Hash表(哈希表),也叫散列表,在这之前还以为这是两种数据结构呢,不知道为啥他俩能扯上关系,翻译了一波才知道,hash就是把……弄乱;斩碎的意思,这下明白名字的由来了。
由于数组的查询快,增删慢,而链表的增删快,而查询慢,于是出来了哈希表这种数据结构,吸取了数组和链表的优先。
在我们使用数组链表数据结构时,也就是实现通过一个key去查找value,对数组而言就是通过下标来找对应的值,对于链表而言,就是通过data里面存的key,来对应value。正是如此,所以数组的查找比较快,直接通过索引,而链表呢,就需要遍历链表,判断key,来获取value。而哈希表是通过数组的快速查询进行一个模糊的定位,然后再通过这个小范围去查找对应的value。
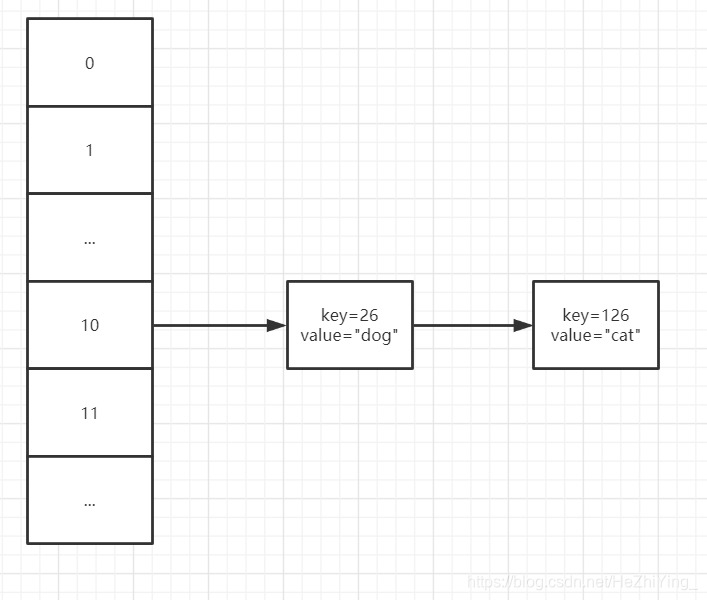
提取上图的一条链,方便下面讲解
核心思想
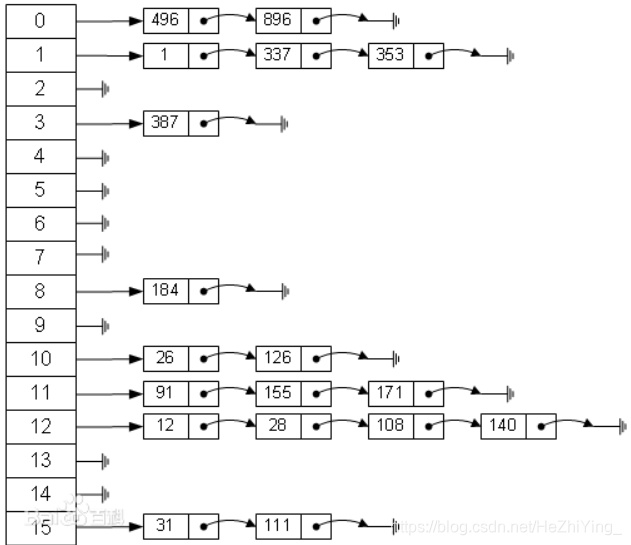
首先构造出这个数组,这里是0~15,通过除留余数法进行构造,如果一个key是26,26%16=10,所以这里把key为26的数据存入下标为10的链表里,这里是通过拉链法实现的,也就是数组的每一个元素都有一个指针执行一个链表,当有余数与该索引对应时,那么就把该元素的key和value存入链表里,如果我们在查询的时候,如果key是126,那么我们会找到下标为10的索引值,而这里对应了两个值,那么我们就需要对该链表进行遍历,看看哪个key是126,就取key是126的value,这样一来,查询的速度通过数组快速定位,增删也是通过数组快速定位,然后链表直接追加上。如果key是字符串,可以通过一些算法,进行数字化,然后存储进去。
多扯一点
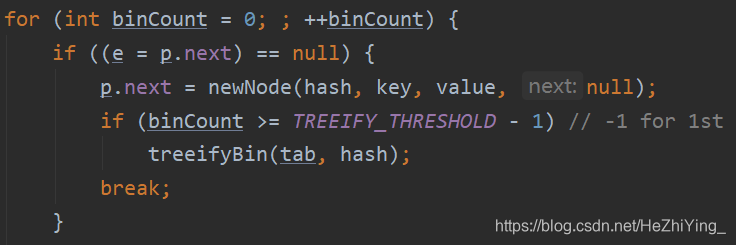
到这里你可能会想到Map,对的就是Map,还有HashMap,是吧跟Hash扯上关系了,在JDK1.7之前,当找到一个数组下标后,就是通过遍历链表实现的,此时时间复杂度是O(n),但是在JDK1.8之后当链的长度大于等于8的时候,就把这个链表的实现改成了红黑树了,这样一来,就提高了找具体的key的效率,时间复杂度是Olog(n)

面试官问你什么是Hash表

猜你喜欢
转载自blog.csdn.net/HeZhiYing_/article/details/105088289
今日推荐
周排行