Rnn最大的不同是,它有 状态(State)
相对于普通的神经网络和算法
如何体现State的不同呢?
我们现在有这样一个需求:
我一次又一次的输入一些值,
我希望在我每次输入的时候,
我的程序会输出我之前 倒数第3次时的输入的值
比如,
我输入 1 2 3 4 5 6 7 8 (一次 输入 一个)
它输出 - - - 1 2 3 4 5
然后我又输入 5 4 3 2 1 0
然后它的输出 6 7 8 5 4 3
引入需要的库
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt一 生成数据
函数generateData随机生成了5w个由0和1组成的序列,
然后把x分成5份,变成一个5行,10000列的二维数组,
y也是一样,不过y中的项全部向右位移了3位
total_series_length = 50000 #总共有5万个数让Rnn训练
truncated_backprop_length = 15 #某种限制的长度为15,之后会用到
batch_size = 5 #把数据分成5份
echo_step = 3 #位移的大小
def generateData():
# 1.返回一个 total_series_length 长度的数组
# 2.返回数组中的每一项,都是从 0 1 中随机选出的(第一个参数的含义)
# 3.选0和选1的概率分别为0.5和0.5
x = np.random.choice(2, total_series_length, p=[0.5, 0.5])
# 整体向右移动echo_step个数,超出的补在前面
y = np.roll(x, echo_step)
# 从后面补到前面的项都设置为0
y[0:echo_step] = 0
# 把x(长度为50000)变成一个5行,10000列的数组
x = x.reshape((batch_size, -1)) # -1 表示自动计算出column的数量
y = y.reshape((batch_size, -1))
return (x, y)
二 构造输入序列
truncated_backprop_length = 15 #某种限制的长度为15,之后会用到
batch_size = 5 #把数据分成5份
# 定义两个placeholder, 数据的结构为(5,15)的二维数组
# 注意,虽然placeholder没有输入实际的值,但是我们已经把定了了数据结构
batchX_placeholder = tf.placeholder(tf.float32, [batch_size, truncated_backprop_length])
batchY_placeholder = tf.placeholder(tf.int32, [batch_size, truncated_backprop_length])
# 之后会把第一部分生成的5行10000列的数据,撕成一片一片的,
# 每片长度15列(行数不变,5x15), 喂给placeholder
# 按列解包,你可以理解成转置,(变成15x5了)
# 但是要注意的是:
# 现在inputs_series是一个长度为15的list,list中的每一项是一个长度为5的array
inputs_series = tf.unstack(batchX_placeholder, axis=1)
labels_series = tf.unstack(batchY_placeholder, axis=1)
# 为什么把数据倒来倒去,看得人都是晕的
# unstack的目的是,
# 你可以理解那5行10000列的数据(现在是5行15列),当成5根并列的葱,
# 然后一刀切下去,三 构造状态序列, 吸收新的input
input 和 原来的state 通过W和b融合之后形成了新的state
# 这是state每次吸收新的input的时候 用到的权重
W = tf.Variable(np.random.rand(state_size+1, state_size), dtype=tf.float32)
b = tf.Variable(np.zeros((1,state_size)), dtype=tf.float32)
state_size = 4
batch_size = 5
# state的结构是 (5,4) ,保持不变
init_state = tf.placeholder(tf.float32, [batch_size, state_size])
current_state = init_state
states_series = []
# 提示:inputs_series是一个长度为15的list,list中的每一项是一个长度为5的array
# 这15个placeholder进行一些操作
# 把输入序列(placeholder) 映射成 state序列, 加入了 w 和 b
for current_input in inputs_series:
# 对placeholder的每一项"current_input"进行reshape
# current_input是15list中的一项,这一项中是5(batch_size)length的array
# reshape以后,这个一维的shape为(batch_size,)的数组,变成了一个二维的,shape为(batch_size,1)的数组
# 5x1
# current_input: (5,) ==> (5,1)
current_input = tf.reshape(current_input, [batch_size, 1])
# 把当前输入项 和 当前状态合并,1表示列
# current_state: (5,4)
# current_input: (5,1)
# 在第1维上合并,从0开始算,所以,合并之后是(5,5), 行数不变,多了一列
input_and_state_concatenated = tf.concat([current_input, current_state],1)
# 矩阵乘法 (5,5) x (5,4) ==> (5,4)
# 合并后的5行5列 通过矩阵乘法 又变成了5行4列,和之前的state的结构一样
# input 和 原来的state通过W和b,融合之后形成了新的state
next_state = tf.tanh(tf.matmul(input_and_state_concatenated, W) + b)
# 把这个新的state放进一个数组
states_series.append(next_state)
current_state = next_state
# 虽然还没有输入具体的值,我们先把placeholderX ==映射成==> states_series,
# 每次placeholderX的输入不同,所以这个结构里填的值不同
四 计算误差和训练
得到一个预测结果,然后跟labels比较计算cross_entropy作为loss
然后根据loss来优化W、b 和 W2、b2
W2 = tf.Variable(np.random.rand(state_size, num_classes),dtype=tf.float32)
b2 = tf.Variable(np.zeros((1,num_classes)), dtype=tf.float32)
# 通过W2和b2两个参数 与 state 矩阵相乘 ==得到==> 一个(5,2)的数组,
# 这里的加法是Broadcasted addition,
# 代表了当前的预测结果
logits_series = [tf.matmul(state, W2) + b2 for state in states_series]
# tf.nn.sparse_softmax_cross_entropy_with_logits
# 常规用法是logits的shape为[batch_size, num_classes],labels的shape是[batch_size]
# labels是一个一维的list,必须为整数,不能大于num_classes,比如说你有3个类别,labels最大为2
# 这个函数会自动帮你执行softmax,所以不要自己执行softmax
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels) for logits, labels in zip(logits_series,labels_series)]
# tf.reduce_mean(loss)把这个数组的值平均了一下
total_loss = tf.reduce_mean(losses)
# 用Adagrad作为optimizer
train_step = tf.train.AdagradOptimizer(0.3).minimize(total_loss)
# tf.nn.softmax... 手动百度:“多类分类下为什么用softmax?”
predictions_series = [tf.nn.softmax(logits) for logits in logits_series]
五 运行训练
# 训练100轮
num_epochs = 100
# 每一轮的数据 分成了num_batches块
num_batches = total_series_length//batch_size//truncated_backprop_length
with tf.Session() as sess:
#初始化变量
sess.run(tf.global_variables_initializer())
# 训练100轮
for epoch_idx in range(num_epochs):
x,y = generateData() #产生随机数据
_current_state = np.zeros((batch_size, state_size)) #初始状态
print("New data, epoch:", epoch_idx)
# 前面不是把数据变成5行10000列,现在一截截切开
for batch_idx in range(num_batches):
# 保持5行不变,每次截取truncated_backprop_length的长度
# 看来stride为5, 每一节之间没有重叠
start_idx = batch_idx * truncated_backprop_length
end_idx = start_idx + truncated_backprop_length
batchX = x[:,start_idx:end_idx]
batchY = y[:,start_idx:end_idx]
# 把切好的数据喂给session
_total_loss, _train_step, _current_state, _predictions_series = sess.run(
[total_loss, train_step, current_state, predictions_series],
feed_dict={
batchX_placeholder:batchX,
batchY_placeholder:batchY,
init_state:_current_state
})
loss_list.append(_total_loss)
# 每一百次打印一下
if batch_idx%100 == 0:
print("Step",batch_idx, "Loss", _total_loss)
plot(loss_list, _predictions_series, batchX, batchY)六 展示图表
def plot(loss_list, predictions_series, batchX, batchY):
plt.subplot(2, 3, 1) # 返回axes,2行 3列 中的第1幅图
plt.cla() #清除当前axes
plt.plot(loss_list)
for batch_series_idx in range(5): #那5根葱...现在一根一根的看
# 对list里所有predictions选择 第batch_series_idx个,
# 选择第 batch_series_idx 跟葱
one_hot_output_series = np.array(predictions_series)[:, batch_series_idx, :]
# 把最后那个2维的 处理下
single_output_series = np.array([(1 if out[0] < 0.5 else 0) for out in one_hot_output_series])
# 每根葱对应一个axe
plt.subplot(2, 3, batch_series_idx + 2)
plt.cla()
# 坐标轴 0到15, 0到2
plt.axis([0, truncated_backprop_length, 0, 2])
#这个是啥, 横坐标嘛
left_offset = range(truncated_backprop_length)
plt.bar(left_offset, batchX[batch_series_idx, :], width=1, color="blue")
plt.bar(left_offset, batchY[batch_series_idx, :] * 0.5, width=1, color="red")
plt.bar(left_offset, single_output_series * 0.3, width=1, color="green")
plt.draw()
plt.pause(0.0001)七 所有代码
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
num_epochs = 100
total_series_length = 50000
truncated_backprop_length = 15
state_size = 4
num_classes = 2
echo_step = 3
batch_size = 5
num_batches = total_series_length//batch_size//truncated_backprop_length
def generateData():
x = np.random.choice(2, total_series_length, p=[0.5, 0.5])
y = np.roll(x, echo_step)
y[0:echo_step] = 0
x = x.reshape((batch_size, -1))
y = y.reshape((batch_size, -1))
return (x, y)
batchX_placeholder = tf.placeholder(tf.float32, [batch_size, truncated_backprop_length])
batchY_placeholder = tf.placeholder(tf.int32, [batch_size, truncated_backprop_length])
init_state = tf.placeholder(tf.float32, [batch_size, state_size])
W = tf.Variable(np.random.rand(state_size+1, state_size), dtype=tf.float32)
b = tf.Variable(np.zeros((1,state_size)), dtype=tf.float32)
W2 = tf.Variable(np.random.rand(state_size, num_classes),dtype=tf.float32)
b2 = tf.Variable(np.zeros((1,num_classes)), dtype=tf.float32)
# Unpack columns
inputs_series = tf.unstack(batchX_placeholder, axis=1)
labels_series = tf.unstack(batchY_placeholder, axis=1)
# Forward pass
current_state = init_state
states_series = []
for current_input in inputs_series:
current_input = tf.reshape(current_input, [batch_size, 1])
input_and_state_concatenated = tf.concat([current_input, current_state],1) # Increasing number of columns
next_state = tf.tanh(tf.matmul(input_and_state_concatenated, W) + b)
states_series.append(next_state)
current_state = next_state
logits_series = [tf.matmul(state, W2) + b2 for state in states_series] # Broadcasted addition
predictions_series = [tf.nn.softmax(logits) for logits in logits_series]
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels) for logits, labels in zip(logits_series,labels_series)]
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdagradOptimizer(0.3).minimize(total_loss)
def plot(loss_list, predictions_series, batchX, batchY):
plt.subplot(2, 3, 1)
plt.cla()
plt.plot(loss_list)
for batch_series_idx in range(5):
one_hot_output_series = np.array(predictions_series)[:, batch_series_idx, :]
single_output_series = np.array([(1 if out[0] < 0.5 else 0) for out in one_hot_output_series])
plt.subplot(2, 3, batch_series_idx + 2)
plt.cla()
plt.axis([0, truncated_backprop_length, 0, 2])
left_offset = range(truncated_backprop_length)
plt.bar(left_offset, batchX[batch_series_idx, :], width=1, color="blue")
plt.bar(left_offset, batchY[batch_series_idx, :] * 0.5, width=1, color="red")
plt.bar(left_offset, single_output_series * 0.3, width=1, color="green")
plt.draw()
plt.pause(0.0001)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
plt.ion()
plt.figure()
plt.show()
loss_list = []
for epoch_idx in range(num_epochs):
x,y = generateData()
_current_state = np.zeros((batch_size, state_size))
print("New data, epoch", epoch_idx)
for batch_idx in range(num_batches):
start_idx = batch_idx * truncated_backprop_length
end_idx = start_idx + truncated_backprop_length
batchX = x[:,start_idx:end_idx]
batchY = y[:,start_idx:end_idx]
_total_loss, _train_step, _current_state, _predictions_series = sess.run(
[total_loss, train_step, current_state, predictions_series],
feed_dict={
batchX_placeholder:batchX,
batchY_placeholder:batchY,
init_state:_current_state
})
loss_list.append(_total_loss)
if batch_idx%100 == 0:
print("Step",batch_idx, "Loss", _total_loss)
plot(loss_list, _predictions_series, batchX, batchY)
plt.ioff()
plt.show()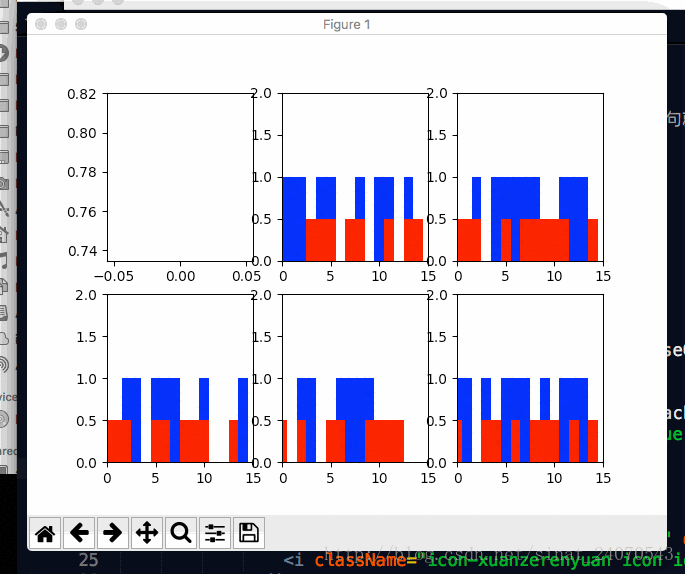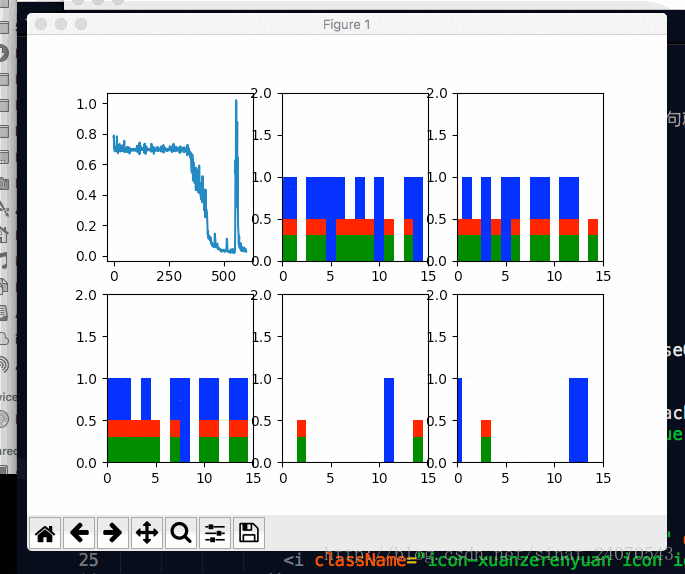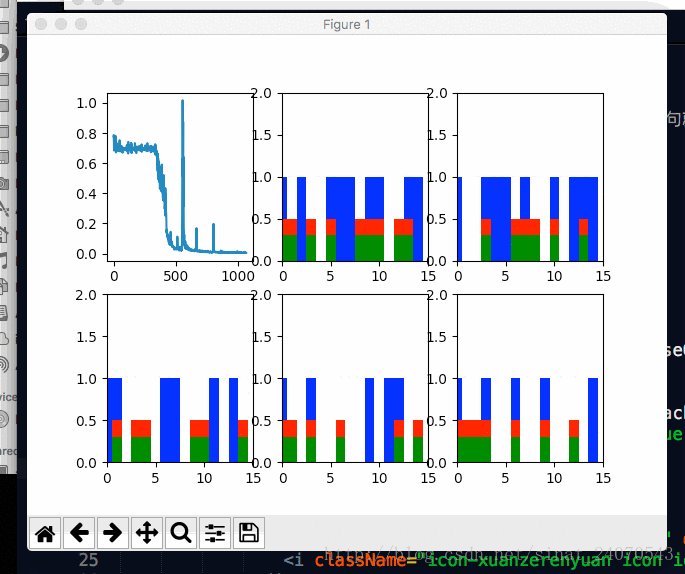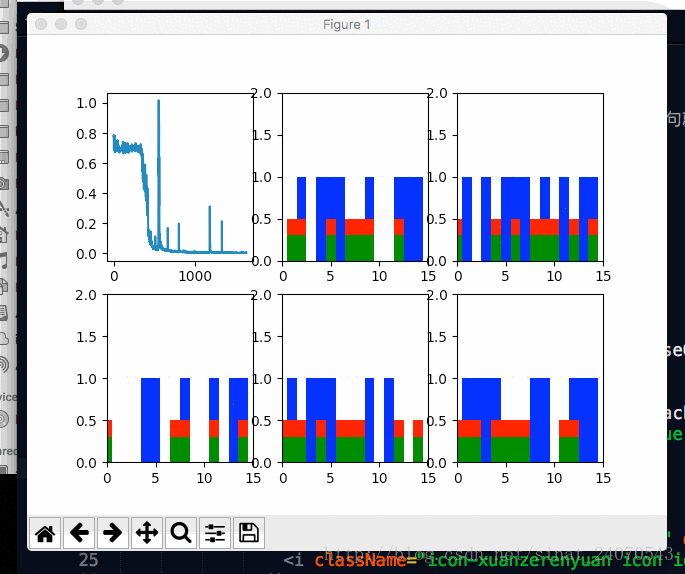
最后,
图(2,3,1)代表了损失随着训练次数的变化,
发现损失曲线会有尖峰,精确来说是每隔666次会有一次尖峰,
原因是每隔666次,会重新产生一次新的数据,
新老数据之间没有关系,所以预测会失败
下一步
TensorFlow搭建RNN(2/7) 使用TensorFlow的RNN API
原文来自medium:
https://medium.com/@erikhallstrm/hello-world-rnn-83cd7105b767
原文的翻译:
https://zhuanlan.zhihu.com/p/26646665
本文根据tensorflow 1.2的api修改了代码