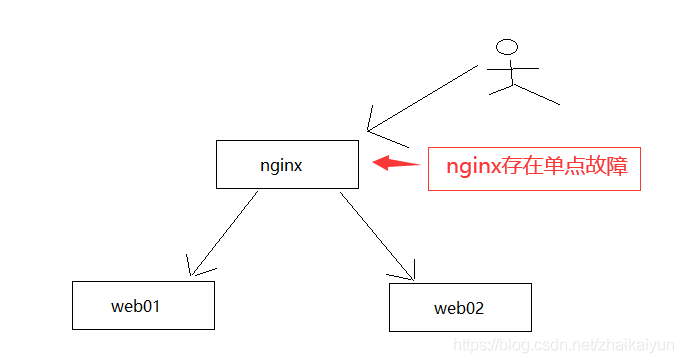
背景
通常情况下,利用nginx进行负载均衡,使后端服务高可用,某个后台服务出现问题可以动态剔除,不影响系统的正常运行,但是nginx只有一个,这时候是个瓶颈,会出现单点故障,nginx出现问题,服务将会出现中断,影响系统的正常运行。
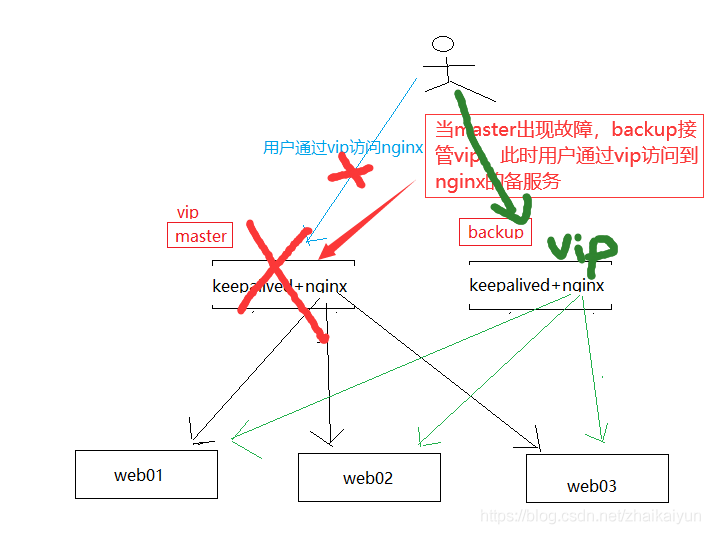
keepalived解决nginx单点问题
利用keepalived故障切换转移的功能,部署多个nginx服务,比如两个,一个master对外服务,另外一个处于backup热备服务,对外通过vip进行访问。当master服务出现问题的时候,backup热备服务的机器将会动态接管vip,接管vip后backup热备服务将会对外服务,从而解决nginx单点故障问题。
keepalived配置
[root@k8snode01 keepalived]# more keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL_01
}
vrrp_script chk_http_port {
script "/etc/keepalived/check_ng.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER #备机为BACKUP
interface ens33
virtual_router_id 100
priority 100 #备机为50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
track_script {
chk_http_port
}
virtual_ipaddress {
192.168.23.200
}
}
[root@k8snode01 keepalived]#
[root@k8snode01 keepalived]# more check_ng.sh #nginx检查脚本
#!/bin/bash
currdate=`date '+%Y-%m-%d %H:%M:%S'`
count=`ps -aux | grep -v grep | grep 'nginx.conf' | wc -l`
echo "${currdate}---->ok:${count}" >>/etc/keepalived/checkng.log
result=$(echo "000${count}" | grep "0000")
if [[ "$result" != "" ]]; then
echo "${currdate}---->/etc/init.d/keepalived stop" >>/etc/keepalived/checkng.log
/etc/init.d/keepalived stop
exit 1
else
exit 0
fi
[root@k8snode01 keepalived]# more notify.sh #切换主备通知脚本
#!/bin/bash
currdate=`date '+%Y-%m-%d %H:%M:%S'`
echo "${currdate}---->${1}" >>/etc/keepalived/notify.log
[root@k8snode01 keepalived]#
故障演练
1)查看vip,vip在192.168.23.101机器上
[root@k8snode01 keepalived]# ip addr #vip在192.168.23.101机器
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a3:b8:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.23.101/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.23.200/32 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode01 keepalived]#
[root@k8snode02 ~]# ip addr #192.168.23.102机器无vip
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:32:05:d5 brd ff:ff:ff:ff:ff:ff
inet 192.168.23.102/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode02 ~]#
2)使用实ip访问nginx,为了演示方便,192.168.23.101的nginx返回192.168.23.101,192.168.23.102的nginx返回192.168.23.102
[root@k8snode02 ~]# curl "192.168.23.101:8888" #返回nginx所在机器的ip
192.168.23.101
[root@k8snode02 ~]# curl "192.168.23.102:8888" #返回nginx所在机器的ip
192.168.23.102
[root@k8snode02 ~]#
3)使用vip访问nginx,正常应该返回vip所在机器的实ip,此时返回192.168.23.101
[root@k8snode02 ~]# curl "192.168.23.200:8888" #返回vip所在机器的ip
192.168.23.101
[root@k8snode02 ~]# curl "192.168.23.200:8888" #返回vip所在机器的ip
192.168.23.101
[root@k8snode02 ~]# curl "192.168.23.200:8888" #返回vip所在机器的ip
192.168.23.101
[root@k8snode02 ~]#
4)模拟主的nginx故障,可以把192.168.23.101机器关闭或停止nginx服务,使vip漂移到192.168.23.102,让备nginx接管服务
[root@k8snode01 keepalived]# ps -ef|grep nginx #查看nginx进程
root 23081 1 0 08:11 ? 00:00:00 nginx: master process /data/nginxinstall/sbin/nginx -c /data/nginxinstall/conf/nginx.conf
nobody 23082 23081 0 08:11 ? 00:00:00 nginx: worker process
root 28703 24828 0 08:30 pts/1 00:00:00 grep --color=auto nginx
[root@k8snode01 keepalived]# pkill nginx #停止nginx进程
[root@k8snode01 keepalived]# ps -ef|grep nginx #nginx进程已停止
root 28746 24828 0 08:30 pts/1 00:00:00 grep --color=auto nginx
[root@k8snode01 keepalived]# ip addr #192.168.23.101机器的vip消失
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a3:b8:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.23.101/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode01 keepalived]#
[root@k8snode02 ~]# ip addr #vip漂移到192.168.23.102
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:32:05:d5 brd ff:ff:ff:ff:ff:ff
inet 192.168.23.102/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.23.200/32 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode02 ~]#
[root@k8snode02 ~]# curl "192.168.23.200:8888" #被nginx192.168.23.102正常接管服务
192.168.23.102
[root@k8snode02 ~]# curl "192.168.23.200:8888" #被nginx192.168.23.102正常接管服务
192.168.23.102
[root@k8snode02 ~]#
5)将192.168.23.101机器的nginx和keepalived服务拉起,由于192.168.23.101机器优先级高,将抢占vip
[root@k8snode01 keepalived]# /data/nginxinstall/sbin/nginx -c /data/nginxinstall/conf/nginx.conf #启动nginx
[root@k8snode01 keepalived]# /etc/init.d/keepalived start #启动keepalived
Starting keepalived (via systemctl): [ OK ]
[root@k8snode01 keepalived]# ip addr #vip抢占在192.168.23.101
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a3:b8:9f brd ff:ff:ff:ff:ff:ff
inet 192.168.23.101/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.23.200/32 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode01 keepalived]#
[root@k8snode02 ~]# ip addr #192.168.23.102上的vip消失
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:32:05:d5 brd ff:ff:ff:ff:ff:ff
inet 192.168.23.102/24 brd 192.168.23.255 scope global ens33
valid_lft forever preferred_lft forever
[root@k8snode02 ~]#
[root@k8snode02 ~]# curl "192.168.23.200:8888" #主nginx抢占服务
192.168.23.101
[root@k8snode02 ~]# curl "192.168.23.200:8888" #主nginx抢占服务
192.168.23.101
[root@k8snode02 ~]#
