1.ConcurrentHashMap:大家都知道HashMap是非线程安全的,Hashtable是线程安全的,但是由于Hashtable是采用synchronized进行同步,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。而ConcurrentHashMap避免了为整个容器上锁。JDK1.8以前他把整个容器分成了若干个段(Segment),而这些段数组的容量是固定的。每个段又相当于一个hashTable,相当于一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。并且ConcurrentHashMap的扩容是有效扩容,hashTable的有可能是无效扩容。jdk1.8以后,抛弃了原有的Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性,当链表节点数超过指定阈值的话,也是会转换成红黑树的。至于如何实现,ConcurrentHashMap最常用的方法也就是put方法和get方法,那么下面主要看代码注释,便于理解。


这个put的过程很清晰,对当前的table进行无条件自循环直到put成功,可以分成以下六步流程来概述:
1、判断Node[]数组是否初始化,没有则进行初始化操作
2、通过hash定位数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头节点),添加失败则进入下次循环。
3、检查到内部正在扩容,就帮助它一块扩容。
4、如果f!=null,则使用synchronized锁住f元素(链表/红黑树的头元素)。如果是Node(链表结构)则执行链表的添加操作;如果是TreeNode(树型结构)则执行树添加操作。
5、判断链表长度已经达到临界值8(默认值),当节点超过这个值就需要把链表转换为树结构。
6、如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
1.spread(key,hashCode()) ,该方法主要是将key的hashCode的低16位于高16位进行异或运算,这样不仅能够使得hash值能够分散能够均匀减小hash冲突的概率,另外只用到了异或运算,在性能开销上也能兼顾。

2.initTable方法 ,主要作用将tab进行初始化

为了保证能够正确初始化,在第1步中会先通过if进行判断,若当前已经有一个线程正在初始化即sizeCtl值变为-1,这个时候其他线程在If判断为true从而调用Thread.yield()让出CPU时间片。正在进行初始化的线程会调用U.compareAndSwapInt方法将sizeCtl改为-1即正在初始化的状态。另外还需要注意的事情是,在第四步中会进一步计算数组中可用的大小即为数组实际大小n乘以加载因子0.75.可以看看这里乘以0.75是怎么算的,0.75为四分之三,这里n - (n >>> 2)是不是刚好是n-(1/4)n=(3/4)n,挺有意思的吧:)。如果选择是无参的构造器的话,这里在new Node数组的时候会使用默认大小为DEFAULT_CAPACITY(16),然后乘以加载因子0.75为12,也就是说数组的可用大小为12。
3.CAS关键操作
tabAt()该方法用来获取table数组中索引为i的Node元素。
casTabAt()利用CAS操作设置table数组中索引为i的元素。
setTabAt()该方法用来设置table数组中索引为i的元素。
4.ConcurrentHashMap的扩容,通过判断该节点的hash值是不是等于-1(MOVED),代码为(fh = f.hash) == MOVED,说明 Map 正在扩容。那么就帮助 Map 进行扩容。以加快速度。如何帮助扩容呢?那要看看 helpTransfer 方法的实现。扩容过程有点复杂,可以查看上面注释。这里主要涉及到多线程并发扩容,ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历,下图是多线程合作扩容的过程。

get方法
1.计算hash值,定位到该table索引位置,如果是首节点符合就返回。
2.如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回。
3.以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
HashMap、Hashtable、ConccurentHashMap三者的区别
HashMap线程不安全,数组+链表+红黑树
Hashtable线程安全,锁住整个对象,数组+链表
ConccurentHashMap线程安全,CAS+同步锁,数组+链表+红黑树
HashMap的key,value均可为null,其他两个不行。
在JDK1.7和JDK1.8中的区别
在JDK1.8主要设计上的改进有以下几点:
1、不采用segment而采用node,锁住node来实现减小锁粒度。
2、设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
3、使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
4、sizeCtl的不同值来代表不同含义,起到了控制的作用。采用synchronized而不是ReentrantLock
CopyOnWriteArraySet:
1)它最适合于具有以下特征的应用程序:set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
* 2)它是线程安全的, 底层的实现是CopyOnWriteArrayList;
* 3)因为通常需要复制整个基础数组,所以可变操作(add、set 和 remove 等等)的开销很大。
* 4)迭代器不支持可变 remove 操作,因为CopyOnWriteArrayList的迭代器的remove操作不受支持。
* 5)使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
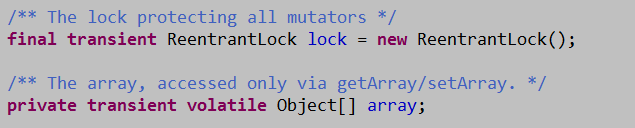
CopyOnWriteArrayList是ArrayList 的一个线程安全的变体,其中所有可变操作(add、set等等)都是通过对底层数组进行一次新的复制来实现的。这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更 有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。“快照”风格的迭代器方法在创建迭代器时使用了对数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作remove不受支持。这些方法将抛出UnsupportedOperationException。允许使用所有元素,包括null。底层是一Reetrantlock 和 volatile 的 Object数组。
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
