最近由于工作涉及一些关于Ceph存储的部署和测试,谨以此文总结记录一下ceph cluster搭建过程,基本上ceph官网都有,只是做一个总结,欢迎各位喷我,以便我提高。
本文主要介绍使用ubuntu系统搭建一个完整的ceph cluster,并通过ceph client简单使用RBD & cephFS。
官方有使用ceph-deploy工具去自动部署ceph cluster的介绍,本文为了让大家更好的理解整个过程,在参数调优方面更为灵活,所以使用手搭建的方法,如果想ceph-deploy去部署,后续会贴出来。
我的环境:ubuntu-12.04.5-server VM * 4
ceph版本: v0.94.5
节点角色:
| hostname | IP | 角色 |
| deploy | 10.128.3.10 | 管理/client |
| ceph1 | 10.128.3.11 | mon/mds/osd |
| ceph2 | 10.128.3.12 | mon/mds/osd |
| ceph3 | 10.128.3.13 | mon/mds/osd |
由于虚拟机资源不够,同个虚拟机同时启动mon/mds/osd,如果不需要使用cephFS的话以省略mds的部署。
一、虚拟机安装配置

三个ceph节点最好添加两块虚拟硬盘,其中一块用于osd,另一块用于ubuntu系统本身,其实osd也可以指定本地文件系统中的路径。
安装好ubuntu-12.04.5-server,安装过程略,打开SSH服务,用于远程登陆配置。
二、安装ceph
每个节点更新安装源,由于ubuntu自带的源里ceph版为太低,当前最新能安装v0.94.5版本
root@deploy:~#wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
root@deploy:~# echo deb http://ceph.com/debian/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
root@deploy:~# apt-get update
root@deploy:~# apt-get install ceph
三、部署准备
在deploy节点做以下操作:
1. 把ceph1/ceph2/ceph3写到deploy的/etc/hosts里
10.128.3.10 deploy
10.128.3.11 ceph1
10.128.3.12 ceph2
10.128.3.13 ceph3
2. 生成一个唯一的fsid
root@deploy:~#uuidgen
f32dcc3c-179a-47ba-962a-601beba0b671
3. 编写一个/etc/ceph/ceph.conf
[global]fsid = 3ea1c257-1b66-40b5-8ffd-fb27614584b4(修改为生成的)
mon initial members = node1,node2,node3(按照自己定义的写)
mon host = 10.34.70.65, 10.34.70.64, 10.34.70.63(对应定义的IP)
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = 1024
file store xattr use omap = true
osd pool default size = 1 (副本数量)
osd pool default min size = 1
osd pool default pg num = 128
osd pool default pgp num = 128
osd crush chooseleaf type = 1
mon_pg_warn_max_per_osd = 1000 (消除ceph-warn的配置)
mon clock drift allowed = 2
mon clock drift warn backoff = 30
(以下内容根据实际情况修改)
[mon.node1]host = node1
mon addr = 10.34.70.65:6789
[mon.node2]
host = node2
mon addr = 10.34.70.64:6789
[mon.node3]
host = node3
mon addr = 10.34.70.63:6789
[osd.0]
host = node1
addr = 10.34.70.65:6789
osd data = /var/lib/ceph/osd/ceph-0
[osd.1]
host = node2
addr = 10.34.70.64:6789
osd data = /var/lib/ceph/osd/ceph-1
[osd.2]
host = node3
addr = 10.34.70.63:6789
osd data = /var/lib/ceph/osd/ceph-2
[mds.node1]
host = node1
[mds.node2]
host = node2
[mds.node3]
host = node3
4. 生成监视器密钥
root@deploy:~# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
creating /tmp/ceph.mon.keyring
5. 创建admin用户
root@deploy:~# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow'
creating /etc/ceph/ceph.client.admin.keyring
6. 把client.admin密钥加入ceph.mon.keyring
root@deploy:~# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
importing contents of /etc/ceph/ceph.client.admin.keyring into/tmp/ceph.mon.keyring
7. 创建monitor map
root@deploy:~# monmaptool --create --add ceph1 10.128.3.11 --add ceph2 10.128.3.12 --add ceph3 10.128.3.13 --fsid f32dcc3c-179a-47ba-962a-601beba0b671 --clobber /tmp/monmap
monmaptool: monmap file /tmp/monmap
monmaptool: set fsid to f32dcc3c-179a-47ba-962a-601beba0b671
monmaptool: writing epoch 0 to /tmp/monmap (3 monitors)
8. 拷贝/etc/ceph/*,/tmp/monmap, /tmp/ceph.mon.keyring到所有ceph节点
如ceph1:
root@deploy:~# scp /etc/ceph/* root@ceph1:/etc/ceph/
root@deploy:~# scp /tmp/monmap root@ceph1:/tmp/monmap
root@deploy:~# scp /tmp/ceph.mon.keyring root@ceph1:/tmp/ceph.mon.keyring
四、部署mon
在每个ceph节点下执行以下操作,对应不同hostname需要把hostname改掉
1. 初始化mon数据
root@ceph1:~# ceph-mon --mkfs -i ceph1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
ceph-mon: set fsid to f32dcc3c-179a-47ba-962a-601beba0b671
ceph-mon: created monfs at /var/lib/ceph/mon/ceph-ceph1 formon.ceph1
2. 创建done文件
root@ceph1:~# touch /var/lib/ceph/mon/ceph-ceph1/done
3. 创建sysvinit文件,为了系统自动启动
root@ceph1:~# touch /var/lib/ceph/mon/ceph-ceph1/sysvinit
4. 启动mon进程
root@ceph1:~# service ceph start mon.ceph1
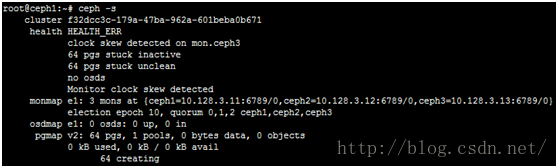
当所有ceph节点启动mon进程后,可以查看当前集群状态,可看到已经启动mon,但这时没有启动osd,所以显示空间为0
五、部署osd
1. 在管理节点deploy创建osd id
此例中我们创建3个osd id,以下命令执行3下,分别得到id(0,1,2)
root@deploy:~# ceph osd create
2. 在每个ceph节点创建osd工作目录,每个节点对应一个id
ceph1:
mkdir /var/lib/ceph/osd/ceph-0
ceph2:
mkdir /var/lib/ceph/osd/ceph-1
ceph3:
mkdir /var/lib/ceph/osd/ceph-2
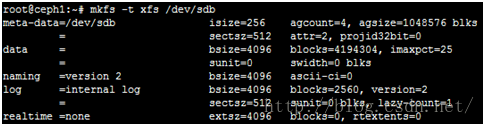
3. 对附加的磁盘格式化并且挂载出来
这里附加的磁盘为/dev/sdb
root@ceph1:~# mkfs -t xfs /dev/sdb
root@ceph1:~# mount /dev/sdb /var/lib/ceph/osd/ceph-0
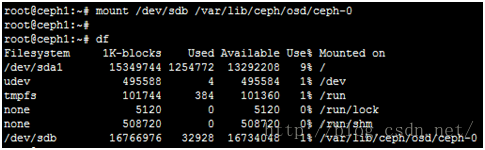
如果需要系统启动自动挂载,需要添加到/etc/fstab
/dev/sdb /var/lib/ceph/osd/ceph-0 xfs defaults 0 0
4. 初始化OSD数据目录
root@ceph1:~# ceph-osd -i 0 --mkfs --mkkey

5. 注册此OSD的密钥
root@ceph1:~# ceph auth add osd.0 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-0/keyring
6. 把节点加入CRUSH MAP
root@ceph1:~# ceph osd crush add-bucket ceph1 host
7. 节点放入default根
root@ceph1:~# ceph osd crush move ceph1 root=default
8. 把此 OSD 加入 CRUSH 图之后,它就能接收数据了。你也可以反编译 CRUSH 图、把此 OSD 加入设备列表、对应主机作为桶加入(如果它还不在 CRUSH 图里)、然后此设备作为主机的一个条目、分配权重、重新编译、注入集群。
root@ceph1:~#ceph osd crush add osd.0 1.0 host=ceph1
9. 添加系统自动启动osd
root@ceph1:~# touch /var/lib/ceph/osd/ceph-0/sysvinit
10. 启动osd进程
root@ceph1:~# service ceph start osd.0
11. 此时查看ceph集群状态,已经正常,并且此时开始,就可以正常使用rbd和radosgw了
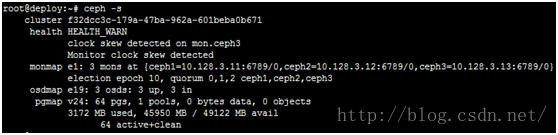
六、部署mds
在每个ceph节点上执行以下操作
1. 创建mds工作目录
root@ceph1:~# mkdir -p /var/lib/ceph/mds/ceph-ceph1
2. 注册MDS的密钥
root@ceph1:~# ceph auth get-or-create mds.ceph1 mds 'allow ' osd'allow rwx' mon 'allow profile mds' -o /var/lib/ceph/mds/ceph-ceph1/keyring
3. 启动mds进程并设置系统自动启动
root@ceph1:~# touch /var/lib/ceph/mds/ceph-ceph1/sysvinit
root@ceph1:~# service ceph start mds.ceph1
创建好mds后,使用ceph -s查看没有关于mds的显示,此时需要创建一个cephFS,就能显示
七、pool操作
1. 查看pool
ceph osd lspools
2. 创建一个pool
//ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
创建一个命名为images的pool
ceph osd pool create images 128 128
3. 删除一个pool
//ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
删除pool:images
ceph osd pool delete images images --yes-i-really-really-mean-it
八、创建一个块设备(RBD)
1. 首先创建一个pool
ceph osd pool create images 128 128
2. 创建块设备,基于pool
//rbd --pool {pool-name} create {image-name} --size {megabytes}
创建一个20M的RBD
rbd --pool images create image1 --size 20
3. 挂载这个RBD,并使用
map到本地块设备,并会返回本地块设备名,记下来,这里为(/dev/rbd1)
rbd --pool images map image1
格式化并挂载image1
mkfs.ext4 /dev/rbd1
mkdir mnt
mount -t ext4 /dev/rbd1 mnt/
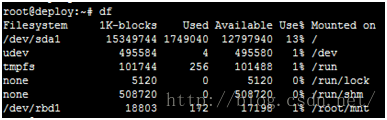
此时可以往这个挂载点里读写了
九、创建一个cephFS
1. 首先创建两个pool
其中一个作为元数据pool,另一个作为数据pool
ceph osd pool create metadata 128 128
ceph osd pool create data 128 128
2. 创建cephFS
ceph fs new testfs metadata data
3. 查看当前集群中的cephfs
ceph fs ls
4. 挂载cephFS并使用
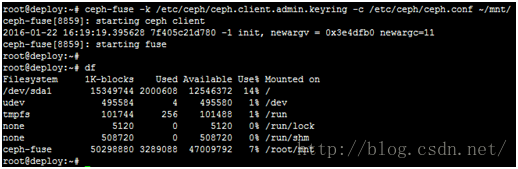
有两种方式,一种为内核挂载方式,另一种ceph提供的用户态挂载方式fuse
a)kernel
mount.ceph ceph1,ceph2,ceph3:/ mnt/ -o name=admin,secret=`ceph-authtool -p /etc/ceph/ceph.client.admin.keyring`
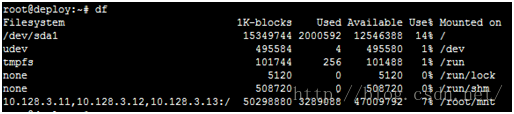
b)fuse
ceph-fuse -k /etc/ceph/ceph.client.admin.keyring -c /etc/ceph/ceph.conf ~/mnt/