浏览器的高层结构
一 主要组件:
01 用户界面: 包括地址栏, 前进,后腿,书签,菜单等. 除了主窗口显示的页面外, 其他显示的各个部分都属于用户界面
02 浏览器引擎: 在用户界面和呈现引擎之间传送指令
03 呈现引擎: 负责显示请求的内容. 如果请求的内容是HTML, 它负责解析HTML和CSS,并将解析后的内容显示在屏幕上.
04 网络: 用于网络调用, 比如HTTP请求. 其接口与平台无关, 并为所有平台提供底层实现.
05 用户界面后端: 用于绘制基本的窗口小部件,比如组合框和窗口. 其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法.
06 JavaScript解释器: 用于解析和执行JavaScript代码.
07 数据存储: 这是持久层, 浏览器需要在硬盘上保存各种数据, 例如Cookie. HTML5定义了"网络数据库", 这是一个完整的浏览器内数据库.
解析示例
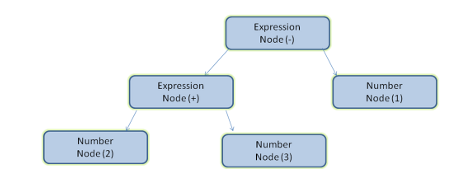
我们通过一个数学表达式建立了解析树。现在,让我们试着定义一个简单的数学语言,用来演示解析的过程。
词汇:我们用的语言可包含整数、加号和减号。
语法:
构成语言的语法单位是表达式、项和运算符。
我们用的语言可以包含任意数量的表达式。
表达式的定义是:一个“项”接一个“运算符”,然后再接一个“项”。
运算符是加号或减号。
项是一个整数或一个表达式。
让我们分析一下 2 + 3 - 1。
匹配语法规则的第一个子串是 2,而根据第 5 条语法规则,这是一个项。匹配语法规则的第二个子串是 2 + 3,而根据第 3 条规则(一个项接一个运算符,然后再接一个项),这是一个表达式。下一个匹配项已经到了输入的结束。2 + 3 - 1 是一个表达式,因为我们已经知道 2 + 3 是一个项,这样就符合“一个项接一个运算符,然后再接一个项”的规则。2 + + 不与任何规则匹配,因此是无效的输入。
解析器和词法分析器的组合
解析的过程可以分成两个子过程:词法分析和语法分析。
词法分析是将输入内容分割成大量标记的过程。标记是语言中的词汇,即构成内容的单位。在人类语言中,它相当于语言字典中的单词。
语法分析是应用语言的语法规则的过程。
解析器通常将解析工作分给以下两个组件来处理:词法分析器(有时也称为标记生成器),负责将输入内容分解成一个个有效标记;而解析器负责根据语言的语法规则分析文档的结构,从而构建解析树。词法分析器知道如何将无关的字符(比如空格和换行符)分离出来。
解析算法
HTML 无法用常规的自上而下或自下而上的解析器进行解析。
原因在于:
语言的宽容本质。
浏览器历来对一些常见的无效 HTML 用法采取包容态度。
解析过程需要不断地反复。源内容在解析过程中通常不会改变,但是在 HTML 中,脚本标记如果包含 document.write,就会添加额外的标记,这样解析过程实际上就更改了输入内容。
由于不能使用常规的解析技术,浏览器就创建了自定义的解析器来解析 HTML。
标记化算法
使用状态机来表示, 每一个状态接受来自输入信息流的一个或多个字符, 并根据这些字符更新下一个状态.
<html>
<body>
Hello world
</body>
</html>
初始状态是数据状态。遇到字符 < 时,状态更改为“标记打开状态”。接收一个 a-z 字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收 > 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。
遇到 > 标记时,会发送当前的标记,状态改回“数据状态”。 标记也会进行同样的处理。目前 html 和 body 标记均已发出。现在我们回到“数据状态”。接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收 中的 <。我们将为 Hello world 中的每个字符都发送一个字符标记。
现在我们回到“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token 并改为“标记名称状态”。我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。 输入也会进行同样的处理。

树构建算法
在创建解析器的同时,也会创建 Document 对象。在树构建阶段,以 Document 为根节点的 DOM 树也会不断进行修改,向其中添加各种元素。
<html>
<body>
Hello world
</body>
</html>
dom树构建阶段的输入是一个来自标记化阶段的标记序列。第一个模式是“initial mode”。接收 HTML 标记后转为“before html”模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。
然后状态将改为“before head”。此时我们接收“body”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个 HTMLHeadElement,并将其添加到树中。
现在我们进入了“in head”模式,然后转入“after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为“in body”。
现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点。
接收 body 结束标记会触发“after body”模式。现在我们将接收 HTML 结束标记,然后进入“after after body”模式。接收到文件结束标记后,解析过程就此结束。

解析结束后
在此阶段,浏览器会将文档标注为交互状态,并开始解析那些处于“deferred”模式的脚本,也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“完成”,一个“加载”事件将随之触发。
css解析
和 HTML 不同,CSS 是上下文无关的语法,可以使用简介中描述的各种解析器进行解析。

脚本
网络的模型是同步的. 网页的作者希望解析器遇到
预解析
在执行脚本时, 其他线程会解析文档的其余部分,找出并加载需要通过网络加载的其他资源,这样资源可以并行连接上加载,从而提高总体速度.请注意,预解析器不会修改DOM树,而是将这项工作交由主解析器处理; 预解析器只会解析外部资源的引用.
呈现树
在构建DOM树时, 还会构建另外一个树: 呈现树. 这是由可视化元素按其显示顺序而组成的树,它的作用是让内容按顺序进行展示.
呈现器是和 DOM 元素相对应的,但并非一一对应。非可视化的 DOM 元素不会插入呈现树中,例如“head”元素。如果元素的 display 属性值为“none”,那么也不会显示在呈现树中(但是 visibility 属性值为“hidden”的元素仍会显示)。
有一些 DOM 元素对应多个可视化对象。它们往往是具有复杂结构的元素,无法用单一的矩形来描述。例如,“select”元素有 3 个呈现器:一个用于显示区域,一个用于下拉列表框,还有一个用于按钮。如果由于宽度不够,文本无法在一行中显示而分为多行,那么新的行也会作为新的呈现器而添加。
另一个关于多呈现器的例子是格式无效的 HTML。根据 CSS 规范,inline 元素只能包含 block 元素或 inline 元素中的一种。如果出现了混合内容,则应创建匿名的 block 呈现器,以包裹 inline 元素。
有一些呈现对象对应于 DOM 节点,但在树中所在的位置与 DOM 节点不同。浮动定位和绝对定位的元素就是这样,它们处于正常的流程之外,放置在树中的其他地方,并映射到真正的框架,而放在原位的是占位框架

