下面说说修改的地方。
1。修改源文件保存编码在:settings->Editor->gernal settings 看到右边的Encoding group Box了吗?如下图所示:
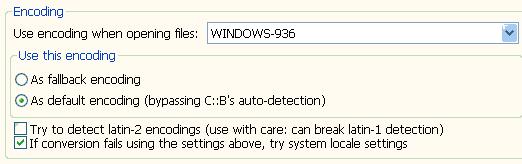
Use encoding when opening files:这个表示打开文件用的格式,第一次保存文件的时候也会用这个格式。
As default encoding:表示设置为文件缺省保存和打开编码格式
注意,要先设置好,然后保存文件,才有效。如果你已经保存了文件,无论你怎么修改这个设置,也不会改变你文件的格式了。你的文件还是保持第一次保存的时候的格式。
所以,如果遇到无法生效,只能先设置好格式,再重新建文件了。
2。修改编译器对源文件解释编码格式和生成执行文件执行时候采用的编码格式
是在settings->compiler and debugger settings里面,选择对应的GCC编译器,如下图所示:
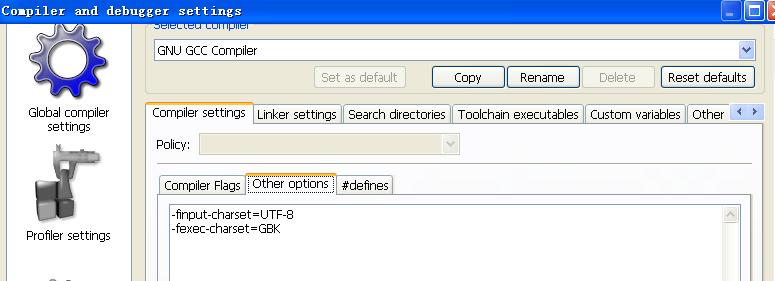
在other options里面加入:
-finput-charset=charset
-fexec-charset=charset
-finput-charset=UTF-8
-finput-charset=GBK
显示中文一定要把utf-8放在编辑框的上面一行Code:Blocks 中文乱码问题原因分析和解决方法
第一个参数表示编译的时候输入文件的编码解释格式,第二参数表示生成的执行文件执行的时候显示用的编码格式。
这些参数如果和实际不吻合,必然产生乱码。只要吻合,就不会乱码了。
由于我的源文件格式是WINDOWS-936,但是这里设置成UTF-8,所以编译肯定报错!
只需要修改成-finput-charset=WINDOWS-936或者GBk,就编译通过了。
如果不设置fexec-charset默认会认为执行环境是UTF-8,而windows下并不是,所以Linux下没问题,因为Linux就是UTF-8的,但是windows 下必然出现乱码。
所以设置成GBk,就统一了。
一切都那么简单,其实,只是因为编程的人做的不够完善,所以才会给使用的人带来困扰。希望这篇文章能帮到一些初学者。或者遇到同样问题的人。