目录
C语言解析wav文件
接下来在了解了wav文件的有关概念后,我们将通过学习C语言的有关函数库进行wav文件的一些元数据提取出来备用。
1.wav文件的二进制格式解析
一个wav文件的二进制解析:
二进制文件,本质上就是一种使用二进制方式存储文件内容的文件统称,我们前面有讲过使用记事本等工具打开之后看到的是乱码,那么我们怎么分析他呢,可以使用UltraEditor,HxD,C32Asm等等。比如我这里使用HxD打开Windows 7的关机音乐(C:\Windows\Media\Windows Shutdown.wav)就是这个样子,左边就是这个WAV音频文件的十六进制表示,右边则是这个十六进制数字对应的ASCII表示,由于像00之类的数字在ASCII中并没有有效的图像来显示,所以在这个界面的右边显示的就是一个点。(ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0到9、标点符号)
在数据区中,由于一开始wav文件是静音的,所以开头的采样数据全部都是0
WAVE文件本质上就是一种RIFF格式,它可以抽象成一颗树(数据结构的一种)来看。
我们看到这张图上面,从上到下分别对应着二进制数据在文件中相对于起始位置的偏移量。每一个格子对应一个字段,field size表示每个字段所占据的大小,根据这个大小以及当前的偏移量,我们也可以计算出下一个字段的起始地址(偏移量)。wav文件格式也可以用如下表示:
WAV 是Microsoft开发的一种音频文件格式,它符合上面提到的RIFF文件格式标准,可以看作是RIFF文件的一个具体实例。既然WAV符合RIFF规范,其基本的组成单元也是chunk。一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk。各个chunk中字段的意义如下:
1.1 RIFF chunk(资源互换文件格式块)
(1)ChunkID
用以标识块中所包含的数据。如:RIFF,LIST,fmt,data,WAV,AVI等,由于这种文件结构最初是由 Microsoft 和 IBM 为PC机所定义,RIFF文件是按照小端 little-endian 字节顺序写入的。
RIFF的数据域的起始位置是一个4字节码(FOURCC),用于标识其数据域中chunk的数据类型,如第一个图中的RIFF就是标识本文件为RIFF格式,可以嵌套别的chunk。
PS:FourCC 全称为Four-Character Codes,是一个4字节32位的标识符,通常用来标识文件的数据格式。
(2)Chunk Size
存储在data域中的数据长度,不包含 Chunk ID 和 Chunk Size 本身的大小。
(3)Format(文件格式类型)
所有 WAV 格式的文件此处为字符串"WAVE",标明该文件是 WAV 格式文件。
1.2 第一个子块fmt(描述数据子块中声音信息的格式)
(1)Subchunk1ID
第一个子chunk的Subchunk1ID在WAV文件中恒定为fmt,表示该subchunk的内容为该WAV音频文件的一些元数据,也就是该WAV音频的一些格式信息。
(2)Subchunk1 Size
格式块长度。其数值不确定,取决于编码格式。可以是 16、 18 、20、40 等。
(3)AudioFormat
这个字段一般为1,表示这个WAV音频为PCM编码。
(4)NumChannels
该WAV音频文件的声道数量。
(5)SampleRate
采样频率。每个声道单位时间采样次数。常用的采样频率有 11025, 22050 和 44100 Hz。
(6)ByteRate
数据传输速率。该数值为:声道数×采样频率×每样本的数据位数/8。播放软件利用此值可以估计缓冲区的大小。
(7)BlockAlign
数据块对齐单位。
采样帧大小。该数值为:声道数×位数/8。播放软件需要一次处理多个该值大小的字节数据,用该数值调整缓冲区。
则是每个block的平均大小,它等于NumChannels * BitsPerSample/8。
(8)BitsPerSample
则为每秒采样比特,有的地方称它为量化精度或者PCM位宽。
存储每个采样值所用的二进制数位数。常见的位数有 4、8、12、16、24、32
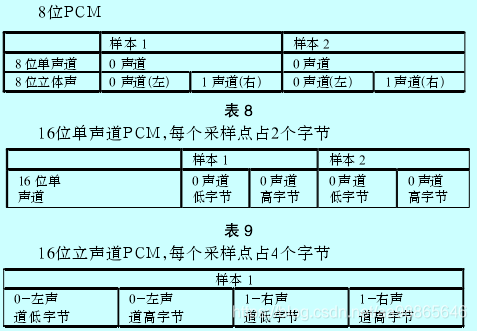
1.3 第二个子块data(附加块,可选)
1、采用压缩编码的WAV文件,必须要有Fact chunk,该块中只有一个数据,为每个声道的采样总数。
2、当WAV文件采用非PCM编码时,使用的是扩展格式块,它是在基本格式块fmt之后扩充了一个的数据结构。
3、Fact chunk前4个字节为id,为"fact";然后是4字节的size,表示本块包含数据的多少(不包含id 和size);
Data: 4字节数值,为每个声道的采样总数,可用与Sample rate一起用来计算波形长度。PS:当wav音频文件时是别的格式转化来的,此时data区内容是“WAVE”的四字节的ASCII码。
一般Fact chunk一共12字节。
Fact chunk
- id
FOURCC 值为 'f' 'a' 'c' 't' - size
数据域的长度,4(最小值为4) - 采样总数 4字节
1.4 第三个子块data(实际音频数据块)
Subchunk2ID
在WAV文件中恒定为data,也就是这个WAV音频文件的实际音频数据,说专业一点,这里面存储的是音频的采样数据。
但是我们的音频如果是双声道,那么实际上某一个采样时刻采样的数据是由左声道和右声道共同组成的。而这个共同组成的采样我们把他叫做block。前面有讲到BlockAlign = NumChannels * BitsPerSample / 8,这个现在就很好理解了,至于为什么末尾要除以8,这是因为计算机中是以8个二进制数表示一个字节,所以要除以8来求出字节数。
Data chunk
- id
FOURCC 值为'd' 'a' 't' 'a' - size
数据域的长度 - data
具体的音频数据存放在这里
2. C语言解析wav文件
2.1 主要使用到的C库函数
(1)fopen(用于打开文件)
相关函数
open(linux系统下常用)
fclose
函数原型:int fclose( FILE *fp );
返回值:如果流成功关闭,fclose 返回 0,否则返回EOF(-1)。(如果流为NULL,而且程序可以继续执行,fclose设定error number给EINVAL,并返回EOF。)
表头文件
#include<stdio.h>
定义函数
FILE * fopen(const char * path,const char * mode);
函数说明
返回值文件顺利打开后,指向该流的文件指针就会被返回。
参数path:字符串包含欲打开的文件路径及文件名
参数mode:字符串则代表着流形态。
mode有下列几种形态字符串:
-
r 打开只读文件,该文件必须存在。
-
r+ 打开可读写的文件,该文件必须存在。
-
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
-
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
-
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
-
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
-
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
附加说明
一般而言,打开文件后会作一些文件读取或写入的动作,若打开文件失败,接下来的读写动作也无法顺利进行,所以一般在fopen()后作错误判断及处理
(2)fread和fwrite(用于读写打开的文件)
一般调用形式
fread(buffer,size,count,fp);
fwrite(buffer,size,count,fp);
说明
如果调用成功返回实际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回 0
(1)buffer:是一个指针,对fread来说,它是读入数据的存放地址。对fwrite来说,是要输出数据的地址。
(2)size:要读写的字节数;
(3)count:要进行读写多少个size字节的数据项;
(4)fp:文件型指针。
注意:
1 完成次写操(fwrite())作后必须关闭流(fclose());
2 完成一次读操作(fread())后,如果没有关闭流(fclose()),则指针(FILE * fp)自动向后移动前一次读写的长度,不关闭流继续下一次读操作则接着上次的输出继续输出;
2.2 解析wav文件代码
头文件(wave.h):
结构体:由一系列具有相同类型或不同类型的数据构成的数据集合,叫做结构体(struct)。
结构体可以被声明为变量、指针或数组等,用以实现较复杂的数据结构。结构体同时也是一些元素的集合,这些元素称为结构体的成员(member),且这些成员可以为不同的类型,成员一般用名字访问。
头文件主要包含了四个结构体,WAV_RIFF结构体相当于RIFF块,三个元素分别是:
(1)文档标识:大写字符串"RIFF",标明该文件为有效的 RIFF 格式文档。
(2)文件数据长度:从下一个字段首地址开始到文件末尾的总字节数。该字段的数值加 8 为当前文件的实际长度。
(3)文件格式类型:所有 WAV 格式的文件此处为字符串"WAVE",标明该文件是 WAV 格式文件。
WAV_FMT结构体即是上述的wav文件的第一个子块(fmt-chunk)。
WAV_DATA结构体是第三个子块(data-chunk)。
WAV_FORMAT是一个包含前面三个结构体的结构体。
typedef struct WAV_RIFF {
/* chunk "riff" */
char ChunkID[4]; /* "RIFF" */
/* sub-chunk-size */
uint32_t ChunkSize; /* 36 + Subchunk2Size */
/* sub-chunk-data */
char Format[4]; /* "WAVE" */
} RIFF_t;
typedef struct WAV_FMT {
/* sub-chunk "fmt" */
char Subchunk1ID[4]; /* "fmt " */
/* sub-chunk-size */
uint32_t Subchunk1Size; /* 16 for PCM */
/* sub-chunk-data */
uint16_t AudioFormat; /* PCM = 1*/
uint16_t NumChannels; /* Mono = 1, Stereo = 2, etc. */
uint32_t SampleRate; /* 8000, 44100, etc. */
uint32_t ByteRate; /* = SampleRate * NumChannels * BitsPerSample/8 */
uint16_t BlockAlign; /* = NumChannels * BitsPerSample/8 */
uint16_t BitsPerSample; /* 8bits, 16bits, etc. */
} FMT_t;
typedef struct WAV_DATA {
/* sub-chunk "data" */
char Subchunk2ID[4]; /* "data" */
/* sub-chunk-size */
uint32_t Subchunk2Size; /* data size */
/* sub-chunk-data */
// Data_block_t block;
} Data_t;
//typedef struct WAV_data_block {
//} Data_block_t;
typedef struct WAV_FORMAT {
RIFF_t riff;
FMT_t fmt;
Data_t data;
} Wav; 解析wav的C代码(wave.c):
(1)struct类型里面我用的是uint32_t等类型,而不是传统的int,short等等,这是为了考虑到不同的编译器,不同的平台下对于int类型分配的内存空间不一致的问题。而这些类型是由stdint.h头文件提供的,因此我们需要在头部导入它。
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include "wave.h"
int main()
{
FILE *fp = NULL; //定义文件指针
实例化四个结构体
Wav wav;
RIFF_t riff;
FMT_t fmt;
Data_t data;
打开测试wav文件并做出错处理
fp = fopen("test.wav", "rb");
if (!fp) {
printf("can't open audio file\n");
exit(1);
}
//读取文件
fread(&wav, 1, sizeof(wav), fp);
riff = wav.riff;
fmt = wav.fmt;
data = wav.data;
//输出RIFF块信息
printf("ChunkID \t%c%c%c%c\n", riff.ChunkID[0], riff.ChunkID[1], riff.ChunkID[2], riff.ChunkID[3]);
printf("ChunkSize \t%d\n", riff.ChunkSize);
printf("Format \t\t%c%c%c%c\n", riff.Format[0], riff.Format[1], riff.Format[2], riff.Format[3]);
printf("\n");
//输出格式子块信息
printf("Subchunk1ID \t%c%c%c%c\n", fmt.Subchunk1ID[0], fmt.Subchunk1ID[1], fmt.Subchunk1ID[2], fmt.Subchunk1ID[3]);
printf("Subchunk1Size \t%d\n", fmt.Subchunk1Size);
printf("AudioFormat \t%d\n", fmt.AudioFormat);
printf("NumChannels \t%d\n", fmt.NumChannels);
printf("SampleRate \t%d\n", fmt.SampleRate);
printf("ByteRate \t%d\n", fmt.ByteRate);
printf("BlockAlign \t%d\n", fmt.BlockAlign);
printf("BitsPerSample \t%d\n", fmt.BitsPerSample);
printf("\n");
//输出数据块信息
printf("blockID \t%c%c%c%c\n", data.Subchunk2ID[0], data.Subchunk2ID[1], data.Subchunk2ID[2], data.Subchunk2ID[3]);
printf("blockSize \t%d\n", data.Subchunk2Size);
printf("\n");
//输出wav文件的时长
printf("duration \t%d\n", data.Subchunk2Size / fmt.ByteRate);
fclose(fp);
}将以上代码gcc编译通过后,执行得到的测试结果如下:
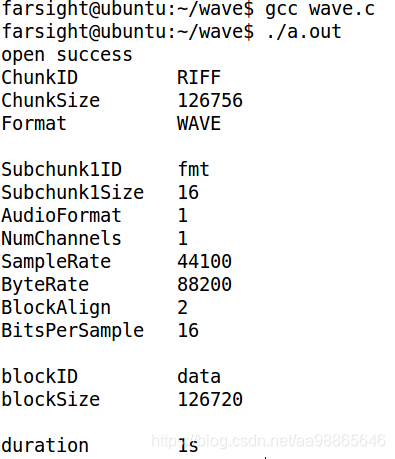
通过测试结果分析可知:
(1)ChunkID是RIFF格式文件,数据域的大小一共有126756个字节(不包含ChunkID和ChunkSize),文件格式类型是wav文件。
(2)fmt表示存储的wav文件的一些元数据,格式块的长度位16,AudioFormat为1表示为PCM编码,NumChannels表示声道数是单声道,采样频率为44100 kHz,数据传输速率为88200Khz*bit(为声道数×采样频率×BitsPerSample(量化精度)/8),数据块对齐单位(或者叫做采样帧大小)是2字节(声道数×位数/8),最后BitsPerSample(量化精度)是16bit/s。
(3)剩下的blockID为data是数据块,数据块大小为126720字节。本文件时长为1秒。
参考博客:
(1)C语言解析WAV音频文件
(2)wav文件格式分析与详解
(3)RIFF格式解析
