Hadoop 实验:分布式缓存
一.概述
假定现在有100G的大表和1M的小表,如果是储存在一个盘里,处理和运行就会很慢,假定把100G分别分到10个map,这样1个map就是总量的1/10,加快了处理。用小表中单词在大表中出现次数,也即所谓的“扫描大表,加载小表”。也即分布时缓存。
如图:

由于这次实验没有100G这么大的表也没有1m的小表只能自己设置一个小表和大表。
整个实验步骤为:
1.准备数据
2.上传数据
3.编写代码
4.执行代码
5.查看结果
1.准备数据
大文件为:big.txt
aaa bbb ccc eee fff ggg
hhh iii jjj kkk lll mmm nnn
ooo ppp qqq rrr sss ttt uuu
vvv www yyy zzz
小文件为:small.txt
eee sss 555
2.上传数据
先用Xftp把大表和小表上传到Ubantu中地址: /home/hadoop/主目录
创建文件夹
Hadoop fs -mkdir -p /user/root/mr/in
导入txt文本
Hadoop fs -put /home/hadoop/big.txt /user/root/mr/in
Hadoop fs -put /home/hadoop/small.txt /user/root/mr/in
查询是否上传成功:
Hadoop fs -ls /user/root/mr/in
3.编写代码
(1)jar为/hadoop/ilb.zip 请自行下载。
(2)我用的idea开发工具
(3)新 建 BigAndSmallTable 类 并 指 定 包 名 ( 代 码 中 为 cn.cstor.mr ) , 在 BigAndSmallTable.java 文件中。
(4)代码如下:
package cn.cstor.mr;
import java.io.IOException;
import java.util.HashSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.LineReader;
public class BigAndSmallTable {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private static HashSet<String> smallTable = null;
protected void setup(Context context) throws IOException,
InterruptedException {
smallTable = new HashSet<String>();
Path smallTablePath = new Path(context.getConfiguration().get(
"smallTableLocation"));
FileSystem hdfs = smallTablePath.getFileSystem(context
.getConfiguration());
FSDataInputStream hdfsReader = hdfs.open(smallTablePath);
Text line = new Text();
LineReader lineReader = new LineReader(hdfsReader);
while (lineReader.readLine(line) > 0) {
// you can do something here
String[] values = line.toString().split(" ");
for (int i = 0; i < values.length; i++) {
smallTable.add(values[i]);
System.out.println(values[i]);
}
}
lineReader.close();
hdfsReader.close();
System.out.println("setup ok *^_^* ");
}
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] values = value.toString().split(" ");
for (int i = 0; i < values.length; i++) {
if (smallTable.contains(values[i])) {
context.write(new Text(values[i]), one);
}
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("smallTableLocation", args[1]);
Job job = Job.getInstance(conf, "BigAndSmallTable");
job.setJarByClass(BigAndSmallTable.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行代码后遇到的问题:
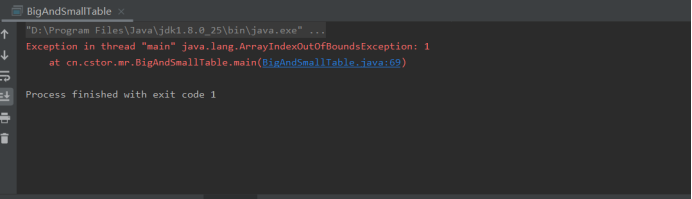
这个数组是长度为0的(但不等于null),当使用 args[0]时就会出现越界错误。
需要参数,需要给参数赋值,但我们的才是为txt的文本,所以这里不影响我们在hadoop 运行。
我们只需要在hadoop 运行jar加txt 就不会出现此问题。
(5)将java 导出为jar包,用xftp导入uabntu /usr/local/hadoop/share/hadoop/name/。
4.执行代码
/usr/cstor/hadoop/bin/hadoop jar /home/hadoop/BigSmallTable.jar
cn.cstor.mr.BigAndSmallTable /user/root/mr/in/big.txt
/user/root/mr/in/small.txt /user/root/mr/bigAndSmallResult
执行成功:

5.查询结果
程序执行后,可使用下述命令查看执行结果,注意若再次执行,请更改结果目录:
Hadoop fs -cat /user/root/mr/bigAndSmallResult/part-r-00000
根据 big.txt,small.txt 文件内容和编程目的,易知实验结果准确无误。

