一、整体思路
最近在搞LCD显示汉字、特殊图形的问题。以前玩1602的时候自己做过字模,就是通过1602自带的用户DIY的一个存储点阵区CGROM,把做好的字模转化成点阵的数据存储在CGROM中,最后把汉字显示在1602上面。但是当时是用51做的,而且字模地址是固定存储在1602中的,我们不用去管。在stm32+TFTLCD显示汉字这个实验上面,我的思路还是这个样子,就是做好字模,然后根据地址找到对应汉字的点阵数据。那么问题来了,在1602中每个字模都有自己的显示编码,那么在stm32中,汉字有自己的显示编码吗?
二、数组和字符串的关系
在说汉字的显示编码之前,我想先讲一下数组和字符串的关系。字符串我们可以把它当成一种特殊的数组,编译器识别到字符串时,会自动把它的地址分配到stm32的Flash里面,这就意味着字符串本身就是一个常量。字符串的定义是用双引号括起来的一段字符数据,这段数据最后会自动加上一个空字符为结尾(‘\0’)。我们这里直接上程序:
#include "sys.h"
#include "delay.h"
#include "usart.h"
#include "led.h"
#include "string.h"
char arrBuf_1[3] = {'f','a','t'};
char arrBuf_2[4] = {'f','a','t','\0'};
char strBuf_1[] = "fat";
int main(void)
{
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);//设置系统中断优先级分组2
delay_init(168); //初始化延时函数
uart_init(115200);//初始化串口波特率为115200
if(!strcmp(arrBuf_1,strBuf_1))
{printf("arrBuf_1 与 strBuf_1 相等\r\n");}
else if(!strcmp(arrBuf_2,strBuf_1))
{printf("arrBuf_2 与 strBuf_1 相等\r\n");}
else
{printf("数组与字符串均不相等\r\n");}
printf("arrBuf_1的地址为:0x%x\r\n",arrBuf_1);
printf("arrBuf_2的地址为:0x%x\r\n",arrBuf_2);
printf("strBuf_1的地址为:0x%x\r\n",strBuf_1);
printf("arrBuf_1中'f'字符常量的地址为:0x%x\r\n",*arrBuf_1);
printf("arrBuf_2中'f'字符常量的地址为:0x%x\r\n",*arrBuf_2);
printf("strBuf_1中'f'字符常量的地址为:0x%x\r\n",*strBuf_1);
while(1);
return 0;
}
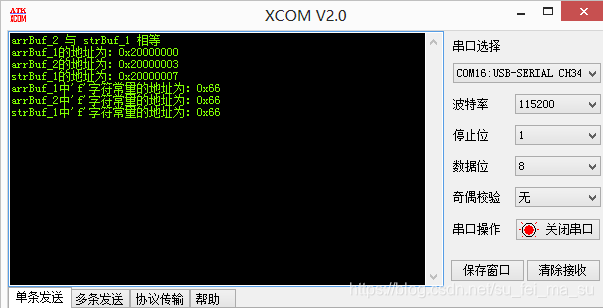
一个数组的数组名,就是指向该数组第一位成员的地址的指针,所以我们打印数组名,就是打印该数组第一个成员的地址,解除该指针则打印的是该地址里保存的值,对应程序而言就是’f’的ASCII码值,以16进制形式体现。
通过简单的比较我们可以看到,字符串就是把每个字符转化成单引号字符常量,存储在对应的数组成员中,且最后一位自动加入’\0’空字符表示结尾。上面三个数组的地址是不同的,但是每个数组中存储的单引号字符常量的值却是相同的,这就说明单引号字符常量在keil编译器下,被自动识别为对应的ASCII码值。ASCII码值我们大可以理解为每个字符的显示编码。
三、GBK码
keil这个编译器会自动把有ASCII码值的字符常量识别为对应的ASCII码值,没有对应ASCII码值的常量比如汉字日语等,我们也有一套特殊的编码来表示,这个编码就是GBK码。
GBK码有16位,两个字节组成。
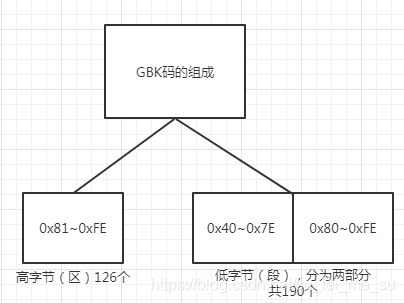
高字节的范围为:0x81~0xFE,每一位都称为一个区,总共有126个区。
低字节的范围为:0x40~0x7E , 0x80~0xFE,低字节总共由两部分构成,每一位都称为一个段,总共有190个段。
GBK码有126个区,190个段,每一个区的每一个段都可以表示一个汉字,那么GBK码总共可以表示126 * 190 = 23940 个汉字。足以满足我们大多数场景下的使用。在keil环境下,编译器自动的将汉字识别为对应的GBK码。
但是GBK码只是一个显示编码,每个显示编码对应的字模还是要由我们来做,做好以后我们把存储汉字字符的字模(点阵)的数组称为GBK库(这个有很多软件可以帮我们生成)。但是要从这个库里找到对应的汉字,就需要知道每个汉字在这个库里的偏移量,通过每个汉字的GBK码,我们可以算出来对应的偏移量:
当GBKL < 0x7F时,HP = ((GBKH - 0x81)*190+GBKL-0x40) * (size * 2)
当GBKL > 0x7F时,HP = ((GBKH - 0x81)*190+GBKL-0x41) * (size * 2)
GBKH 为高字节,GBKL 为低字节,低字节的两部分中间有个断层0x7F,所以要分情况判断其偏移。HP即为求出的汉字显示编码在GBK库中的偏移量,size为显示汉字的大小。
我们这里举个例子,以字符串“你好啊”为例,分析每个汉字的GBK码:
#include "sys.h"
#include "delay.h"
#include "usart.h"
#include "led.h"
#include "string.h"
char arrBuf_1[3] = {'f','a','t'};
char arrBuf_2[4] = {'f','a','t','\0'};
char strBuf_1[] = "fat";
const char* strBuf_2 = "你好啊";
int main(void)
{
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);//设置系统中断优先级分组2
delay_init(168); //初始化延时函数
uart_init(115200);//初始化串口波特率为115200
if(!strcmp(arrBuf_1,strBuf_1))
{printf("arrBuf_1 与 strBuf_1 相等\r\n");}
else if(!strcmp(arrBuf_2,strBuf_1))
{printf("arrBuf_2 与 strBuf_1 相等\r\n");}
else
{printf("数组与字符串均不相等\r\n");}
printf("arrBuf_1的地址为:0x%x\r\n",arrBuf_1);
printf("arrBuf_2的地址为:0x%x\r\n",arrBuf_2);
printf("strBuf_1的地址为:0x%x\r\n",strBuf_1);
printf("arrBuf_1中'f'字符常量的地址为:0x%x\r\n",*arrBuf_1);
printf("arrBuf_2中'f'字符常量的地址为:0x%x\r\n",*arrBuf_2);
printf("strBuf_1中'f'字符常量的地址为:0x%x\r\n",*strBuf_1);
printf("strBuf_2汉字常量‘你’的GBK码高位码为:0x%x\r\n",*strBuf_2);
printf("strBuf_2汉字常量‘你’的GBK码低位码为:0x%x\r\n",*(strBuf_2+1));
printf("strBuf_2汉字常量‘好’的GBK码高位码为:0x%x\r\n",*(strBuf_2+2));
printf("strBuf_2汉字常量‘好’的GBK码低位码为:0x%x\r\n",*(strBuf_2+3));
printf("strBuf_2汉字常量‘啊’的GBK码高位码为:0x%x\r\n",*(strBuf_2+4));
printf("strBuf_2汉字常量‘啊’的GBK码低位码为:0x%x\r\n",*(strBuf_2+5));
while(1);
return 0;
}
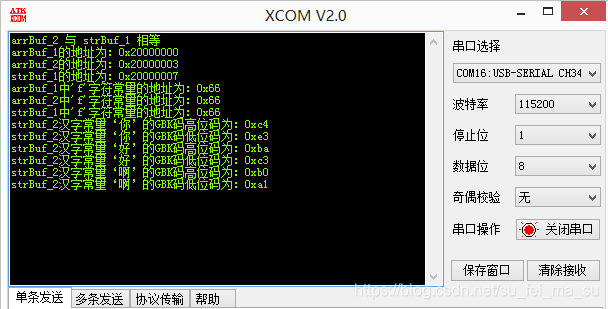
strBuf_2为指针名(数组名),指向第一个成员的地址,解除运算以后就是第一个成员的值,对应汉字即为GBK码,因为GBK码为16位,所以我们连续打印6个字节的数据,每两个组合即为对应汉字的GBK码值。然后我们根据得到的GBK码值,带入上面的公式,算出来每个汉字在GBK库里的偏移量,根据每个汉字在GBK库中的偏移量,我们就可以定位到具体的汉字。
以上就是汉字显示的基本原理了,下一篇文章给大家介绍一下显示汉字的步骤,在EEPROM上建立自己的字库,以及如何在LCD上显示特殊图形(自己DIY)。

