编程界的小学生
不会说全部api,api这东西想用自己help @list就行了。
一、特点
sorted_set有序且去重,这里的有序和list类型的有序不同,这里是指通过score自定义排序。而不是元素先来后到的顺序。
二、负向索引
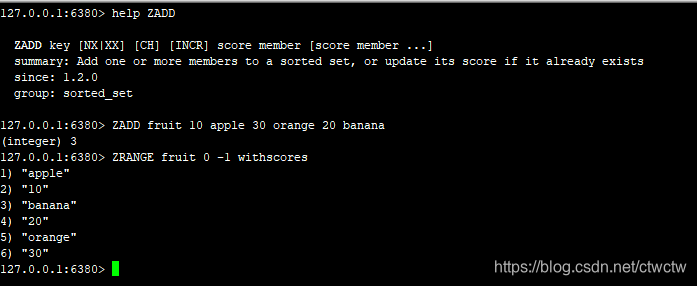
| 索引类型 | apple | banana | orange |
|---|---|---|---|
| 正向索引 | 0 | 1 | 2 |
| 反向索引 | -3 | -2 | -1 |
可以发现zadd默认按照score升序,而不是元素插入顺序。
三、常见api
1、按分值获取
127.0.0.1:6380> ZRANGEBYSCORE fruit 10 20
1) "apple"
2) "banana"
2、按分数由低到高取两个
127.0.0.1:6380> ZRANGE fruit 0 1
1) "apple"
2) "banana"
3、按分数由高到低取两个
127.0.0.1:6380> ZREVRANGE fruit 0 1
1) "orange"
2) "banana"
4、按照元素取出分数
127.0.0.1:6380> ZSCORE fruit banana
"20"
5、按照元素取出排名
127.0.0.1:6380> ZRANK fruit banana
(integer) 1
127.0.0.1:6380> ZRANK fruit apple
(integer) 0
6、增加元素的score
127.0.0.1:6380> ZINCRBY fruit 12.5 banana
"32.5"
127.0.0.1:6380> zrange fruit 0 -1
1) "apple"
2) "orange"
3) "banana"
127.0.0.1:6380> zrank fruit banana
(integer) 2
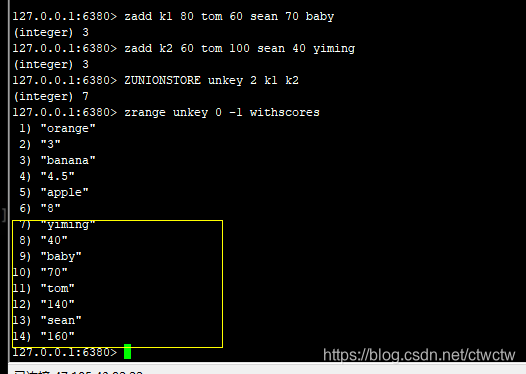
7、交/并/差集
和set有区别,比如union并集操作会把相同元素的score进行相加
union加权重,k1 k2 weights 1 0.5代表第一个key的score不变,第二个key的元素score除以2(因为权重是0.5),默认不写每个key的权重都是1,也就是原始score。
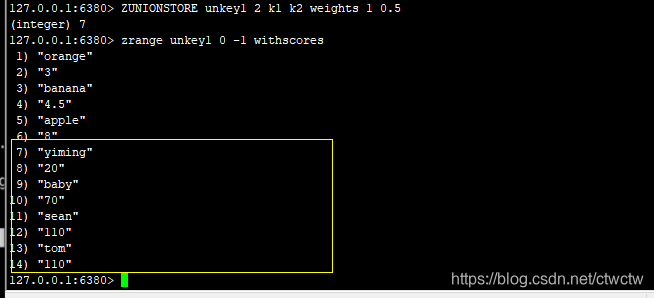
比如tom,k1的tom权重是1,score不变,还是60,k2的tom权重是0.5,score是100/2=50,60+50=110
还支持一个聚合操作:
ZUNIONSTORE unkey1 2 k1 k2 aggregate max
意思是算出k1和k2中重复元素最大的score。不进行相加分数了,只保留最大score。
四、疑问
他能保证有序不重复,他为啥还这么快?
因为他底层采取了跳表数据结构,可以自行google。
五、总结
- 特点
- 负向索引
- api
- 交并差集
- 跳表
