今天整理的三个pandas的小知识点,是从工业化生产预测这个比赛中用到的三个,所以集体来整理一下:
1. pandas数值访问(.loc, .iloc,.ix)
首先,建立一个pd.DataFrame做演示:
import pandas as pd
data = pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]},index=["a","b","c"])
data
## 结果:
A B C
a 1 4 7
b 2 5 8
c 3 6 9
-
.loc[]函数:
通过行索引 “Index” 中的具体值来取行数据。括号里面是先行后列,以逗号分割,行和列分别是行标签和列标签。比如我要得到数字5:data.loc["b","B"]因为行标签为b,列标签为B,同理,那么4就是data[“a”,”B”]
上面只是选择某一个值,那么如果我要选择一个区域呢,比如我要选择5,8,6,9,那么可以这样做:data.loc['b':'c','B':'C']因为选择的区域,左上角的值是5,右下角的值是9,那么这个矩形区域的值就是这两个坐标之间,也就是对应5的行标签到9的行标签,5的列标签到9的列标签,行列标签之间用逗号隔开,行标签与行标签之间,列标签与列标签之间用冒号隔开,记住,.loc是用行列标签来进行选择数据的, 且前闭后闭。
那么,我们会想,那我们只知道要第几行,第几列的数据呢,这该怎么办,刚好,.iloc就是干这个事的。 -
.iloc[]
.iloc[]与loc一样,中括号里面也是先行后列,行列标签用逗号分割,与loc不同的之处是,.iloc 是根据行数与列数来索引的,比如上面提到的得到数字5,那么用iloc来表示就是data.iloc[1,1],因为5是第2行第2列,注意索引从0开始的,同理4就是data.iloc[0,1],同样如果我们需要选择一个区域,比如我要选择5,8,6,9,那么用,iloc来选择就是data.iloc[1:3,1:3]因为5在第二行第二列,9在第三行第三列,注意此处区间前闭后开,所以是1:3,与loc不同的是loc前闭后闭,以及loc是根据行列标签,而.iloc是根据行数与列数
-
.ix[]
.ix我发现,上面两种用法他都可以,它既可以根据行列标签又可以根据行列数,比如拿到5data.ix[1,1] data.ix["b","B"]上面两种做法都可以的,同理选择一个区域
data.ix[1:3,1:3] data.ix['b':'c','B':'C'] 以上两种方法都是取到5,6,8,9
再详细点的Pandas中loc和iloc函数用法详解(源码+实例)
2. pandas.set_index和reset_index
- DataFrame可以通过set_index方法,可以设置单索引和复合索引。
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
- keys:列标签或列标签/数组列表,需要设置为索引的列
- drop:默认为True,删除用作新索引的列
- append:默认为False,是否将列附加到现有索引
- inplace:默认为False,适当修改DataFrame(不要创建新对象)
- verify_integrity:默认为false,检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能。
- reset_index可以还原索引,从新变为默认的整型索引
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
- level:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引
- drop:drop为False则索引列会被还原为普通列,否则会丢失
- inplace:默认为false,适当修改DataFrame(不要创建新对象)
- col_level:int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。
- col_fill:对象,默认‘’,如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名
下面看操作:
import pandas as pd
df = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df
df是一个正常的DataFrame结构:
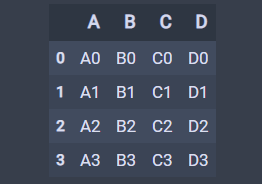
下面把A列置成索引列:
drop_t = df.set_index('A',drop=True, append=False, inplace=False, verify_integrity=False)
drop_t
# 这样就可以通过索引名和列名来访问元素了
drop_t.loc["A0":"A2"]

drop=False, 这样不会删除原列
# drop=False, 不会删除原列
no_drop_t = df.set_index('A',drop=False, append=False, inplace=False, verify_integrity=False)
no_drop_t
结果如下: 不过这个用的不多。

索引的还原: reset_index()
reset_drop_t = drop_t.reset_index(drop=False) #索引列会被还原为普通列
reset_drop_t
reset_no_drop_t = no_drop_t.reset_index(drop=True) #索引列会被还原为普通列
reset_no_drop_t
又回到了原来的样子:
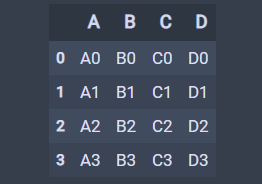
3. pandas.query
这个是字符串表达式查询,基于DataFrame列的计算代数式。对于过滤的操作,可以使用query()方法。注意支持string,不支持布尔类型, 与query类似的一个函数是eval, 是使用字符串表达式来计算对DataFrame的操作,支持算术,比较,位,对象索引,列间计算等, 这俩都是高性能函数,后者遇到的时候再整理吧。
import pandas as pd
d={
'name':['xiao','dan','qi'],
'sex':['male','female','male'],
'age':[23,24,24]
}
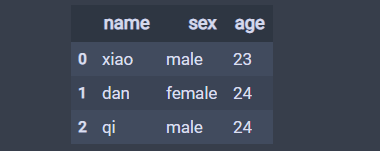
df=pd.DataFrame(d)
结果如下:
# df query('age'>23) # 这个会报错
df.query('age>23')
也是类似与选择出pandas里面符合条件的样本。

好了,今天分享是pandas的三个小知识点,也是比较常用的一些基本操作, 来自于一个工业化工生产预测的比赛。
一切从实用的角度出发。 希望能帮到您!
