目前所创建的表都是所谓的管理表,有时也被称为内部表,因为这种表,Hive会(或多或少地)控制着数据的生命周期。
当删除一个管理表时,Hive也会删除这个表中的数据,管理表不方便和其他工作共享数据。
内部表(internal table/managed table):
没有external修饰,表数据保存在Hive默认的路径下,数据完全由Hive管理,删除表时元数据和表数据都会一起删除。
外部表(external table):
有external修饰,表数据保存在HDFS上,该位置由用户指定。删除表时,只会删除表的元数据,所以外部表不是有Hive完全管理的。
区别:
- 内部表数据由Hive自身管理,外部表数据由HDFS管理
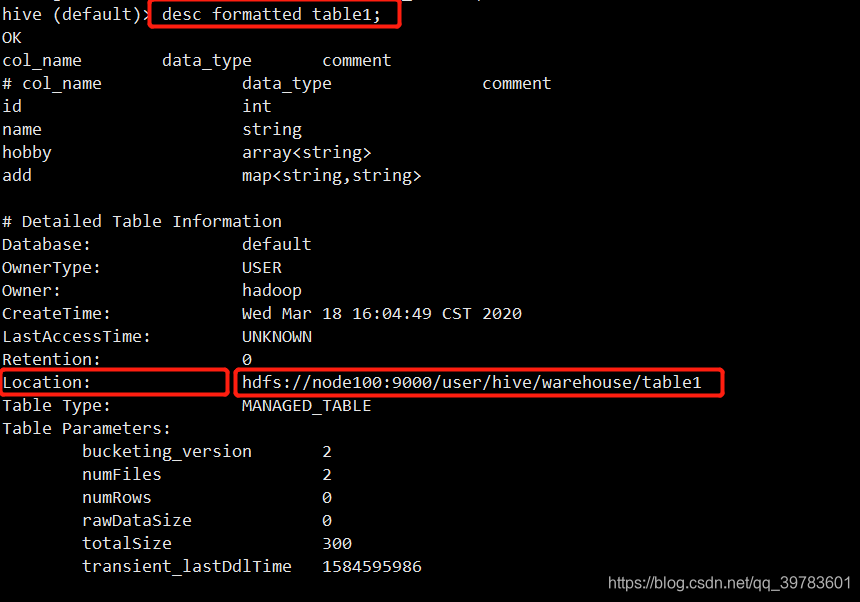
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse)
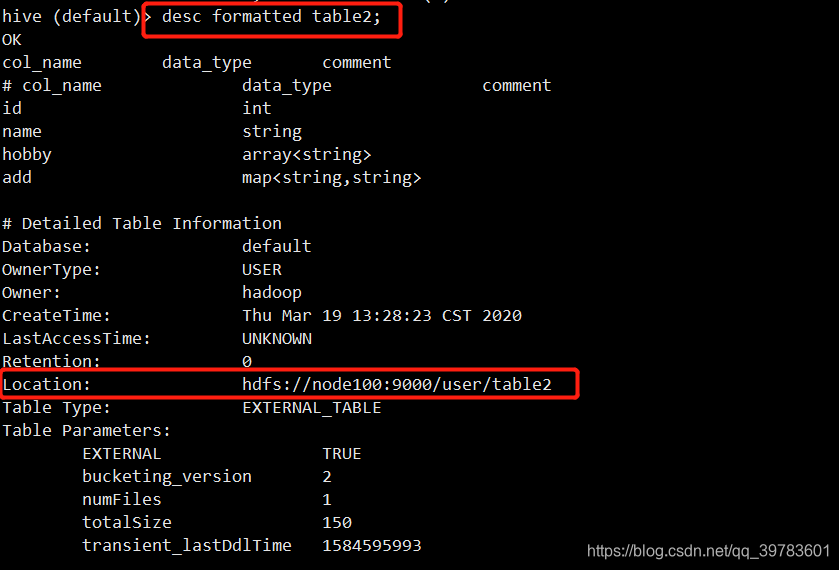
- 外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里)
- 删除内部表会直接删除元数据(metadata)及存储数据
- 删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除
- 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
使用场合:
1、希望做数据备份并且不经常改变的数据,存放在外部表可以减少失误操作。
2、数据清洗转换后的中间结果,可以存放在内部表,因为Hive对内部表支持的功能比较全面,方便管理。
3、处理完成的数据由于需要共享,可以存储在外部表,这样能够防止失误操作,增加数据的安全性。
4、在生产中一般创建外部表来存储数据。
举个例子便于理解
1、创建内部表table1:
create table table1(id int,name string,
hobby array<string>,addmap<String,string>)
> row format delimited
> fields terminated by ','
> collection items terminated by '-'
> map keys terminated by ':'
> ;

查看表的描述:desc table1;
desc table1;

装载数据(table1)
注意:
一般很少用insert 语句,因为就算插入一条数据,也会调用MapReduce。
可以直接使用HDFS上传文件到table1文件夹中,或者使用Hive的load命令。
这里我们选择Load Data的方式。
提前准备好一个txt文件,文件内容如下:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
这里穿插分享xshell如何上传文件到Linux服务器的方法
接下来导入数据:
LOAD Data local inpath '/home/hadoop/t1.txt' into TABLE table1;
下面显示导入成功

查看表的内容
select * from table1;
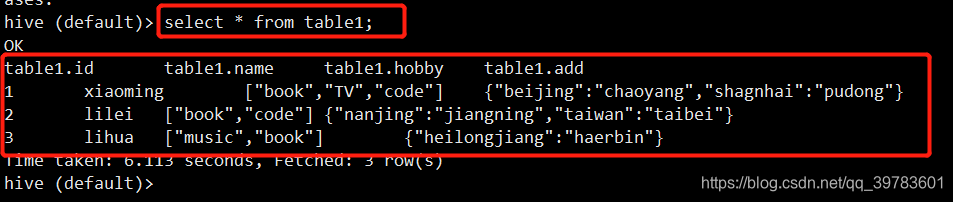
使用HDFS路径方式查看文件内容:
hadoop fs -cat /user/hive/warehouse/table1/t1.txt

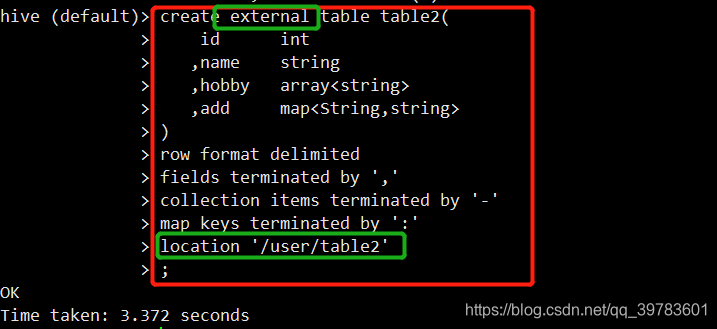
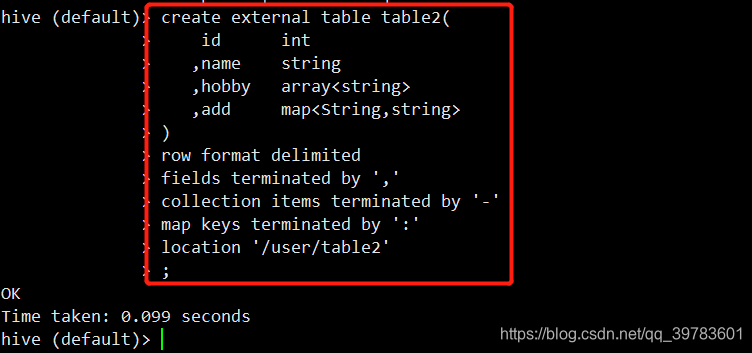
2、创建外部表table2
create external table table2(
id int
,name string
,hobby array<string>
,add map<String,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/user/table2'
;
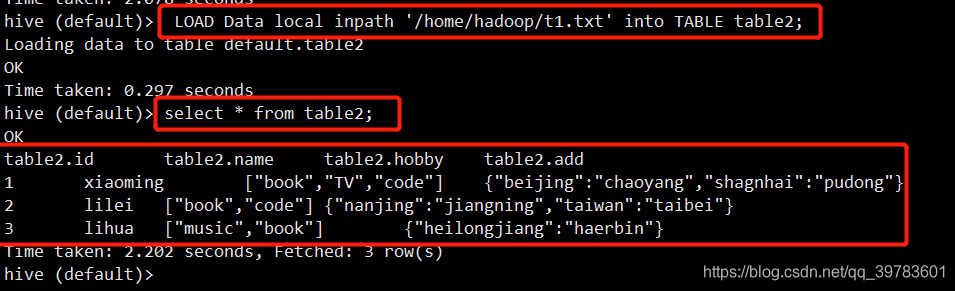
装载数据table2并查看文件内容:
LOAD Data local inpath '/home/hadoop/t1.txt' into TABLE table2;
select * from table2;
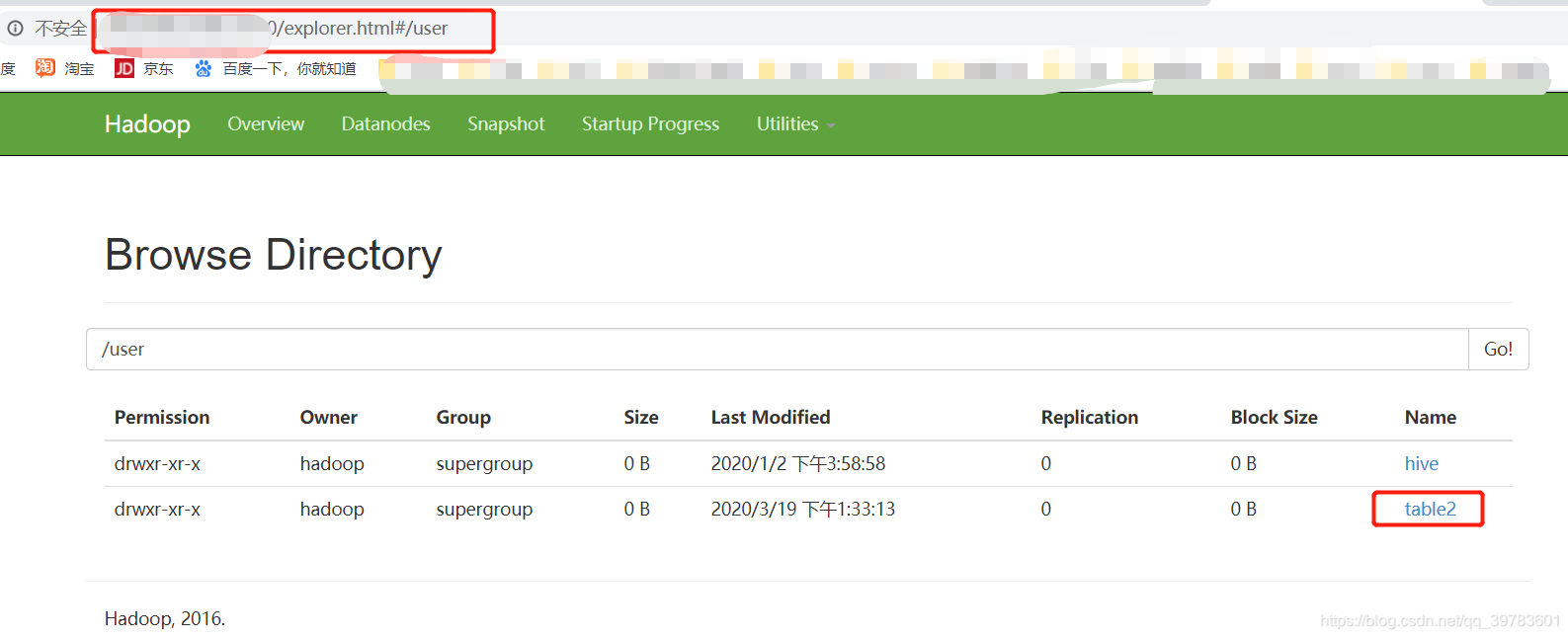
查看文件位置:
如下图,我们在http://192.168.5.100:50070/explorer.html#/user/目录下可以看到table2文件,也就是我们指定的文件路径(在建表时指定的location)。
现在我们查看下table1文件的位置在哪里?
table1在我们默认的路径下

我们也可以通过命令行获得两者的位置信息:
desc formatted tablename;
3、分别删除内部表和外部表
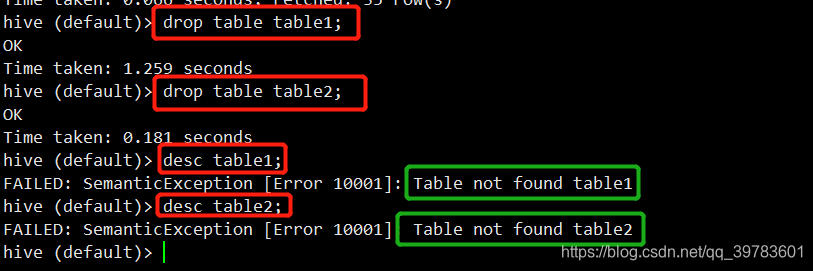
现在已经删除掉了,现在我们查看下HDFS的文件:
发现table1已经不存在了

但是table2仍然存在
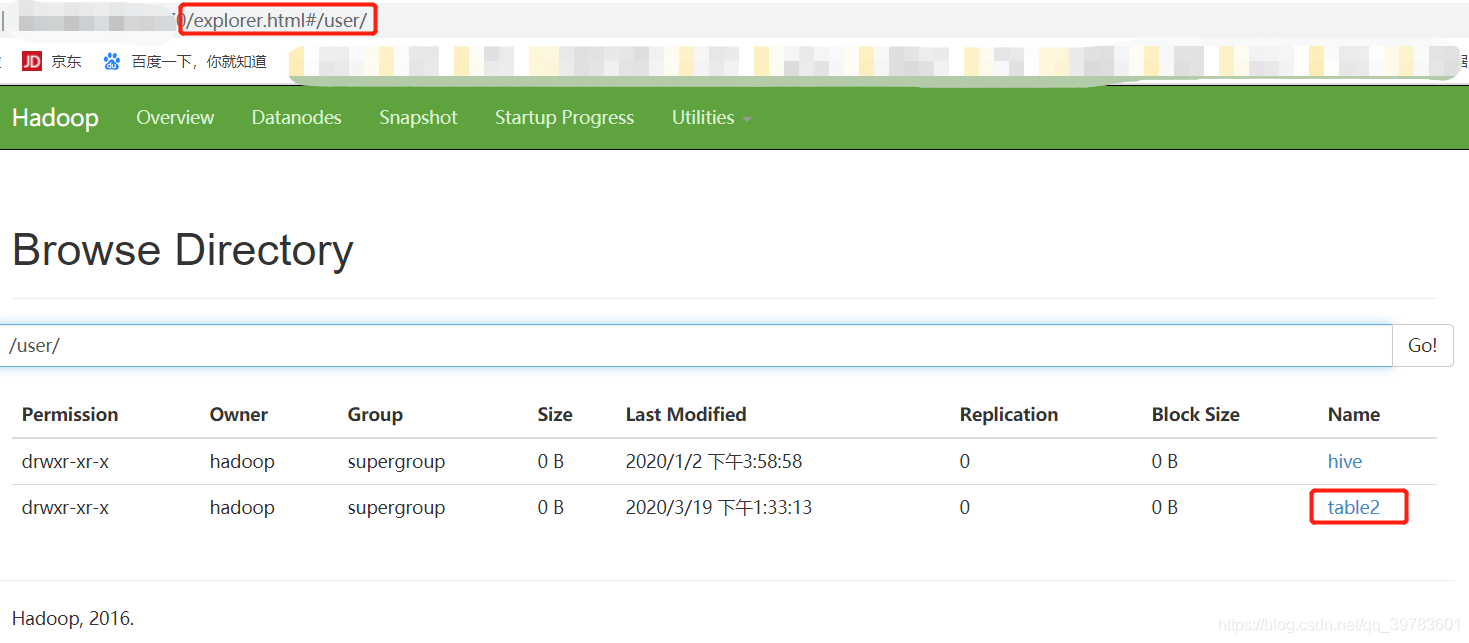
所以当我们删除外部表table2时,其实只是删除了table2 的元数据。
现在我们重新创建table2
不往里面插数据,我们查看下数据:
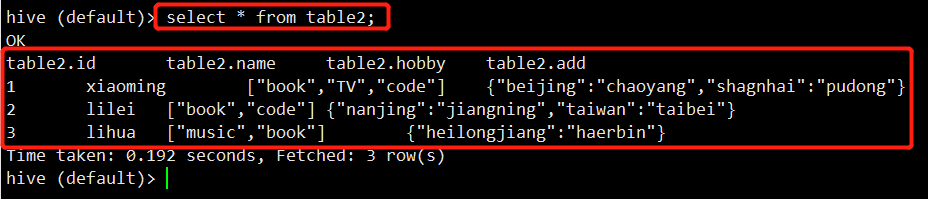
可以看到数据依然存在。
4、修改表
一般我们不会去修改表,直接重新映射一个新表即可。
修改表名
ALTER TABLE tablename RENAME TO new_tablename;
向表中添加列
ALTER TABLE tablename ADD COLUMNS (
app_name STRING COMMENT ' Application name ' ,
session_id LONG COMMENT ' The current session id');
修改列名
ALTER TABLE table_name change column_name new_column_name
new_type;
5、删除表
drop table if exists table_name;
6、清空表
truncate table tablename;
