
初期,网络规模小,甚至不会遇到并发的问题。
随着网络规模扩大,慢慢的就遇到了并发的问题。
第10章提高,用Threading的方式处理并发,但是一个线程只能处理一个socket,即一个线程处理一个用户请求,初期服务器,可用开启的线程不多,无法支持上万用户。
如何处理上万用户?就涉及到阻塞非阻塞,同步、异步
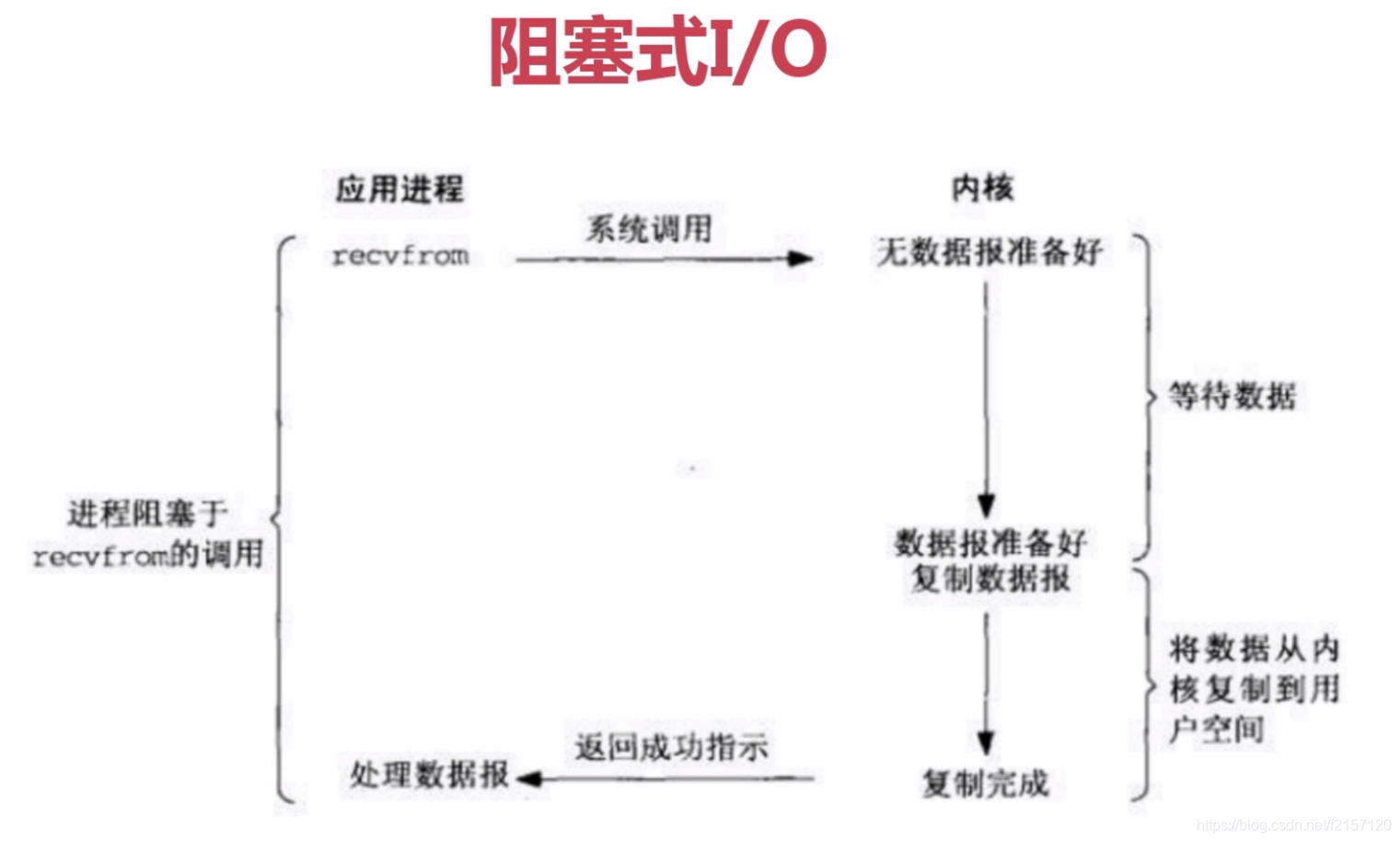
Unix下面的5中IO:阻塞式IO应用最多。五种IO,从上到下是逐步发展的过程,只是信号驱动式I/O应用很少。

# requests 包基于urllib,urllib又是基于socket实现的。 凡是web请求,数据库连接,网络连接,数据通信等,最底层的实现都是基于socket实现的。
# socket是操作系统提供的功能,只是不同的语言将socket封装为不同的接口而已。
# 如何通过socket,完成urlib的get请求?
import socket
from urllib.parse import urlparse # urlparse 只是用于url解析,并不会处理socket
def get_url(url):
# 通过socket请求html,解析url
url = urlparse(url)
host = url.netloc # 提取主域名
path = url.path
if path == "": #如果path为空,直接请求主域名
path = "/"
# 建立socket连接
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.connect((host,80)) # http链接一般都为80端口,否则会导致无法连接。
# 发送数据
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path,host).encode("utf8")) # Get请求,然后是相对路径。
# 将所有数据读取完
data = b"" # 数据为bytes类型
while True:
d = client.recv(1024)
if d:
data += d
else:
break
data = data.decode("utf8")
html_data = data.split("\r\n\r\n")[1] # \r 回车符号 \n 换行符号, 去掉HTTP头的信息
print(html_data)
client.close()
if __name__=="__main__":
get_url("http://www.baidu.com")上例程序代码中,实际上是阻塞的。比如等待连接的时间,send之后等待接收的时间,此时CPU处于阻塞状态,浪费了大量的CPU时间。
# 建立socket连接
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.setblocking(False) '''此处可用设置client,在client.connect(host,80)后立即返回,不等待连接成功(三次握手)'''
client.connect((host,80)) # http链接一般都为80端口,否则会导致无法连接。
'''
# 后面的执行语句要依赖前面建立的连接,则需要不停的询问连接是否建立好,需要while循环不停的去检查状态,是否连接建立好。
# 此时,仍然需要消耗CPU资源,非阻塞没有特别大的意义。
# 如果是做计算任务,或者是再次建立其它的连接请求,此时不依赖于之前的连接状态,此时非阻塞式的io就优势明显
'''非阻塞式IO并不一定比阻塞式IO优越,取决于具体的应用场景/业务逻辑。

时间会消耗在内核请求,recvfrom
比如:内存为8G,最底层低地址的1G就会被保护起来作为操作系统专用,用户只能使用剩余的空间。当调用recvfrom函数时,实际上是用户申请,操作系统帮忙完成recvfrom的功能,去访问网络。同样,数据返回时,也是首先返回低地址空间,有操作系统返回每个应用程序的缓存地址空间。应用程序缓存空间无法直接调用操作系统的缓存空间

IO复用实际上就是select/pool/epool,调用select后,os会返回哪些socket/文件句柄已经准备好。select也是阻塞的方法,如果OS总没有一个socket/文件句柄准备好,也会一致阻塞。
select可用同时监听多个socket/文件句柄的状态。比如同时发起100个socket/select请求,一旦有一个ready,就可用立即处理。而普通的thread线程处理是无法办到的,性能提高。 不像thread处理那样,需要while循环轮询。
从数据从内核复制到用户空间的时间,仍然无法避免。


异步io是真正意义上的aio,实际上成熟的框架使用不多,大量还是使用io多路复用。

IO多路复用实际上是同步的

再次调用select时,需要调用所有的fds

pool查询效率提升不大

epool只用于linux
select/pool/epool是不断进化的关系,但并不代表比select优越。
在高并发,连接活跃度不是很高的情况下,epool比select优越。比如web,用户浏览网页后,马上会断开,此时epool优越
并发性不高,同时连接很活跃,此时select比epool优越。 比如游戏,游戏建立好之后,很少断开,活跃度高,此时select优先
