前言
现在的目标检测算法主要可以分为两类:
- two-stage,比如Fast R-CNN,Faster R-CNN,Mask R-CNN。它们首先生成一系列稀疏的候选区域,然后用CNN对每个候选区域进行分类,判断它们是属于前景中的某个类别,还是属于背景。现在这一类方法可以达到很高的精度,但是速度略有不足。
- one-stage,比如YOLO和SSD。它们对目标的位置、尺度和长宽比进行规则的密集的采样,也就是anchor,但这一类方法虽然检测速度很高,但精度不及two-stage方法。
问题出在哪里呢?本文认为,训练过程中的类别不平衡问题是妨碍one-stage方法达到较高检测精度的主要原因。
那么什么是类别不平衡呢? 在检测过程中会生成许多边界框(bounding box),而一般设定与真实框(ground truth)之间的IoU达到某个阈值的边界框才能被作为正样本(positive),其余都是负样本。而一个输入图像中的目标只有那么几个,因此绝大多数的边界框都是负样本(negative),也就是背景。这就会造成正负样本之间的不平衡。
类别不平衡为什么会导致检测精度降低呢? 类别不平衡会造成training loss被占绝大多数但包含信息量很少的负样本所支配,而少量的正样本不能在training loss中发挥正常的作用,因此这个loss并不能对模型有一个正确的指导。
two-stage方法是如何处理类别不平衡问题的呢? 在生成候选区域阶段,会迅速将候选框的数量缩减到一个较小的值,并过滤出绝大多数的背景样本。然后在分类阶段进行启发式采样,例如将前景与背景的样本比例固定为3:1,或者用OHEN(online hard example mining)方法。这可以使前景与背景样本之间达到一个平衡。
one-stage方法在处理类别不平衡问题上为何不行呢? one-stage方法会生成更多密集的候选框,实际中经常达到100000个。然而数量如此之多的候选框里,绝大多数都是不包含目标的背景,因此训练过程会被这些信息量很少的负样本所支配。这就是目标检测中的正负样本不平衡的经典问题。一般常用的解决方法是通过bootstrapping或者hard example mining。
本文提出了一种新的损失函数focal loss,这是一个能够动态缩放的交叉熵损失函数(dynamically scaled cross entropy),当正确类别的置信度提高时,缩放因子(scaling factor)
会衰减为0。这个
会自动降低训练时easy样本(类别比较明确的样本) 对loss所做的贡献的权重,并迅速的使模型更关注hard样本(类别不易区分的样本)。

上图可以看到, 是添加到标准交叉熵损失函数(CE)上的一个权重,当 时,会降低easy样本的loss,使模型更关注hard样本。实验证明,即使有大量的easy样本,focal loss也能在密集的目标检测中达到很高的精度。
Focal Loss
1. CE(cross entropy)loss
focal loss是用来处理one-stage目标检测方法中前景和背景类别极度不平衡的问题的。首先介绍一下用于二分类的交叉熵损失函数(cross entropy,CE)。
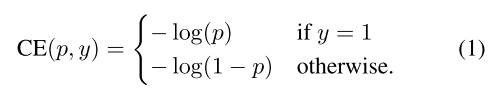
其中,
{±1}指定了ground-truth类别,
是带有
标记的类别的估计概率。
被定义为:

于是
(
(
)
在CE loss中,easy样本会在loss中占据大部分。当把大量easy样本加起来时,这些对loss影响较小的样本能超过稀有的hard样本对loss的影响。
2. balanced CE loss
处理类别不平衡问题我们一般会想到加入一个权重系数
,该系数与目标存在的概率成反比。
的定义与
的定义类似,因此
balanced CE loss为:

作者将上式作为focal loss的baseline
3. focal loss
在训练时,loss由easy negative样本主导,
虽然能平衡positive/negative样本,但不能区分easy/hard样本。而最好的结果是降低easy样本的权重,让模型更关注hard negetive样本。因此在CE loss上添加调制系数(modulating factor)
,其中焦点参数(focusing parameter)
大于等于0。focal loss被定义为:

- 当一个样本是hard positive时,调制系数接近1并且损失基本不受影响。当 ,即是negative样本时, 变为0并且easy样本所占的权重明显下降。
-
平滑地调节了easy样本的权重下降率。当
增加时,调制系数的效果也会增强,如下图。本文中
时达到最佳效果

调制系数减少了easy样本的loss,虽然easy positive样本的loss也略有下降,但由于easy negative的loss大幅下降,所以相对于easy positive样本的loss来说其实是一种增强。关于各种样本loss的增减可以看下表:
| loss | 数量较多的样本(negative) | 数量较少的样本(positive) |
|---|---|---|
| easy(被正确分类)样本 | 大幅下降 | 稍微下降 |
| hard(被错误分类)样本 | 稍微下降 | 基本不变 |
可以看到focal loss使得整体的loss是下降的,但由于negative样本的loss减少的更多,因此还是由positive样本的loss占主导地位的。这样做也使得easy negative样本的loss对training loss的贡献更少,而不至于不采用全部的easy negative。
通过实验发现,加上
后的精度更高:

上式是focal loss最终的形态。
RetinaNet
RetinaNet由一个主网络和两种子网络构成。主网络是一个现成的神经网络,负责从输入图像上计算出卷积特征图。第一种子网对主网络的输出进行目标分类,第二种子网负责边界框回归,如下图所示。这是个one-stage的目标检测模型。接下来介绍一下各部分的内容。

1.FPN主网络
采用FPN作为RetinaNet的主网络。FPN从一个单一尺度的输入图像中,通过一条top-down通路和横向连接构成了一个多尺度的特征金字塔,因此可以在多尺度特征图上进行目标检测。实验中是在ResNet的顶层构建FPN,特征金字塔的层级是从 到 ,输入图像的分辨率是 层特征图的 倍, 表示特征金字塔的层级。和FPN一样,特征金字塔中每个层级的特征图的通道数都是 。这里的FPN和原始FPN略有不同:
- 到 是通过相应的ResNet残差段( 到 )的输出计算得到的,和FPN一样也是用了top-down通路和横向连接。
- 是通过在 上经过一个步长为2的3×3卷积层得到的,而不是通过下采样得到的。
- 是通过对 应用ReLU激活函数,后面跟一个步长为2的3×3卷积层得到的。 主要是用来增强对大目标的检测。
- 没有原始FPN中分辨率最高的 。
2.anchor
在 到 层级中,每层的anchor面积是从 到 ,长宽比有三种{1:2,1:1,2:1}。因为比FPN中覆盖的尺度更密集,因此每层的anchor有三种不同的size{ , , },这样每层的anchor数量为 ,并且相对于输入图像来说,这些anchor涵盖的尺度是32-813像素。
每个anchor对应一个长度为K的向量作为分类信息(K是目标类别的数量),和一个长度为4的向量作为边界框回归信息。当anchor与ground-truth的IoU大于等于0.5时,这一类anchor就是正样本;若IoU在[0,0.4)这个区间内,这一类anchor就是负样本,也就是背景。IoU在[0.4,0.5)这个区间内的anchor在训练时是忽略不计的。边界框回归信息是每个anchor和它附近的ground-truth box之间的偏移值。
3.分类子网
这个子网其实是一个小型FCN,FPN中的每一层都要连一个分类子网,每个层级的子网之间的参数是共享的。这个子网包含4个3×3的卷积层,每个卷积层的filter数量为C,激活函数是ReLU;后面是一个3×3的卷积层,filter数量为KA。最后用sigmoid激活函数为每个层级输出KA个二分类预测值。为什么是KA个预测值呢? 因为每个层级有A个anchor,每个anchor要为目标预测属于每个类别(总共有K个类别)的概率,概率最高的那个类别就是目标所属的类别。最后用sigmoid函数进行二分类,判断目标属于或不属于某个类别,因此最后有KA个二分类预测值。注意,分类子网和边界框回归子网之间是不共享参数的。
4.边界框回归子网
这个子网也是一个小型FCN,它和分类子网是同级的,也就是说每个层级后面同时连接一个分类子网和边界框回归子网。它的结构与分类子网完全相同,只是最后是4A个线性输出。对于每个层级的A个anchor来说,这4个输出值预测了anchor和它附近的ground-truth box之间的偏移值。
RetinaNet的训练
RetinaNet最终由ResNet-FPN作为主网络,后面是两种类型的子网。输入图像在网络中向前传播后,要对最后预测的边界框进行处理。为了提高检测速度,对FPN每个层级上目标存在概率最高的前1000个边界框进行编码。接下来将这些边界框汇集起来,进行阈值为0.5的NMS处理,这样就得到了最终的检测结果。
最终的focal loss是在所有anchor上的focal loss之和,用与ground-truth对应的anchor的数量进行归一化,而不是所有的anchor,这是因为大多数anchor都是负样本,它们的loss在最终的focal loss中可以忽略不计。
下图为RetinaNet的检测精度与性能

RetinaNet-50是基于ResNet-50-FPN,RetinaNat-101是基于ResNet-101-FPN,可以看到,无论是检测精度还是速度,RetinaNet都表现得更好。
