文章目录
就像在一家公司里面总有明确的分工,每一哥部分负责自己的那一部分的任务,大家一起来维持公司的正常运转,同样的,spark就像是一个公司,他的里面也有许许多多的角色组成
Spark术语解释:
Master
资源管理的主节点,通过管理各个worker来管理集群中的资源
Worker
master的从节点,与master一起管理集群的资源
Application
用户所写的应用程序,就像spark中的HelloWorld的wordcount一样,他就是一个application
Driver
任务调度的进程,application先交给的就是Driver,因为一个应用程序中有多个task组成,而task是被送到某个Executor上进行执行的工作单元,所以Driver在得到application之后,会将application的task进行规划,然后分发到executor上进行执行
Executor
worker进程所管理的节点上为某application启动的一个进程,该进程负责运行任务,说白了就是公司里面的工厂,负责处理Driver发送过来的原材料task,
Job
包含了很多组并行的task,与action算子一一对应,,就像是大货车在运送材料的时候将货物进行打包一起运送一样,将多个task原材料一起打包分发到Executor中进行执行
关系之间的执行关系:
任务层面
Application------由多个job组成(与action的个数相关)------stage------task,是一个个的线程
资源层面
Master--------worker---------executor-------threadpool(task最后的运行地点)
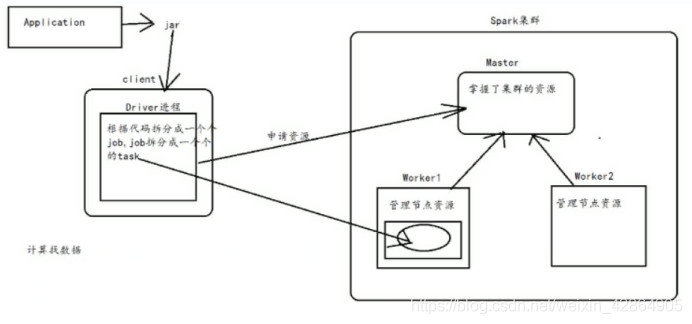
在spark集群中,每个worker管理节点上的资源,而master通过掌握worker来管理整个集群的资源
将application封装成一个个的jar包然后上传到client,在client提交应用程序到spark集群中,
在client上就会启动一个Driver进程,而Driver会根据代码将application拆分成一个个的job,然后将job拆分成一个个的task,接着向master申请资源,在资源充足的节点上启动一个executor和一个相应的线程池

Client
在上面的基本流程的时候说到客户端的一个概念,,那为什么非要使用客户端而不是直接将任务提交到集群呢,
1、尽量减少集群中各台服务器之间的性能差异,防止出现木桶效应
如果直接提交到集群,会在其中一个worker上启动一个一个Driver进行任务的拉取和分发,当worker数量过多的时候会造成严重的磁盘IO,而且因为长时间使用同一个节点进行分发,频繁的通信会造成这个节点与其他节点的性能差异,这样就会出现木桶效应
2、便于维护集群,以防止出现危害集群的行为
当创建客户端之后,不同的用户可以使用不同的权限进行程序的提交,在客户端上可以设置权限的不同,而且,虽然客户端节点在使用的过程中也会出现木桶效应,但是因为在集群之外,不会对集群产生什么影响
在设置了客户端避免了一些不必要的影响之后,为了更好地使用集群的性能,就产生了两种不同的application提交方式
Client
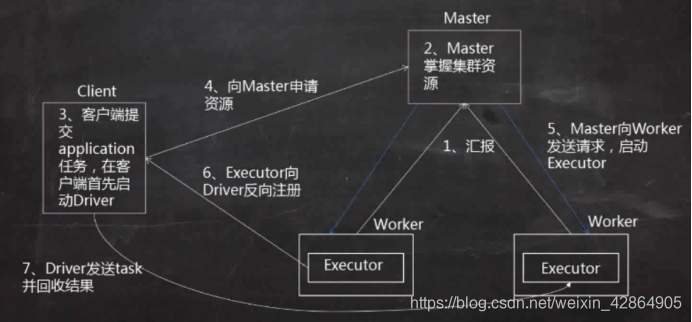
1、worker会向master进行汇报资源情况,
2、master就掌握了集群的资源情况,知道spark中有多少core和memory以及每一个worker管理多少core和memory
3、使用spark-submit在客户端上提交一个application,在client上会启动一个Driver进程
4、driver进程启动之后会去master申请资源,
5、Master会发送请求在资源充足的worker节点上启动executor
6、Executor启动之后会向Driver反向注册,也就知道了一共有多少个executor进行计算
7、Driver发送task并回收计算结果,监控executor的计算进程,包括出现错误进行重试以及task的运行日志
Cluster
Client提交方式存在一定的风险,当task数量过多之后,计算结果都会被回收到Driver端,可能会造成Driver的异常退出,无法进行任务的调度,也就是无法提交程序到集群中
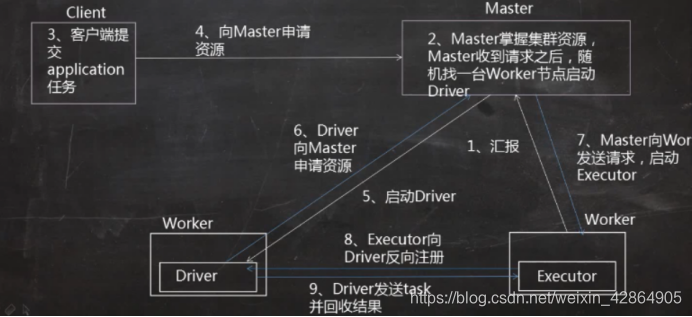
运行程序和client基本相同,不同的地方是Driver会在其中一个资源比较充足的worker节点上进行启动,同样的,Driver启动起来之后会去申请资源,在worker节点上启动Executor上,然后反向注册给Driver,但是,cluster提交方式的不同的地方是他不会将计算结果拉回到客户端进行查看,也就是说在client上不能实施的监控集群的运行情况,只能去web层面进行查看
那这两种提交方式的不同,下面的表格进行了相应的讲解

