从尾部插入节点的方式,并且扩容方式改变,链表不会再形成环了,但是依然会造成更新丢失。
6.JDK1.8新的扩容方式

对于一个链表中的多个节点,首先将它们分裂为两个新的链表,一个是高位、一个是低位。其中hiHead、hiTail是高位链表的头尾节点;loHead、loTail是低位链表的头尾节点。判断高低位的依据就是:将hash值与原数组oldCap长度相与,最终结果要么为0,要么为oldCap。为0判断为低位,为oldCap判断为高位。
最后,将低位链表放到新数组中原来的位置,即newTab[j],高位链表放到新数组中newTab[j+oldCap]的位置。这么做可以做到基本上均分链表,因为随机性。这么做可行的原因也是因为每乘2就多一位,而这一位就起着决定性的作用。
二、ConcurrentHashMap
1.Hashtable
Hashtable为保证线程安全,在每个方法上都用synchronized修饰,从而锁住整个对象保证安全,但是效率太低。
2.分段锁
将锁的粒度细化,将整个数组分为多个段,每个段用一把锁,就可以使效率提升。JDK1.7中,Concurrent默认段的大小为16
