1.mapReducer本地模式提交的搭建
1.1、将 Hadoop安装本地解压
1.2、配置 Hadoop的环境变量
添加%HADOOP_HOME%
修改%PATH%添加%HADOOP_HOME%/bin;%HADOOP_HOME%/sbin
1.3、在解压的 Hadoop的bin目录下添加 winutils.exe工具
Java工程
2.1、jdk一定要使用自己的jdk、不要使用 eclipse自带
2.2、根目录(src目录下),不要添加任何 Mapreduce的配置文件hdfs-site.xml yarn-site.xml core-site.xml mapred-site.xml
2.3、在代码当中,通过conf.set方式来进行指定。conf set(“fs.defaults”,“hdfs://活跃的namenode节点:8020”);
2.4、导入orgpackage
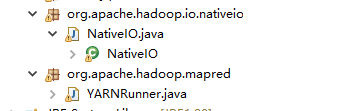
2.5修改Hadoop源码

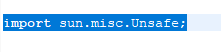
报错原因:使用了eclipse自带的JRE,需要切换成本地环境的JRE

 MRApps.addLog4jSystemProperties(logLevel, logSize, numBackups, vargs);注释掉,不然会报错。
MRApps.addLog4jSystemProperties(logLevel, logSize, numBackups, vargs);注释掉,不然会报错。
3、右键run执行
2.写mapReducer的job流程
1.获取配置文件
2.设置相关属性
3.获取job对象,设置相关值
4.设置输入源和输出源
5.设置mapper类
6.设置mapper的输出类型,key,value
7.设置分类器和比较器(可选)
8.设置reducer类
9.设置reducer的输出类型 key,value
10.提交job任务
3.实例:从hdfs获取数据统计(wordcount)结果写入Hbase00000000
代码:
主程序
package com.xjq.HdfsToHbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.generated.master.master_jsp;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class WCRunner {
public static void main(String[] args) throws Exception {
//配置文件
Configuration conf = new Configuration();
//设置连接zookeeper
conf.set("hbase.zookeeper.quorum", "node02,node03,node04");
//设置连接hdfs
conf.set("fs.defaultFS", "hdfs://node01:8020");
//获得job类
Job job = Job.getInstance(conf);
job.setJarByClass(WCRunner.class);
//设置mapper类
job.setMapperClass(WCMapper.class);
//mapper输出类型设置,key,value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//把数据写入hbase时,这个方法必须写
//String ,表名
// Class<? extends TableReducer> ,Reducer类
//Job job类
//Class arg3, String arg4, String arg5, String arg6, 源代码是null
//boolean 写false
TableMapReduceUtil.initTableReducerJob("wc", WCReducer.class, job, null, null, null, null, false);
//设置输入路径 这是从hdfs作为输入源
FileInputFormat.addInputPath(job, new Path("/usr/wc"));
//设置reducer输出格式
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Put.class);
//设置输入源和输出源
//job.setOutputFormatClass(cls);
//job.setInputFormatClass(cls);
//提交job作业
job.waitForCompletion(true);
}
}
Mapper类:
package com.xjq.HdfsToHbase;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] strs=value.toString().split(",");
for (String string : strs) {
context.write(new Text(string), new IntWritable(1));
}
}
}
Reducer类:
由于把结果写入Hbase所以Reducer类必须继承TableReducer类
package com.xjq.HdfsToHbase;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> iter,Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable intWritable : iter) {
sum =sum+intWritable.get();
}
String row = key.toString();
//Hbase写入数据必须用put
Put put = new Put(row.getBytes());
put.add("cf".getBytes(), "ct".getBytes(), String.valueOf(sum).getBytes());
context.write(null, put);
}
}
4.实例:把Hbase里面的数据(3中写入Hbase的数据)存入Hdfs
主程序:
package com.xjq.HbaseToHdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class HbToHdRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "node02,node03,node04");
conf.set("fs.defaultFS", "hdfs://node01:8020");
Job job = Job.getInstance(conf);
job.setJarByClass(HbToHdRunner.class);
//从Hbase读入数据必须使用Scan
Scan scan = new Scan();
scan.setCaching(500); // 设置缓存大小。默认1,必须调大
scan.setCacheBlocks(false); //don't set to true for MR jobs
//从Hbase读入数据比必须写这个方法
//参数1 字节数组 表名,参数2 Scan对象, 参数3 mapper对象,
TableMapReduceUtil.initTableMapperJob("wc".getBytes(), scan, HbToHdMapper.class, null, null, job);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(HbToHdReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输出路径FileOutputFormat.setOutputPath(job, outpath );
// 注意:输出路径必须为空
Path outpath = new Path("/Hbase-wc");
if(outpath.getFileSystem(conf).exists(outpath))
outpath.getFileSystem(conf).delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath );
job.waitForCompletion(true);
}
}
mapper类:
从Hbase读取数据,必须继承TableMapper类
package com.xjq.HbaseToHdfs;
import java.io.IOException;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class HbToHdMapper extends TableMapper<Text, Text>{
@Override
protected void map(ImmutableBytesWritable key, Result value,Context context)
throws IOException, InterruptedException {
//key为rowkey,value为这一行所有列族和列值
String word = Bytes.toString(key.get());
String count = Bytes.toString(CellUtil.cloneValue(value.getColumnLatestCell("cf".getBytes(), "ct".getBytes())));
context.write(new Text(word), new Text(count));
}
}
Reducer类:
package com.xjq.HbaseToHdfs;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class HbToHdReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> iter, Context context)
throws IOException, InterruptedException {
Text tx = new Text();
for (Text text : iter) {
tx=text;
}
context.write(key,tx);
}
}
