语义分割算法汇总
记录一下各类语义分割算法,便于自己学习。
由DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation开始,在文章中,作者说明了在Cityscapes test set上各类模型的表现。如下图所示:
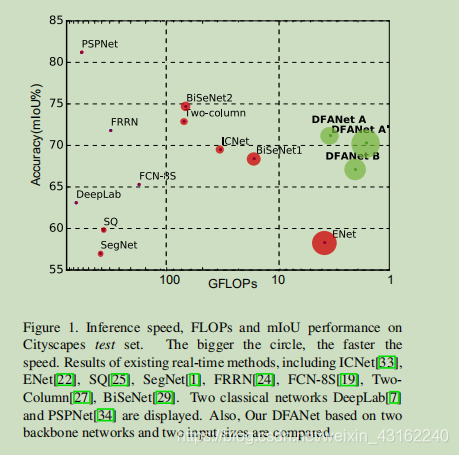
1.DFANet
文章梳理了语义分割网络中常见的模型,如下图所示
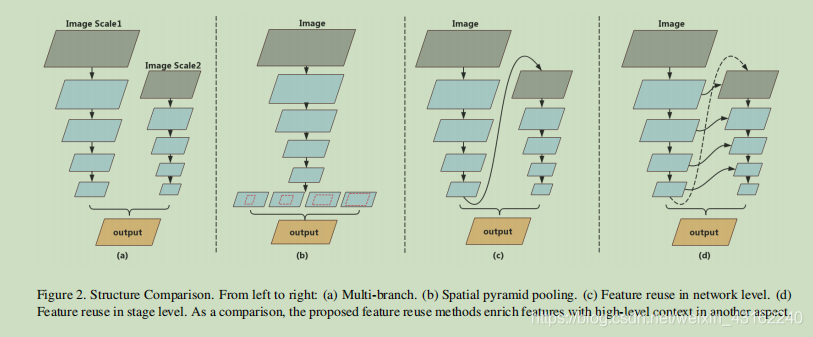
(a)这种模型可以获取多尺度的特征,并且保留空间信息。但是,它在处理High level feature时的效果不够好,因为它没有应用卷积来融合特征;同时,在高分辨率的那个分支上限制了模型的速度。
(b)语义分割中,金字塔池化是处理High level feature的常用的方法,然而金字塔池化在速度上会极大消耗资源。
©feature maps通过对网络输出进行上采样并用另一个子网络优化特征映射来替换High level feature,在高分辨率与子像素细节上同时进行学习,可以获得更多细节信息。然而,由于特征流是单一的,随着整个结构深度的增加,高维特征和感受场通常会使得精确损失。
(d)基于以上方法,文章提出一种层级别的方法,将low-level features与空间信息传给语义理解。因为所有的网络结构相似,可以连接所有相同分辨率的层,获得不同层级的信息。
DFANet网络结构图
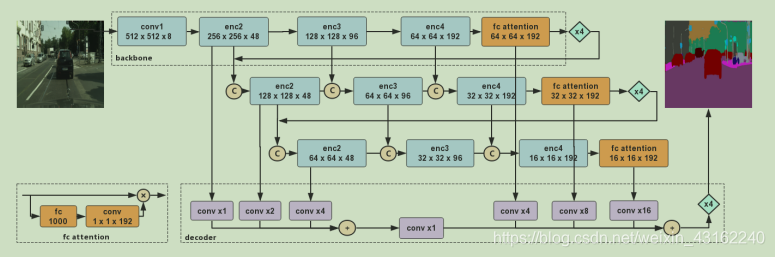
backbone
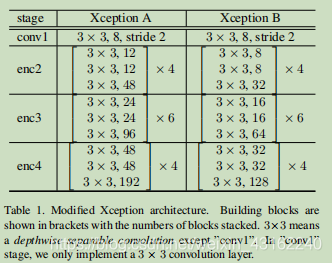
通常语义分割模型都会选择预训练模型作为编码模块,通常有 ResNet, Xception, DenseNet等,DFANet选择了一种计算量更小的模型作为backbone(修改后的Xception),并且探究了怎么才能在限制计算量的情况下提升模型表现能力。
由于网络越深,细节丢失越多,从网络结构图可以看到DFA网络综合了模型连接与层级连接方式来避免这个问题,模型中采用了三个backbone的连接。最后在xception的全连接层之后接一个1*1的卷积层递归通道数,去匹配Xception的backbone的feature map。
decoder
文章直接将高级特征与之前的细节部分融合,然后高级特征进行4倍双线性上采样,每个backbone的层级的输出的与其他backbone有相同分辨率的部分进行融合,然后高级特征与细节都在最后的结果中展现,这时候再进行4倍上采样,得到最后的预测结果。
2.PSPNet
PSP网络结构
pspnet的网络结构图如下:
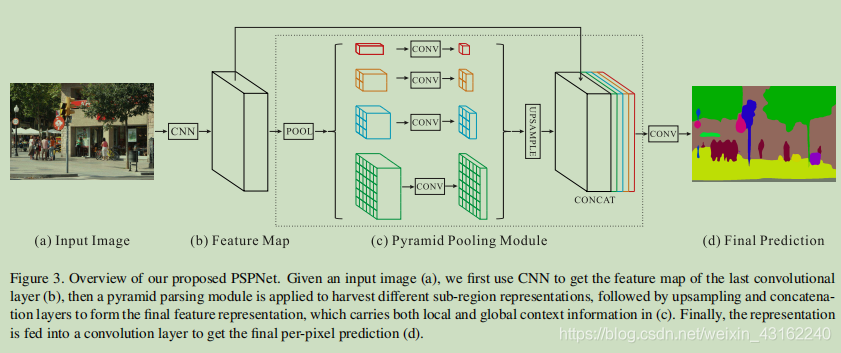
网络结构为:
- CNN(这里用的是resnet)提取出抽象特征
- (重点)经过金字塔池化层,获得四个不同尺度的信息,然后再用1*1卷积综合各个通道的信息,这里我个人理解就是远看一个物体与近看一个物体会获得不同的结果,全局池化即上图中红色的块产生的效果类似远看一个物体获得的信息,而后面的就是越来越近的看一个物体获得的信息。
- 上采样,这里对每个尺度池化结果做双线性上采样,到feature map的大小(缩小1/8)
- 将不同尺度的信息结合,对不同尺度的结果做concanate
- 上采样,并输出结果,这里上采样经过了三次,一次放大两倍,最终将feature map大小的结果还原为原图大小(图中没有展示出来,代码中是这样做的)。
PSP解决的问题
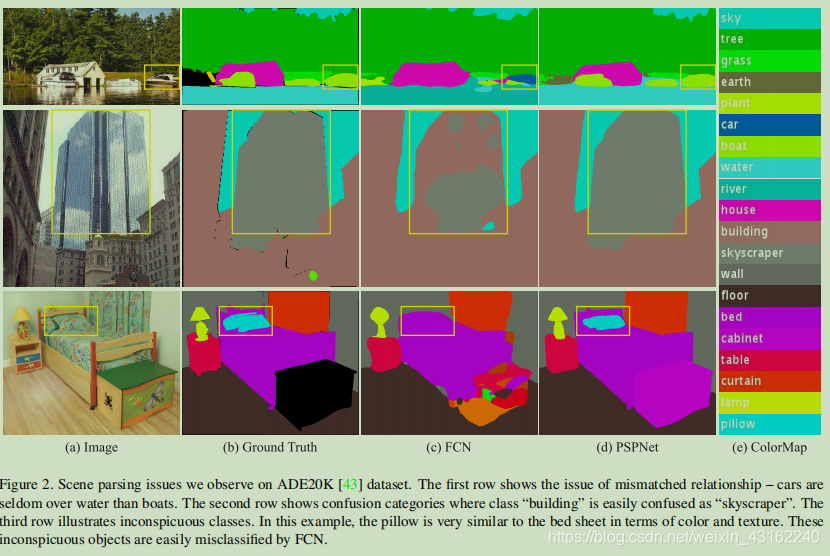
在上图第一行图片中,模型没有考虑到物体之间的联系(空间信息丢失,车几乎不会在水上),FCN将船预测为了车。第二行,FCN产生了分类混淆的情况,建筑的镜面反射使得墙体被分类为天空。第三行图片中,FCN无法很好的识别小物体,没能将枕头识别出来。
PSP网络结合不同尺度的信息可以解决以上FCN的不足。
3.BiSenet
网络结构
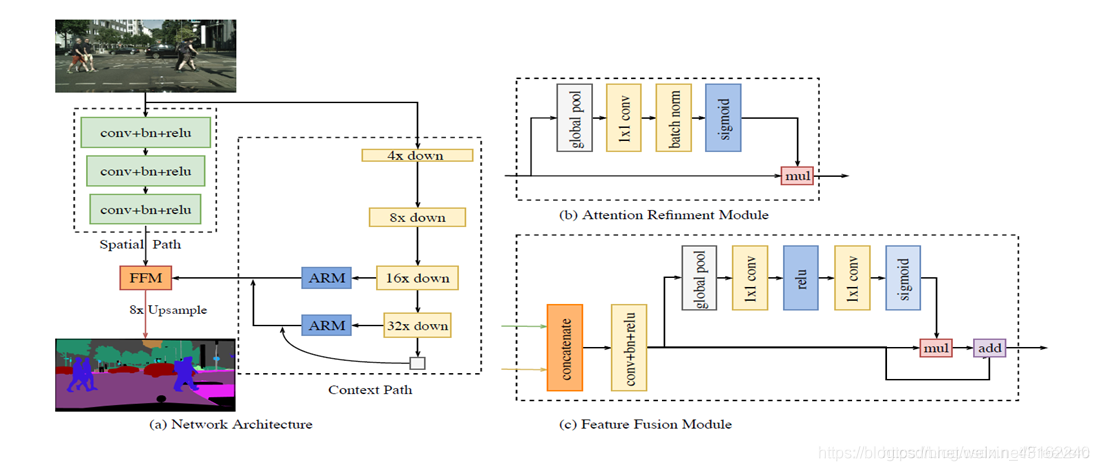
BiSenet网络最突出的特点就是应用了双向网络(图中的Spatial path与Context path),在语义分割中,最难的两个点,一个是感受野(Receptive field)的大小,另一个是空间信息(Spatial information)。一般网络越深,感受野越大,空间信息丢失越多。
通过三个卷积提取特征,保留了空间信息,同时Context path快速下采样,使得感受野变大,最后再融合两种特征后经过上采样就可以得到结果。
