MLE v.s. MAP
- MLE: learn parameters from data.
- MAP: add a prior (experience) into the model; more reliable if data is limited. As we have more and more data, the prior becomes less useful.
- As data increase, MAP MLE.
Notation:
Framework:
- MLE:
- MAP:
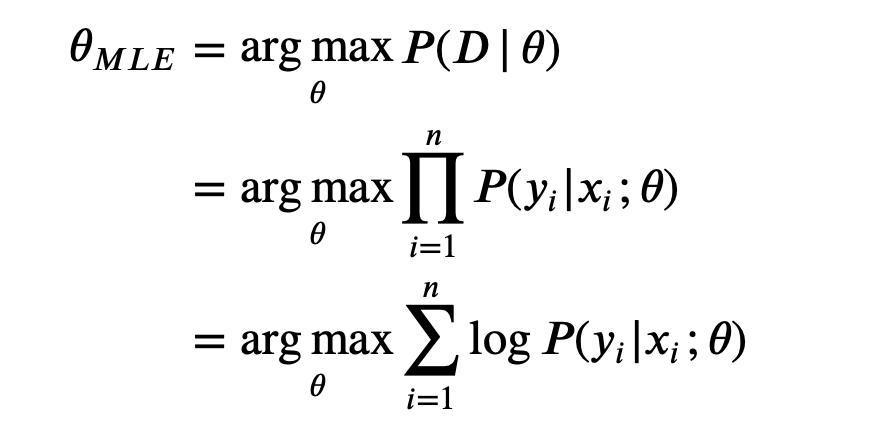
Note that taking a product of some numbers less than 1 would approaching 0 as the number of those numbers goes to infinity, it would be not practical to compute, because of computation underflow. Hence, we will instead work in the log space.
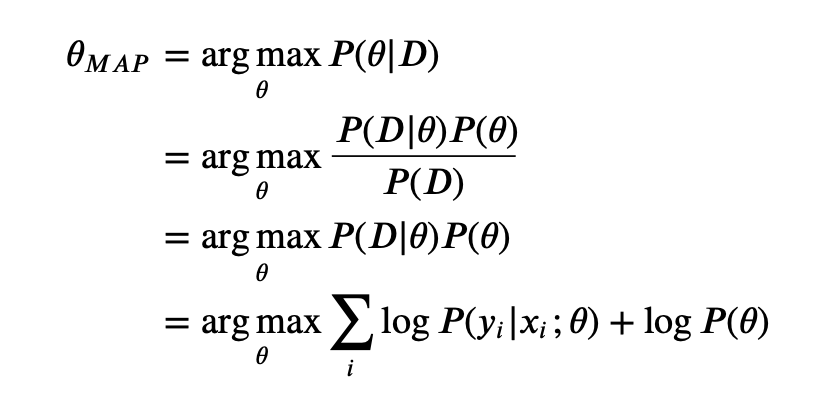
Comparing both MLE and MAP equation, the only thing differs is the inclusion of prior
in MAP, otherwise they are identical. What it means is that, the likelihood is now weighted with some weight coming from the prior.
If the prior follows the normal distribution, then it is the same as adding a regularization.
We assume , then
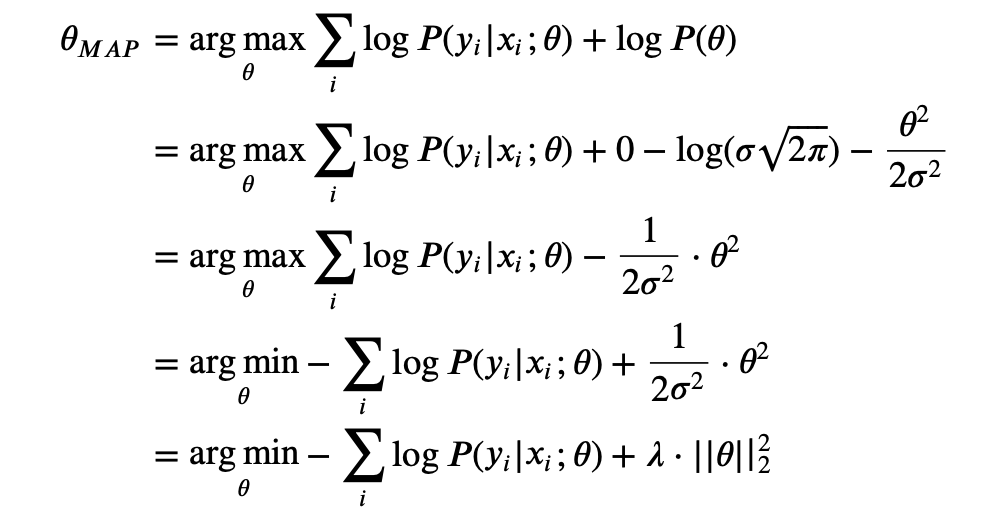
If the prior follows the Laplace distribution, then it is the same as adding a regularization.
We assume , then

