LINQ(Language Integrated Query)语言集成查询是一种基于C#和VB的扩展,它允许以查询数据库相同的方式来操作数据源,学习过SQL等结构化查询语言的同学可能了解起来会比较轻松。PLINQ,在LINQ的前面加上了一个Parallel,顾名思义在LINQ的基础上添加了并行化优势。下面通过一个例子来看看这一点:

这里我们创建了一个1到1亿的序列,注意我们使用的是ParallelEnumerable,它是Enumerable的并行版本,更适合于并行执行。然后分别用PLINQ方式和LINQ方式查询集合中的偶数,并倒序排列,最终打印出偶数个数,查询结果的首元素和耗时。
运行结果如下:

当数据量达到这个量级的时候并行查询很明显比起LINQ要快上不少,事实上,在运行到LINQ的部分时,我的电脑几乎是卡死的……
相比LINQ,PLINQ多了以下特定的方法:
AsOrdered(),由于并发执行的不可预测性,查询的过程先后顺序是无法确定的,使用AsOrdered()可以确保PLINQ在查询中保持原始序列的顺序,直到使用orderby子句对其进行改变或者使用AsUnordered()关闭为止;
AsParallel(),尽可能采用并行执行;
AsSequential(),尽可能串行执行,与传统的LINQ一样;
AsUnordered(),略;
ForAll(),与foreach有些类似,使用它我们就可以不需要自己再去建立Parallel.For之类的并行循环了,它与foreach的区别还是在于并行执行顺序的不可预测性;
WithCancellation(),允许我们使用取消标记来取消PLINQ;
WithDegreeOfParallelism(),指定并行度,PLINQ会根据可用内核总数和这个参数进行优化,默认情况下,PLINQ总是会试图使用所有的可用逻辑内核以达到最佳性能;
WithExecutionMode(),这个方法接受一个ParallelExecutionMode参数指定执行模式来指定执行模式。例如,即使有些并行化算法会导致比串行执行还要低的性能时,你也可以使用这个方法来强制并行化;
WithMergeOptions(),PLINQ会将数据源分解为多个分区并行执行,然后将各个结果合并到一起。可以使用此方法来提示PLINQ应该优先使用何种方式合并结果片段。这个方法接受一个ParallelMergeOptions参数,下为其成员:
AutoBuffered,在结果可以返回给消费者之前,PLINQ使用一个输出缓冲来积累结果,PLINQ能判断出合适的缓冲大小,以便既可以支持对结果的快速访问,又不耽误整体吞吐量;
Default,默认选项;
NotBuffered,PLINQ不使用输出缓冲来积累结果,因此,一旦结果可用,调用线程就可以访问到数据,从而减少了查询开始到出结果的耗时。但是,由于没有输出缓冲,每一个结果都需要单独合并,因此会增加整体的执行时间,尤其在查询结果需要被连续不断消费的时候;
FullyBuffered,PLINQ使用一个完整的缓冲来积累结果,调用线程要等待所有的结果都可用之后才能访问,这个选项增加了查询开始到出结果的时差,但是能够减少了单个数据项添加到结果中的同步开销。
归约操作
一般来说,PLINQ可以简化成对一个序列或者一个组中所有成员应用一个查询函数的过程,这个过程称之为归约操作,除了预设的Average,Max,Min,Sum等聚合函数以外,还提供了一个重载的Aggregate来允许我们自定义并行归约算法。这里以计算上述1亿个元素中偶数的平均值为例介绍一下其用法:
使用预设的Average聚合函数:

使用Aggregate:我们学习使用Aggregate最复杂的一种重载,它的参数分为4个部分:
seed初始值,
updateAccumulateFunc将要对分区中每个元素调用的方法,
combineAccumulateFunc合并每个分区的结果,
resultSelector根据合并的结果来算出最终的结果。
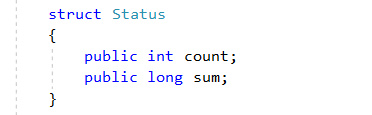
为了计算所有偶数的平均值,我们设置一个简单的struct,它有两个参数count和sum,count用于计算元素个数,sum用于计算元素和。如下图所示:

两种方式的运行结果如下:

PLINQ的应用之Map/Reduce
Map/Reduce思想对于接触过大数据的同学来说或许不陌生,Map/Reduce框架提示我们将数据处理问题分解为以下两个独立且可以并行执行的操作:
Map——映射,对杂乱无章的数据源进行操作,为每一个数据项计算出一个数值对,并根据键进行分组;
Reduce——对Map所产生的所有键值对进行归约操作。
考虑一个简单的例子,现有一个容量为1000000的单词集,需要我们以降序列出其中出现次数超过100000的单词(和其次数)。Map过程,使用PLINQ将集合按单词分组,这里使用了Lookup容器接口,它与Dictionary类似,但是提供的是键-值集映射;Reduce过程,使用PLINQ归约查询即可。

某一次运行结果如下:
Word: you, Count: 142416
Word: van, Count: 115816
Word: next, Count: 110228