后缀数组
定义
令字符串
,
表示下标从
到
的字串
的后缀数组
被定义为一个数组,内容是
的所有后缀经过字典排序后的起始下标。
即
表示排名第几的后缀的起始下标
显然
,
。
首先我们定义一些变量:
表示排名为
的后缀的位置,
表示第i个后缀的排名,
表示每次倍增里的第二关键字排名为
的位置(下面会提到),我们设这个字符串长度为n
求法
大体思想
其实中心思想就是通过倍增来求
假设我们求出了考虑每个后缀前
个的字典序,现在要扩展到
的情况。,考虑
相当于把每个后缀当二元组来排序。我们假定两个变量
和
,在目前长度
下,
指这个后缀的排名,
指这个后缀后
个字母的排名。这样我们就可以用上一轮的
和
当做二元组来排序,就能更新出这次的rk了。
结合这张经典的过程图来理解:
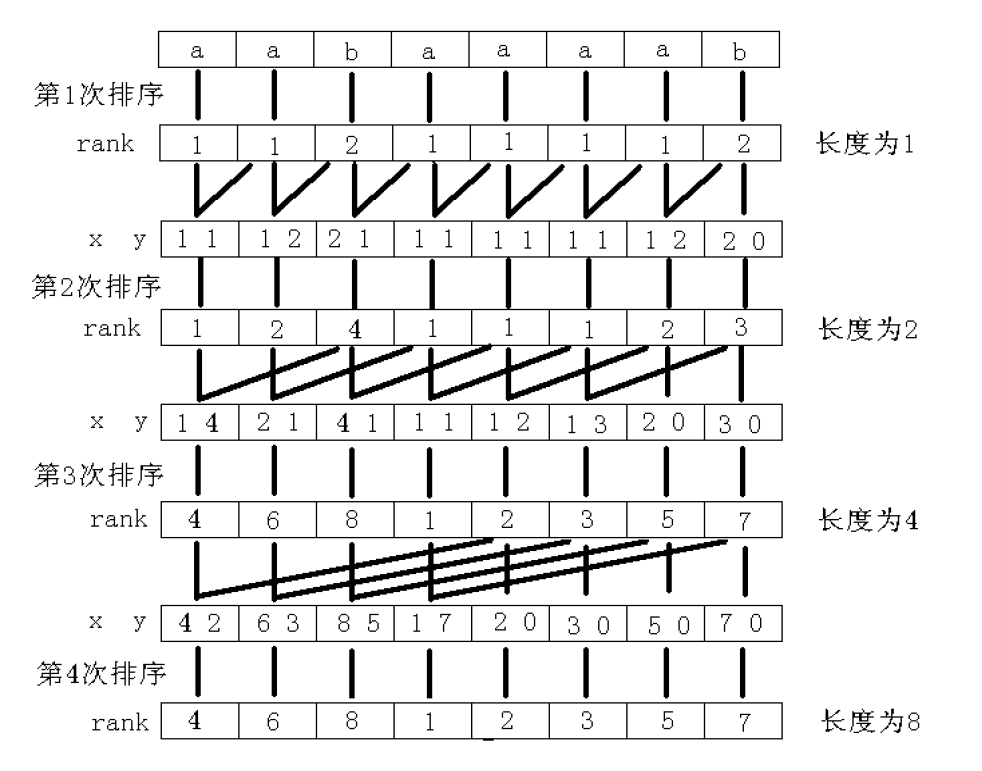
算法过程
首先,按照名义,显然有
也就是说这两个数组可以
互推。
开始时
我们拿来排序的的二元组是
,显然ASCII码小的会在前面。然后我们开始倍增。已经求出了长度为
的答案,考虑去更新
的答案。
现在我们来看如何求
。代码如下:
p=0;
for(int i=1;i<=w;i++) tp[++p]=n-w+i;
for(int i=1;i<=n;i++) if(sa[i]>w) tp[++p]=sa[i]-w;
由上图可以对于长度
的后缀,其字典序一定出现在前面,我们都先拿出来。
然后对于长度
的后缀,可以发现后缀
的后
个字符就是上一轮后缀
的前
个字符(本轮长度为
上一轮为
)。
之后用个高效率(
只有两个关键字)的排序(
基数排序)搞一下就行了。
void Rsort()
{
for(int i=0;i<=m;i++) tax[i]=0;
for(int i=1;i<=n;i++) tax[rk[i]]++;
for(int i=1;i<=m;i++) tax[i]+=tax[i-1];
for(int i=n;i;i--) sa[tax[rk[tp[i]]]--]=tp[i];
}
数组辅助记录每个
的个数,求前缀和便于快速查询排名。
我们重点关注最后一句是干嘛的。首先我们按第二关键字
从大到小枚举,然后找这个后缀第一关键字的排名(
),这个时候前缀和就用上了,因为是从大到小枚举,我们直接把他插入到相应排名的最后。
排名
的后缀是
号的后缀
看不懂没关系,一定要参考定义!!!一开始我也没懂
最后,排序产生的的
一定是互不相同的,但是在倍增过程中可能有的后缀
暂时相同,所以我们要对排序的结果去一下重,重新分配
swap(tp,rk);//上一轮的rk已经没用了,用tp存一下
rk[sa[1]]=p=1;
for(int i=2;i<=n;i++) rk[sa[i]]=(tp[sa[i-1]]==tp[sa[i]]&&tp[sa[i-1]+w]==tp[sa[i]+w]?p:++p);
去重原理同上,如果前半段和后半段在上一轮的rk里相同,那么本轮就相同。
附上完整的代码
//#pragma GCC optimize(2)
//#pragma GCC optimize(3, "Ofast", "inline")
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int,int> pii;
const int N=1.5e6+5;
const ll mod=998244353;
const int base=7e5;
const double eps=1e-5;
const double pi=acos(-1);
#define ls p<<1
#define rs p<<1|1
char s[N];
int n,rk[N],sa[N],tp[N],m,tax[N];
int height[N];
void Rsort()
{
for(int i=0;i<=m;i++) tax[i]=0;
for(int i=1;i<=n;i++) tax[rk[i]]++;
for(int i=1;i<=m;i++) tax[i]+=tax[i-1];
for(int i=n;i;i--) sa[tax[rk[tp[i]]]--]=tp[i];
}
void suffix()
{
m=75;
for(int i=1;i<=n;i++) rk[i]=s[i]-'0'+1,tp[i]=i;
Rsort();
for(int w=1,p=0;p<n;w<<=1,m=p)
{
p=0;
for(int i=1;i<=w;i++) tp[++p]=n-w+i;
for(int i=1;i<=n;i++) if(sa[i]>w) tp[++p]=sa[i]-w;
Rsort();
swap(tp,rk);
rk[sa[1]]=p=1;
for(int i=2;i<=n;i++) rk[sa[i]]=(tp[sa[i-1]]==tp[sa[i]]&&tp[sa[i-1]+w]==tp[sa[i]+w]?p:++p);
}
}
int main()
{
#ifndef ONLINE_JUDGE
freopen("in.txt", "r", stdin);
#endif
ios::sync_with_stdio(false);
cin.tie(0);
cin>>(s+1);n=strlen(s+1);
suffix();
for(int i=1;i<=n;i++) printf("%d ",sa[i]);
return 0;
}
Height数组
后缀数组如果真能排序的话好像没什么用,大部分题目考察的还是height数组的应用。
首先还是定义,
表示后缀
和
的最长公共前缀。
我们考虑通过上面得到的信息来求
(要不写那么多干嘛)
代码:
int j,k=0;
for(int i=1;i<=n;i++)
{
if(k) --k;
j=sa[rk[i-1]];
while(s[i+k]==s[j+k]) ++k;
height[rk[i]]=k;
}
经典应用
求任意后缀的最大
随便拿个数据结构维护一下就可以了。
可重叠最长重复子串
就是求最长的子串,使得在
中至少出现两次
显然就是
数组 的最大值
###本质不同的子串数量
子串 = 后缀的前缀
对于一个长度为
后缀,它有
个前缀,但是每个后缀有
个与
重复,减去即可。
所以
