Github源码地址:Github
CycleGan.py
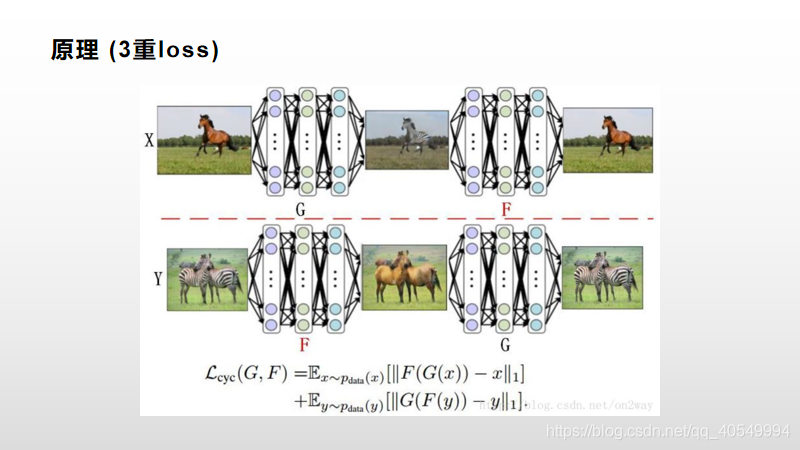
Cycle逻辑

代码内容
1. import,定义参数及创建存放数据的文件夹
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
from utils import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="monet2photo", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator outputs")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
parser.add_argument("--n_residual_blocks", type=int, default=9, help="number of residual blocks in generator")
parser.add_argument("--lambda_cyc", type=float, default=10.0, help="cycle loss weight")
parser.add_argument("--lambda_id", type=float, default=5.0, help="identity loss weight")
opt = parser.parse_args()
print(opt)
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
2. 定义损失函数
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
torch.nn.MSELoss()为均方损失函数.
torch.nn.L1Loss()的数学表达形式是:
3. 定义输入的shape
input_shape = (opt.channels, opt.img_height, opt.img_width)
最后input_shape = (3, 256, 256)
4. 初始化网络
# Initialize generator and discriminator
G_AB = GeneratorResNet(input_shape, opt.n_residual_blocks)
G_BA = GeneratorResNet(input_shape, opt.n_residual_blocks)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)
其中对于GeneratorResNet()和Discriminator的定义在model.py中,我们先看这两个函数。
GeneratorResNet
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0]
# Initial convolution block
out_features = 64
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, out_features, 7),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Downsampling
for _ in range(2):
out_features *= 2
model += [
nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Residual blocks
for _ in range(num_residual_blocks):
model += [ResidualBlock(out_features)]
# Upsampling
for _ in range(2):
out_features //= 2
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Output layer
model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
Discriminator(nn.Module)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output shape of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)
5. 判断是否导入pretrained-model
if opt.epoch != 0:
# Load pretrained models
G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, opt.epoch)))
G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, opt.epoch)))
D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (opt.dataset_name, opt.epoch)))
D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
6. 定义优化器
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
关于torch.optim.Adam:
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- params(iterable):可用于迭代优化的参数或者定义参数组的dicts。
- lr (float, optional)学习率(默认: 1e-3)
- betas (Tuple[float, float], optional):用于计算梯度的平均和平方的系数(默认: (0.9, 0.999))
- eps (float, optional):为了提高数值稳定性而添加到分母的一个项(默认: 1e-8)
- weight_decay (float, optional):权重衰减(如L2惩罚)(默认: 0)
7. 定义rate update schedulers
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
学习率数值的设定是因网络而异的,你可以设一个定值,也可以设一个变化的值。道理很简单,在二次函数y = x^2中,当X很大时,梯度下降的幅度很大,学习率会定的比较高;但是当X比较小时,当X下降Y变换不大,此时如果还用之前的学习率,就会出现没办法成功收敛到极小值的情况。代码中的函数功能是,随着epoch的增加,学习率发生变化。不需要去很仔细的看代码的内容,每个网络都是不一样的,学习率的确定要经过无数次的调参测试,最终确定之后其实也可以用简单的if -else,在不同的epoch下用不一样的学习率。
扫描二维码关注公众号,回复:
10054316 查看本文章

