1.集成学习
现实情景中,一个学习器的泛化性能可能有局限,而集成学习则可以通过构造多个学习器来完成学习任务,有时也被称为多分类器系统,集成学习的大致步骤是先生成一组‘个体学习器’,然后基于某种策略将学习器结合起来,个体学习器同昌由现有的算法从训练数据产生,最常用的是决策树,还有神经网络,支持向量机等。根据集成学习中分类器的类别来看,如果集成学习器中的个体学习器都是相同的,则称为‘同质’集成,对应的个体学习器称为‘基学习算法’,而集成学习器中的个体学习器不同时,则称为‘异质集成’或‘组件学习器’。若根据个体学习器的生成方式来看,集成学习器大概分为两类,一类是个体学习器之间存在强依赖关系,必须串行生成的序列化方法,例如AdaBoost,以及个体学习器之间不存在强依赖关系,可同时生成的并行化方法,例如Bagging和随机森林。这篇将主要讲AdaBoost的生成过程。
2.弱分类器
集成学习器对多个学习器进行结合,常常获得比单一学习器更优的性能,这对弱学习器尤为明显,因此集成学习很多时候是针对弱学习器进行的,但并不是说集成学习一定要使用弱学习器,二者没有什么必然的因果关系.下面做一个简单的分析,考虑二分类问题,y∈{-1,1}和真实函数f,假设基分类器的错误率为ε,即对每个分类器hi有:

假设集成学习通过简单投票法结合T个基分类器,若有超过半数的基分类器分类正确,则集成分类就正确:

假设基分类器的错误率相互独立,由Hoeffding不等式,集成的错误率:


上式表示,随着集成中个体学习分类器数目T的增加,集成的错误率将指数级别的下降,最终趋于0,这也是集成学习器可以提高泛化能力的一种解释,但也要结合前提条件。
Proof:
假设抛硬币正面向上的概率为p,反面朝上的概率为1-排,令H(n)代表抛n次硬币正面朝上的次数,则最多K次的概率为:
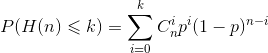
对于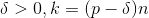
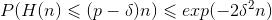
利用上面的Hoeffding不等式证明我们的集成错误率。
首先由集成错误率的形式得到:
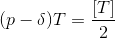
由取整函数性质:x-1 < [x] ≤ x < [x]+1

因为P = 1-ε ,得:

带入到Hoeffding不等式即得到书中(8.3),即集成错误率的不等式.
Tip:
对于二分类而言,弱分类器的准确率可能比较低,例如60%,65%等等,但它们的最低要求是一定要大于50%即随机预测的准确率,如果一个分类器的准确率低于随机预测的准确率,AdaBoost会将其舍弃.
3.AdaBoost
Boosting是一族可将弱学习器提升为强学习器的过程,他的机制是先从训练集训练出一个基学习器,再根据基学习器的表现调整样本分布,使得之前分错的样本受到更多的关注,然后基于调整后的分布训练下一个基学习器,如此重复,直到学习器达到指定数目T或泛化错误率达到一定要求,最终将T个学习器加权结合,其中最著名的就是AdaBoost算法,它的第t+1个学习器的生成依赖第t个学习器,所以是串行生成的序列化方法,看一下具体是如何实现的。
1)初始化训练数据权值分布
T = {[x1,y1],[x2,y2]...[xn,yn]} x为n维实向量,yi∈{-1,+1} 为初始数据
初始化权值分布D1 = (w1,w2,...,wn) wi=1/N
2)训练分类器,调整权值
根据初始数据,选择基学习器错误率达到最低的阈值为分界点,建立弱学习器h(x),并计算相应的e1,α1
对于分类器分错的样本,增加其权重,而对于分类正确的样本,则相应的减少其权重,根据D1,e1,α1推导新的权值分布D2
for i in range(T):
不断重复上述调整权值,计算ei,αi的过程,串行生成学习器h(x),得到T个训练分类器.
3)加权组合T个学习器,提高泛化性能
通过对上述学习器的加权组合,组成最终的分类器,并用符号函数sign预测最终的分类结果:
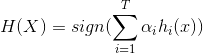
上述过程的伪代码 by 西瓜书:

其中误分类样本加权之和ei:

分类器重要性度量α:

权值更新公式:
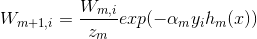
规范分布:
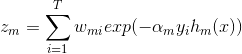
总结:
这一篇主要对集成学习,弱分类器集成提升泛化性能和AdaBoost的理论实现过程有了一些了解,主要就是不断地更新迭代权数,达到最终的标准,第五步判断大于0.5是在二分类情况下与随机预测准确率进行比较,如果一个学习器的准确率还不如随机猜测,理应将其舍弃。下一篇主要放在证明分类器重要性度量公式,权值公式,以及规范分布公式是如何得来的,为什么采用这样的更新方式.