这一节我们主要通过一个生产者与消费者的问题来学习一下.NET Framework 4之后添加的并发集合的相关内容,同时也小小地复习一下之前所学种种。
当多个线程对某个非线程安全容器并发地进行读写操作时,这些操作将导致不可预估的后果或者会导致报错。为了解决这个问题我们可以使用lock关键字或者Monitor类来给容器上锁。但锁的引入使得我们的代码更加复杂,同时也带来了更多的同步消耗。而.NET Framework 4提供的线程安全且可拓展的并发集合能够使得我们的并行代码更加容易编写,此外,锁的使用次数的减少也减少了麻烦的死锁与竞争条件的问题。.NET Framework 4主要提供了如下几种并发集合:BlockingCollection,ConcurrentBag,ConcurrentDictionary,ConcurrentQueue,ConcurrentStack。这些集合通过使用一种叫做比较并交换(compare and swap, CAS)指令和内存屏障的技术来避免使用重量级的锁。
这里以ConcurrentQueue为例,考虑一个生产者与消费者协同工作的情形:生产者producer不断地生产元素并将其放到一个并发集合容器里,消费者consumer与之并行工作,不断地将该容器中的元素取出来消费。

在ProducerMethod中我们使用了之前学习过的并发循环Parallel.ForEach,为了便于观察我们令其生产500个元素,并将其放置到缓存区bufferArea尾部中去,在ConsumerMethod中,我们使用ConcurrentQueue.TryDequeue()方法来不断地从缓冲区头部取出元素并放到另一个我们准备好的容器repos中去,同时打印一下bufferArea中滞留的元素个数。注意ProducerMethod方法中我们使用了之前没有提及的ParallelOption对象,通过使用ParallelOption对象可以设置并行循环的一些属性,这里我们设置的是其最大并行度(即传入的maxDegree)值。
Main方法如下,设置生产者任务中Parallel.ForEach的最大并行度为逻辑内核数,在我的机器上是4。任务完成后我们打印出repos中的元素个数:

运行过程中我们观察到由于producer和consumer速度的不同步bufferArea中滞留的元素最多达到了300多个,我们可以通过优化两者的执行耗时来改进这一点(例如将consumer消费的速度改为100ms,滞留的元素数量将大大减少):


这只是单生产者-单消费者的情况,实际应用中我们可能遇到更复杂的多对多的情况,以及生产-消费流水线的情况。下面考虑一个简单的1-2-1生产链,由一个生产者不断的生产元素并放置到bufferArea中,两个消费者并行地从中取出元素并放置到另一个并发容器repos中去,最后还有一个消费者,需要并行的从repos中消费一定的元素。
这里我们将最后的消费者称为Validator,并设置了一个由consumer任务和validator任务共享的变量runningConsumerCount,它将用来通知validator是否继续工作。
下为validator方法:

下为main方法,注意我们并没有使用简单的自增自减运算符,而是使用了System.Threading.InterLock的静态方法Increment和Decrement,它提供了原子级的给多个异步操作共享的某变量(在这里是runningConsumerCount)增减值的方法。
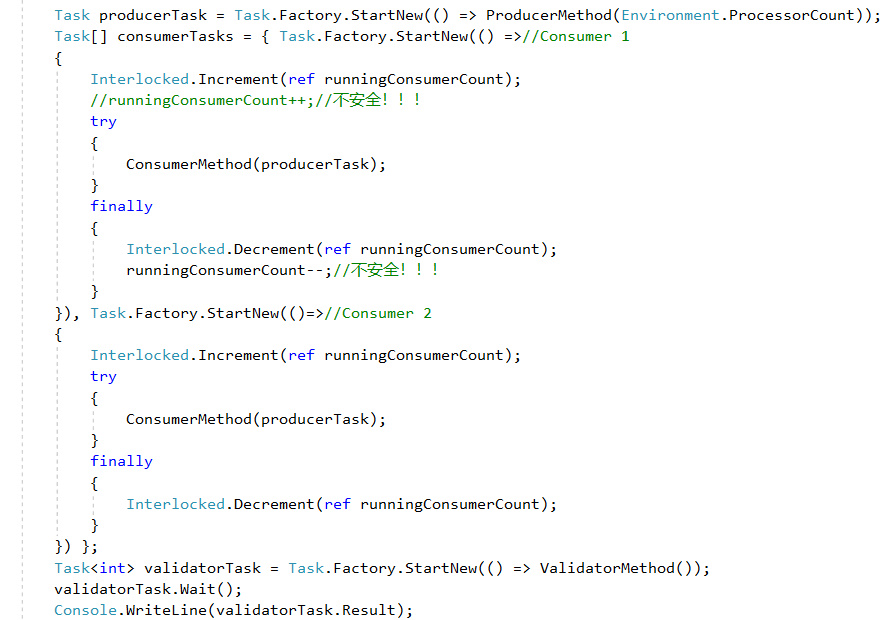
validator的任务是不断从repos中取出元素,并计算其中偶数的个数。运行结果如下:


两个consumer使得bufferArea中元素的滞留情况改善了不少,最终输出的结果显示偶数个数为245,这符合我们的预期。
进一步探讨这个例子,我们留意到在producer,consumer,validator之间采用了不同的同步方式:
consumer传入producerTask本身,并通过其TaskStatus属性和bufferArea滞留元素个数来指示工作;
validatorTask与consumerTask之间有一个共享的runningConsumerCount计数,validator方法通过它和repos滞留元素个数来指示工作。
这些都是可以改进的地方。以producer与consumer之间的同步为例,我们免不了认为传producerTask对象给ConsumerMethod是不可取的行为,同时也觉得producerTask.Status == TaskStatus.WaitingToRun || producerTask.Status == TaskStatus.Running || !bufferArea.IsEmpty这样的判断语句有些冗长,为此我们同样可以设置一个共享变量,producerWorking,一个布尔值。所有任务开始时我们设置producerWorking为true,然后在ConsumerMethod方法开始处,我们使用System.Thread.SpinWait.SpinUntil()方法,它将不断自旋自身,直到条件(我们传入的producerWorking)满足才开始执行下面的语句。
这是修改后的ProducerMethod和ConsumerMethod:

这是修改后的main方法:

IProducerConsumerCollection和BlockingCollection
还有很多方法可以协调生产者与消费者动作的执行,自旋也并非良好的解决方案。并发集合中为此特定定义了一个用于该情形的接口IProducerConsumerCollection,它由ICollection,IEnumerable和IEnumerable<T>继承而来,公开了如下一些方法:
CopyTo
ToArray
TryAdd
TryTake
方法的意义比较明显,不再赘述。这里主要来学习BlockingCollection集合,它是对IProducerConsumerCollection实例的一个封装,支持限界(bound)和阻塞(block)功能。由于ConcurrentQueue等集合都实现了IProducerConsumerCollection接口,因此它们都可以封装在BlockingCollection中。
BlockingCollection默认封装了一个ConcurrentQueue对象,当然我们可以传入其他的并发集合。如果我们在构造时为一个BlockingCollection指定了最大容量(滞留数量),那么当集合容量达到这个数值时,生产者任务或线程将会被阻塞,直到有元素被消费者消费掉。我们需要在producer任务完成后调用BlockingCollection.CompleteAdding()方法来标志结束生产任务,这个方法使得BlockingCollection的IsAddingComplete属性被设置为true,但注意这时候集合中可能还有滞留的元素,直到这些滞留的元素被全部消费之后,BlockingCollection的IsComplete才会被设置为true。
还是上面的例子,这次采用BlockingCollection来制作我们的bufferArea,并设置最大滞留数量为20,再次改进后的ProducerMethod和ConsumerMethod方法如下:

运行时可以看到bufferArea中滞留的元素最大不会超过20个,但由于生产者任务的阻塞情况,耗时也变长了。


耗时长的异步操作往往需要设置一下超时取消之类的,关于取消依然建议使用CancellationTokenSource和CancellationToken。在实际应用中有一个情况需要留意,当取消某个生产者的任务之后,后续的消费者可能应该在消费掉所有已生产的元素之后再停止。
ConcurrentDictionary
最后将ConcurrentDictionary单独提出来学习一下。ConcurrentDictionary的特殊性在于:它不是完全无锁的。ConcurrentDictionary对于读操作是完全无锁的,但是当多个任务或线程在字典中添加或修改数据的时候,ConcurrentDictionary会使用细粒度的锁。
细粒度的锁:简单来说,Concurrent在某些操作需要用锁的时候,不会锁定整个集合,而是只锁住真正需要锁定的部分。这意味着即使同时有多个请求需要访问字典中的不同内容时,若它们访问的部分是由不同的锁保护的,它们就可以并行执行。
在ConcurrentDictionary的构造函数中可以为其指定能够并发更新字典的最大任务(线程)数concurrencyLevel,以及用于比较键的比较器comparer。ConcurrentDictionary值得关注的方法是AddOrUpdate。
public TValue AddOrUpdate(TKey key, Func<TKey, TValue> addValueFactory, Func<TKey, TValue, TValue> updateValueFactory);
public TValue AddOrUpdate(TKey key, TValue addValue, Func<TKey, TValue, TValue> updateValueFactory);
如果key不存在,那么该方法会在字典中添加一个新的键值对(使用addValueFactory或者addValue);如果已存在,可以通过updateValueFactory方法来生成不存在的键或者更新现有的键,因此updateValueFactory应返回的是键的新值。
//由于ConcurrentDictionary使用了锁,应当减少使用诸如Count,Keys,ToArray之类的方法和属性。