Python基础(三)--序列
1 序列相关的概念
1.1 什么是序列
序列是一种可迭代对象,可以存储多个数据,并提供数据的访问。
序列中的数据称为元素,Python内置的序列类型有:列表(list),元组(tuple),字符串(str),字节(bytes)。
1.2 序列支持的通用操作
(1)索引:通过索引可以访问序列中指定位置的单个元素
(2)切片:通过切片可以访问序列中一个区间的多个元素
(3)迭代:因为序列是可迭代对象,所以可以通过for循环进行遍历
(4)长度:可以通过len函数获取序列的长度,即序列中含有元素的个数
(5)运算:序列支持+,*,in,not in,比较,布尔运算符等
2 列表
2.1 什么是列表
列表是一种可变的序列类型。能够存储多个元素。
2.2 创建列表
定义列表非常简单,使用一对[]即可。例如:li=[],也可以定义非空的列表,元素之间使用逗号分隔,如:li = [1,2,3]。也可以使用列表推导式创建列表,在下面介绍。
注意:在Python中,列表中的元素也可以是不同的,如:li = [6.6,8,"people"]
del除了可以删除变量名,也可以用来删除列表的元素
del li:删除整个列表
del li[0]:删除列表中指定索引的元素
del[0:3]:删除列表中指定区间的元素
2.3 索引
(1)访问列表元素
列表定义好后,我们就可以通过索引来访问列表的元素,访问的方式为:列表名[索引值]
索引是从0开始编号的,最大索引值为列表的长度- 1,列表(序列)的长度可以通过len函数获得。
注意:在Python中,列表的索引也支持负值,表示倒数第n个位置。例如:li[-1]表示倒数第一个(最后一个)元素(假设li为列表类型)。列表的有效索引值区间为[-length, length - 1](length为列表的长度)。如果索引不在有效区间,将会产生错误。
列表是可变的序列类型,除了可以通过索引获取元素的值,也可以改变元素的值。
li1 = []
li2 = [1,2,3]
li3 = [6.6,8,"people"]
print(li1,li2,li3)
# 索引指的就是元素的下标,即元素的序号,从0开始
print(li3[0],li3[2])
# 索引也支持负数,-1代表倒数第1个元素,最后一个元素为-1
print(li3[-1],li3[-2])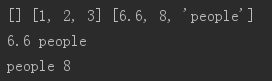
(2)列表的遍历
因为列表有索引,所以可以用while循环遍历
因为序列是可迭代对象,所以列表可以在for循环中进行遍历
index = 0
li = [6.6,8,"people"]
# while循环遍历
while index < len(li):
print(li[index],end=" ")
index += 1
# for循环遍历
print()
for item in li:
print(item,end=" ")
(3)列表的嵌套
列表是可以嵌套的,即列表中的元素依然是列表类型。
# 列表嵌套
li = [[1,2,3,4],[5,6,7,8]]
for item in li:
for i in item:
print(i,end=" ")![]()
2.4 切片
切片:用来操作列表(序列)一个区间的元素,语法为:
列表名[start : end : step]
start,end与step都是可选的,也可以都是负值。注意切片截取元素的方向。当两个端点同时存在,与两个端点缺失一个(或全部缺失),表现的不同。也可以通过切片修改列表的某一区间
# 切片语法:[start:end:step]
li = [6,8,12,5,66]
print(li[0:2],end=" ")
# 步长指定增量值
print(li[0:4:2])
# start,end,step是也可以是负值,如果切片的方向与增量的方向相反,则无法获取任何元素
print(li[-1:-3],end=" ")
print(li[-1:-3:-1],end=" ")
print(li[-3:-1])
# 省略start或者end,则此时切片没有方向,具体沿哪个方向切,取决于增量的方向
print(li[:3],end=" ")
print(li[3:],end=" ")
print(li[:3:-1],end=" ")
print(li[::1])
print("原来的列表:",li)
# 通过切片修改对应区间的元素
li[1:3] = [111,222,333]
print("修改对应区间后的列表:",li)
# 相当于删除指定区间的元素
li[3:4]=[]
print("删除对应区间后的列表:",li)
# 相当于插入元素
li[1:1] = [66,88]
print("插入元素后的列表:",li)
2.5 相关方法
| 方法名 | 描述 |
| append(obj) | 向列表末尾追加指定的元素 |
| insert(index,obj) | 第一个参数指定插入的位置(索引),第二个参数指定插入的值 |
| remove(value) | 删除列表中首次出现的元素(参数指定的元素),如果元素不存在会产生错误 |
| clear() | 清空整个列表,删除列表中的所有元素 |
| extend(iterable) | 将参数指定的列表或可迭代对象中所有的元素,追加到当前列表的尾部 |
| index(value,[start,[stop]]) | 返回参数指定的元素在当前列表中首次出现的位置,第二个参数可以指定查找的起始点,第三个参数可以指定查找的结束点。如果元素不存在,将会产生错误 |
| count(value) | 返回参数元素在列表中出现的次数 |
| copy() | 对列表进行浅拷贝,返回拷贝后的列表 |
| sort(key=None,reverse=False) | 对列表进行排序,默认升序,如果reverse为True,则进行降序排序 |
| reverse() | 对列表进行反转 |
| pop([index]) | 可以指定索引,删除并返回指定位置的索引 |
2.6 列表推导式
列表推导式是一种创建列表的简洁方式。
当我们需要创建的一个列表中的每个元素都是通过另一个列表或者可迭代对象中的每个元素或者部分元素,经过运算获得时,简而言之就是需要创建的列表元素完全依赖于另一个可迭代对象时,就可以考虑使用列表推导式。
列表推导式的语法为:
[表达式 for 更多的for或if]
注意:列表推导式中声明的变量仅在列表推导式中有效。for循环中的变量会在for循环后继续有效
# 列表推导式是创建列表的一种简介方式
# [对item进行的计算(含有item的表达式) for item in 原有的列表]
li = [6,8,66,88,100,120]
li2 = [item + 1 for item in li]
print(li2)![]()
2.6 赋值,浅拷贝与深拷贝
列表的内存存储:id函数
赋值:没有复制对象,仅仅是一个别名而言
浅拷贝:切片,列表的copy方法。copy模块的copy方法。浅拷贝仅仅拷贝当前的对象,对于对象内部所有管关联的洽谈对象则不会进行拷贝
深拷贝:copy模块的deepcopy方法。深拷贝不仅拷贝当前对象本身,当前对象内部所引用的可变对象,依然会进行递归拷贝。
# 赋值
li = [6,8,12]
print("原始列表",li)
li2 = li
li2[0] = 10
print("赋值操作",li)
# 浅拷贝
cli = [6,8,12]
li3 = cli.copy()
li3[0] = 10
# 因为列表元素是常量,不可变,所以不会影响原来的列表
print("浅拷贝1",cli)
cli2 = [[1,2],[3,4]]
import copy
cli3 = copy.copy(cli2)
cli3[0][0] = 100
# 因为列表是变量所以会影响到原来的列表
print("浅拷贝2",cli2)
# 深拷贝
dli = [6,8,12]
li4 = copy.deepcopy(dli)
li4[0] = 10
print("深拷贝",dli)
2.7 列表的运算
列表(序列)也是支持部分运算,因为列表可以包含多个元素,相比之前学习的数值类型(仅包含单个值)来说,其计算规则相对复杂一些。
| 符号 |
说明 |
| x + y |
连接x与y两个列表 |
| x * n |
将序列重复n次(所有元素重复n次)。 |
| e in x |
如果e在x中,返回True,否则返回False。 |
| e not in y |
如果e不在x中,返回True,否则返回False。 |
| x 比较 y |
依次比较两个序列中的元素(>,>=,<,<=,==,!=)。 判断两个列表是否为同一个列表(is,is not)。 |
| x 布尔 y |
与数值类型的布尔运算(and或or)规则相同(返回两个列表中的一个) |
3 元组
3.1 什么是元组
元组是一种不可变的序列。元组一但创建,就无法再进行修改,试图对元组进行的任何修改均会产生错误。
其实元组除了不可变性,元组与列表非常相似,可以近似的认为元组是一种不可变的列表类型
3.2 创建元组
元组使用()表示,多个元素使用逗号“,”分隔。但是,当元组仅有一个元素时,必须在元素后面加上逗号“,”,否则不是元组类型。
以下情况下元组必须使用():①长度为0的元素(空元组)②元组嵌套③元组作为表达式的一部分。但是为了增强可读性,使用元组时,总是使用()
3.2 基本操作
# 元素创建,
t = (1,)
print(type(t))
# 元组的切片与索引
t = (6,7,8,9,10)
print(t[0])
print(t[0:2])
print(t[-3:-1])
print(t[::-1])
# 元组的遍历
for i in t:
print(i,end=" ")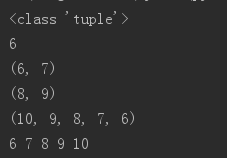
3.3 相关方法
因为元组是不可变的序列,因此所有修改序列的方法都不能使用。
| 方法名 | 描述 |
| count(value) | |
| index(value,[start,[stop]]) |
t = (6,7,8,9,10)
print(t.count(6))
print(t.index(8))
![]()
3.4 使用元组的意义
元组作为一种不可变序列,可以保证数据在程序运行过程中不会意外由自己或其他人修改(例如在函数参数传递中),这样可以保证数据的完整性。
4 字符串
4.1 字符串的定义
字符串是一种不可变的序列。就是一组字符组成的序列,每个字符就是序列中的一个元素
4.2 基本操作
(1)创建
字符串可以包含零个或多个字符,字符需要使用引号界定。引号可以是:①单引号②双引号③三引号
引号与双引号是完全等价的,而三引号可以在字符串内部换行。如果单(双)引号也需要换行,可以使用续行符“\”,三引号中使用续行符,则不会产生换行。
(2)索引,切片,运算,遍历等操作
# 单引号与双引号的区别在于:单引号与双引号不能换行显示,但是三引号可以
# 注意:三引号在python中不是多行注释,是python中的字符串
s = 'aaa'
s = "aaa"
s = '''aaa'''
s = """aaa"""
# 如果单引号或双引号需要换行,可以使用续航符\
s = "abc\
def"
# 切片与索引
s = "abcdefgh"
print(s[6])
print(s[0:6])
# 遍历
for i in s:
print(i,end=" ")
# 字符串是不可修改的
# s[0] = "b" 运行会报错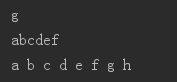
4.3 相关方法
| 方法名 | 描述 |
| count(sub[,start[,end]]) | 返回参数在字符串中出现的次数,可以指定开始点和结束点,如果没有指定结束点则一直到字符串的末尾 |
| find/index(sub[,start[,end]]) | 返回参数在字符串中首次出现的位置(索引),find参数不存在不会报错返回-1,index参数不存在会报错 |
| rfind/rindex(sub[,start[,end]]) | 返回参数在字符串中末尾出现的位置(索引),find参数不存在不会报错返回-1,index参数不存在会报错 |
| format(*args,**kwargs) | 格式化字符串 |
| join(iterable) | 用来拼接可迭代对象中的所有元素,使用调用的str作为分隔符 |
| replace(old.new[,count]) | 将字符串中第一个参数指定的内容,使用第二个参数进行替换 |
| lstrip/rstrip/strip([chars]) | strip默认去除字符串两端的空白符,可以指定要去掉的字符。lstrip去除字符串左侧参数指定的字符,rstrip去除字符串右侧参数指定的字符 |
| split/rsplit(sep=None,maxsplit=-1) | split按字符切割,sep为指定的字符。rsplit从右向左切割 |
| splitlines([keepends]) | 根据换行符进行切割,可通过第一个参数保留换行符,True为保留,默认为False |
| startswith(prefix[,start[,end]]) | 判断字符串是否以指定的字符串进行开头,是返回True,否则返回False,可以指定开始点和结束点 |
| endwith(sufix[,start[,end]]) | 判断字符串是否以指定的字符串进行结尾,是返回True,否则返回False,可以指定开始点和结束点 |
| upper/lower() | upper将字符串转换成大写,lower将字符串转换成小写 |
| capitalize() | 将首字符大写 |
| partition/rpartition(sep) | 返回一个元组,元组含有三个元数。第一个元数为参数之前的内容,第二个元数为参数本身,第三个元数为参数后面的内容 |
| ljust/rjust/center(with[,fillchar]) | 当字符串长度小于参数(第一个参数)时,进行左对齐调整,默认以空格进行填充,第二个参数可以指定填充符。rjust右对齐,center居中对齐 |
| isalpha() | 字符串中的每一个字符都是alpha(字母型字符)中的字符,返回True,否则false |
| isnumber() | 判断字符串中的每一个字符是否都是数值型字符,是返回True,否则返回False |
| isdigit() | 判断字符串中的每一个字符是否都是数字型字符,是返回True,否则返回False |
| isdecimal() | 判断字符串中的每一个字符是否都是十进制字符,是返回True,否则返回False |
| isdentifier() | 判断字符串是否是合法标识符,是则返回True,否则返回False |
| islower()/isupper() | islower判断字符串是否为小写形式,是则返回True,否则返回False。isupper判断字符串是否为大写形式,是则返回True,否则返回False。 |
| isspace() | 判断字符串中每一个字符是否为空白符,是返回True |
5 字节
5.1 字节的定义
bytes是一系列字节组成的序列,是不可改变的。bytes每个元素的值在[0, 255]范围内(无符号单字节)。
5.2 基本操作
(1)创建字节
bytes常量的创建与字符串相同,只是在字符前使用b或B前缀即可。
(2)相关方法
索引,切片,运算,遍历等
# 字节类型使用b或B前缀,字节类型使用bytes表示
b = b"abc"
print(type(b))
# 注意:字节类型不能含有多字节的字符
# b = b"汉语" 这是错误的
# 索引与切片
print(b[0])
print(b[0:2])
# 遍历
for i in b:
print(i,end=" ")
5.3 相关方法
与字符串相似,参考字符串中的方法
5.4 字符集与编码集
(1)字符集
字符集,是一组字符组成的集合。字符集规定了有多少个字符,同时还要定义每个字符映射的那个值。不同字符集含有的个数不一样,不同字符集映射的码值不一样。所谓字符集就是里面定义了一堆字符,同时还定义了映射的法则。常见的字符集有ASCII,BIG5,Unicode,GBK等。字符计算机不能直接存储,数值的形式才能被二进制保存,那就需要将字符保存为字节的形式才能存储到计算机里面,这个过程就是编码
字符集,就是规定了字符与二进制之间如何进行转换的规则,即编码与解码的规则。因此,我们如果对某一个文本文件采用了一种编码方式保存,在解析该文件内容时,就需要采用相同的编码方式解码,否则就很可能造成乱码的现象,原因就是编码与解码的方式不统一造成的。
(2)Unicode字符集与UTF-8
在Python中,字符串str类型使用的字符集是Unicode字符集,是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前Unicode字符集包含1114112个编码值(0x0 ~ 0x10FFFF)。
由于Unicode取值范围的广泛性,这可能会对存储带来一些问题。对于码值小的字符,只需要使用1个字节存储就够了,但是,对于码值大的字符,却需要使用更多的字节去存储。如果使用定长的方式存储,这势必会造成存储空间的浪费。因此,后来人们创建了UTF-8的编码方式。UTF-8(8-bit Unicode Transformation Format)是针对Unicode设定的可变长度字符编码,是对Unicode字符集的一种通用转换格式。UTF-8编码使用1 ~ 4个字节来表示Unicode(0x000000 ~ 0x10FFFF)区间的值。如下表。
| 取值 |
占用空间(字节) |
| 0x000000 ~ 0x00007F |
1 |
| 0x000080 ~ 0x0007FF |
2 |
| 0x000800 ~ 0x00FFFF |
3 |
| 0x010000 ~ 0x1FFFFF |
4 |
Python3默认文件的编码方式为UTF-8编码(Python2默认为ASCII)。
(3)str与bytes
str(字符串)与bytes(字节)之间进行转换。通过调用str的encode方法可以返回字符串编码之后的结果(bytes类型)。同样,通过调用bytes类型的decode方法,可以将字节序列解码,转换回编码之前的字符串(str类型)。可以通过bytes与str函数,来实现编码与解码的操作。
6 转义序列
(1)转义序列
转义序列:就是使用两个或更多的字符来表示另外一个字符。即转义序列中的每个字符都不是其本来的含义,而是组合在一起,表示一个新的含义(字符)。Python的转义列表如下:
| 符号 |
说明 |
| \a |
响铃符 |
| \b |
退格符 |
| \f |
换页符 |
| \n |
换行符 |
| \r |
回车符 |
| \t |
水平制表符 |
| \v |
垂直制表符 |
| \' |
单引号' |
| \" |
双引号" |
| \\ |
反斜杠\ |
| \换行 |
续行符,不会产生换行 |
| \ooo |
可以是1 ~ 3位八进制数值,表示该数值对应的值(bytes类型)或字符(str类型)。 |
| \xhh |
\h后接两位16进制数值,表示十六进制数值对应的值(bytes类型)或字符(str类型) |
| \N{name} |
name为Unicode字符数据库中定义的名字。仅支持str类型。 |
| \uxxxx |
\u后接4位十六进制数值,表示该值(16位)对应的字符。仅支持str类型。 |
| \Uxxxxxxxx |
\U后接8位十六进制数值,表示该值(32位)对应的字符。仅支持str类型。 |
(2)原始字符串
如果在字符串常量前使用r或R前缀,则这样的字符串称为原始字符串。在原始字符串中,转义序列不会发生作用,这样某些情况下,可能会带来一定的简便性。
注意:在原始字符串中,末尾的符号不能是\,如果是\,则需要对\进行转义\\
7 序列相关函数
Python提供了相应的函数,用于根据已经存在的可迭代对象(序列类型都是可迭代类型)创建新的序列类型,相当于进行了类型转换。
| 函数名 | 描述 |
| list()/list(iterable) | 创建空的列表/可迭代对象转换成列表 |
| tuple()/tuple(iterable) | 创建字节对象 |
| str()/str(object) | 创建字符串 |
| bytes()/bytes(str) | 创建字节 |
| len(obj) | 长度 |
| max(iterable, *[, default=obj, key=func]) / max(arg1, arg2, *args, *[, key=func]) |
可以指定若干个元素,返回所有元素中的最大值 |
| min(iterable, *[, default=obj, key=func]) / min(arg1, arg2, *args, *[, key=func]) |
可以指定若干个元素,返回所有元素中的最小值 |
| sum(iterable, start=0) |
对序列求和,可以指定第二个参数,指定求和前的初始值 |
| chr(i) |
根据参数指定的编码值,返回该编码值对应的字符 |
| ord(c) |
根据参数指定的字符,返回该字符对应的编码值 |
| sorted(iterable, key=None, reverse=False) |
返回一个新的列表,不会修改原有的对象。注意:list的sort方法是就地排序,会修改原有的列表对象 |
8 遍历序列
可以使用while,for循环对序列进行遍历。
enumerate与zip函数用于遍历。
li = [6,66,8,88]
# for循环遍历比while遍历简单,但是在遍历时会丢失索引
# enumerate在遍历列表时,可以获得列表的索引
for index,item in enumerate(li):
print(index,item,end="\t")
print()
# zip用来同时遍历两个或更多可迭代对象
people = ["张三","李四","王五"]
money = [1000,2000,3000]
for p,m in zip(people,money):
print(p,m,end="\t")
