本篇主要内容:无监督学习。
(2)无监督学习
- 在监督学习的时候,我们举的例子里,数据集中每条数据都标明是阴性或者是阳性。
- 在无监督学习中,我们所给出的数据都是没有任何标签的或者是都是有着相同标签的。

在这时,我们得到了一个数据集,但是我们并不知道要拿它来做什么,也不知道每个数据点究竟是什么。我们只是被告知,这里有个数据集,你能在其中找到某种数据结构吗?
对于某个特定的数据集,无监督学习算法可能判定该数据集包含两个不同的簇。这就是聚类算法。

事实上,聚类算法被用在很多地方。其中一个应用聚类算法的例子就是谷歌新闻。谷歌新闻每天做的事情就是收集几万条甚至几十万条新闻,然后将它们组合成一个个新闻专题。
如图所示,当我们点击里面的不同的链接,我们就能看到华尔街日报、CNN、英国卫报关于BP油井泄漏事故的报道。所以,谷歌新闻所做的就是:去搜集成千上万条新闻,然后自动地将它们分簇。有关同一主题的新闻被显示在一起。
这里再举一个在基因组学的应用。这里是一个DNA微阵列数据的例子。基本思想是给定一组不同的个体,对于每个个体检测它们是否拥有某个特定的基因,也就是检测特定基因的表达程度。这些颜色(如红、绿、灰等等)展示了不同基因拥有特定基因的程度。然后你能所做的就是:运用一个聚类算法,把不同的个体归入不同的类或归为不同类型的人。
这就是无监督学习算法,因为我们没有提前告知这个算法这是一类,那是另一类等等,相反我们只是告诉这个算法,我这里有一堆数据,我不知道这些数据是什么,也不知道它们是什么类型,你能自动找出这些数据的结构吗?
生活中还有很多例子,比如
- 有一个大型的计算机集群,要想试图找出哪些机器趋于协同工作。这样如果把这些机器放在一起,就能够让你的数据中心更高效地工作。
- 第二种应用是社会网络的分析。如果可以得知你email最频繁的联系人或者知道你的Facebook好友或者你的Google+圈,我们是否可以自动识别同属一个圈子的朋友,来判断哪些人相互认识。
- 第三种应用是市场细分中的应用。许多公司拥有庞大的客户信息数据库。对于一个客户数据集,你能否自动找出不同的市场分割?能否自动将你的客户细分到不同的细分市场?从而能够自动高效地在不同的细分市场中进行销售?
- 还可以被用于天文数据分析。这些聚类算法带来了实用的星系形成理论。
这些都是聚类的例子,而聚类只是无监督学习的一种。
下面我们来讨论另外一种。我们先来讲一下鸡尾酒宴的问题。想象一下有一个宴会,有一屋子的人,大家都坐在一起讲话。因为每个人都在同时讲话,有许多声音混杂在一起,所以你几乎很难听清楚你面前的人说的话。现在假设有两个人正在同时说话,房间里还有两个麦克风。因为这两个麦克风离两个人的距离不一样,所以每个麦克风记录了两个人声音的不同组合。也许第一个人在一号麦克风里声音会响一点,第二个人在二号麦克风里声音会响一点。
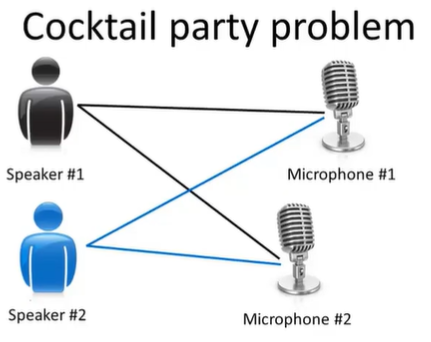
但是,每个麦克风都记录着两个说话者重叠的声音。我们能做的就是把这两个录音交给一种无监督学习算法,称为“鸡尾酒会算法”。让它帮你找出数据的结构,这个算法就会去听着两个录音,然后说这听起来像两个音频录音被叠加在一起。此外,这个算法还会分离出这两个被叠加在一起的音频源。
看看这个无监督学习算法,实现这个得要多么的复杂,是吧?它似乎是这样,为了构建这个应用,完成这个音频处理似乎需要你去写大量的代码或链接到一堆的合成器JAVA库,处理音频的库,看上去绝对是个复杂的程序,去完成这个从音频中分离出音频。事实上,这个算法对应你刚才知道的那个问题的算法可以就用一行代码来完成。
就是这里展示的代码:
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
研究人员花费了大量时间才最终实现这行代码。我不是说这个是简单的问题,但它证明了,当你使用正确的编程环境,许多学习算法是相当短的程序。所以,这也是为什么在本课中,我们打算使用Octave编程环境。Octave,是免费的开源软件,使用一个像Octave或Matlab的工具,许多学习算法变得只有几行代码就可实现。
事实上,在硅谷里,对大量机器学习算法,我们第一步就是建原型,在Octave建软件原型,因为软件在Octave中可以令人难以置信地、快速地实现这些学习算法。这里的这些函数比如SVM(支持向量机)函数,奇异值分解,Octave里已经建好了。如果你试图完成这个工作,但借助C++或JAVA的话,你会需要很多很多行的代码,并链接复杂的C++或Java库。所以,你可以实现这些算法,借助C++或Java或Python,它只是用这些语言来实现会更加复杂。(现在主流是Python)
下面有一道简单的复习题。
下面的例子中,你会用无监督学习算法解决哪个问题?(多选)
- 给邮件标记为垃圾邮件,学习区别是否垃圾邮件。
- 给定在web上找到的一组新闻文章,将它们分组到同一个主题。
- 给定一个客户数据数据库,自动发现细分市场,并将客户分组到不同的细分市场。
- 给定一个被诊断为糖尿病或非糖尿病患者的数据集,学习将新患者分类为糖尿病或非糖尿病。
显然第一个和第四个是监督学习的例子,而第二个和第三个是无学习监督的例子。