本人新书上市,请多多关照:《SQL Server On Linux运维实战 2017版从入门到精通》

接上文:SQL Server On Linux(26)——SQL Server on Linux 性能(10)——列存储索引简介这次来做一个简单的实操演示
这次我们使用WideWorldImportersDW库来演示。
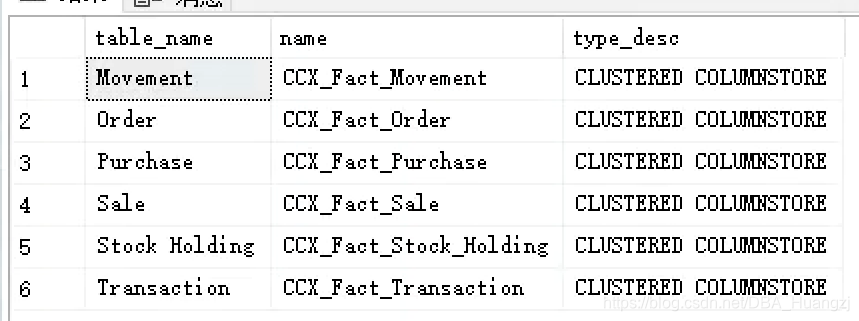
首先查一下哪些表用了聚集列存储索引:
USE [wideworldimportersdw]
GO
SELECT OBJECT_NAME(object_id) as table_name, name, type_desc
FROM sys.indexes
WHERE type = 5 -- type = 5 指的是聚集列存储索引
GO
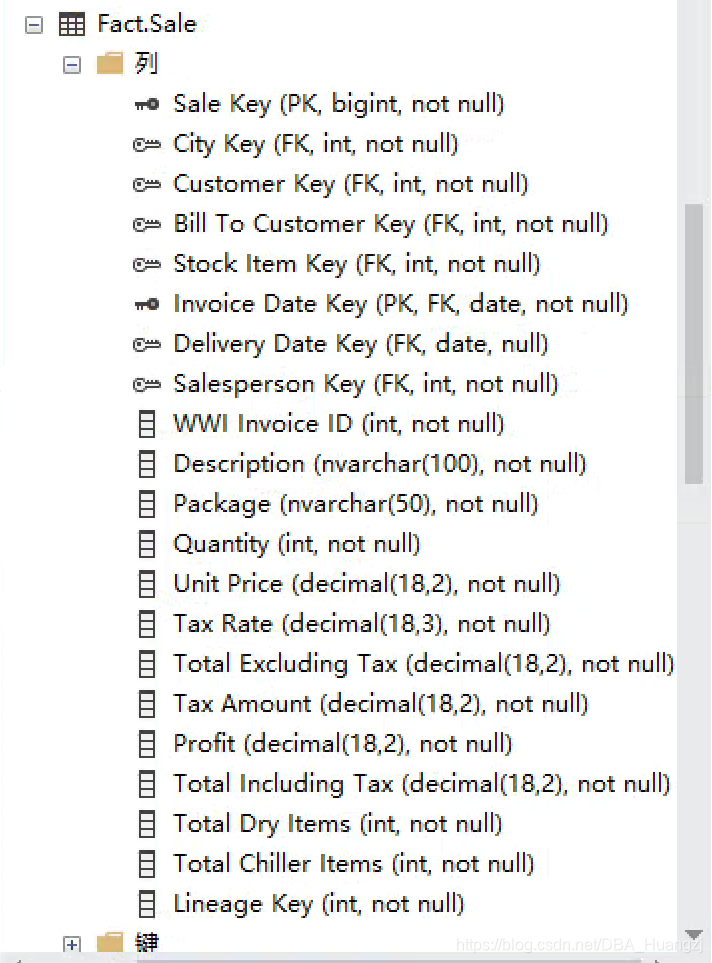
这个库有6个表用了聚集列存储索引。我们挑一个常见的Sale表,全名Fact.Sales。
接下来我们跑一个查询,看一下聚集列存储索引的工作原理,这里使用Fact.Sale表,包含了228265行数据,这个表有两个时间列,但是数据按“Delivery Date Key”来排序,所以我们接下来的Where条件会使用这个列来做筛选。
SQL Server有元数据来存储元组中每个片段的范围值,如果数据按照某个列排序,SQL Server会基于查询的条件跳过特定行组。
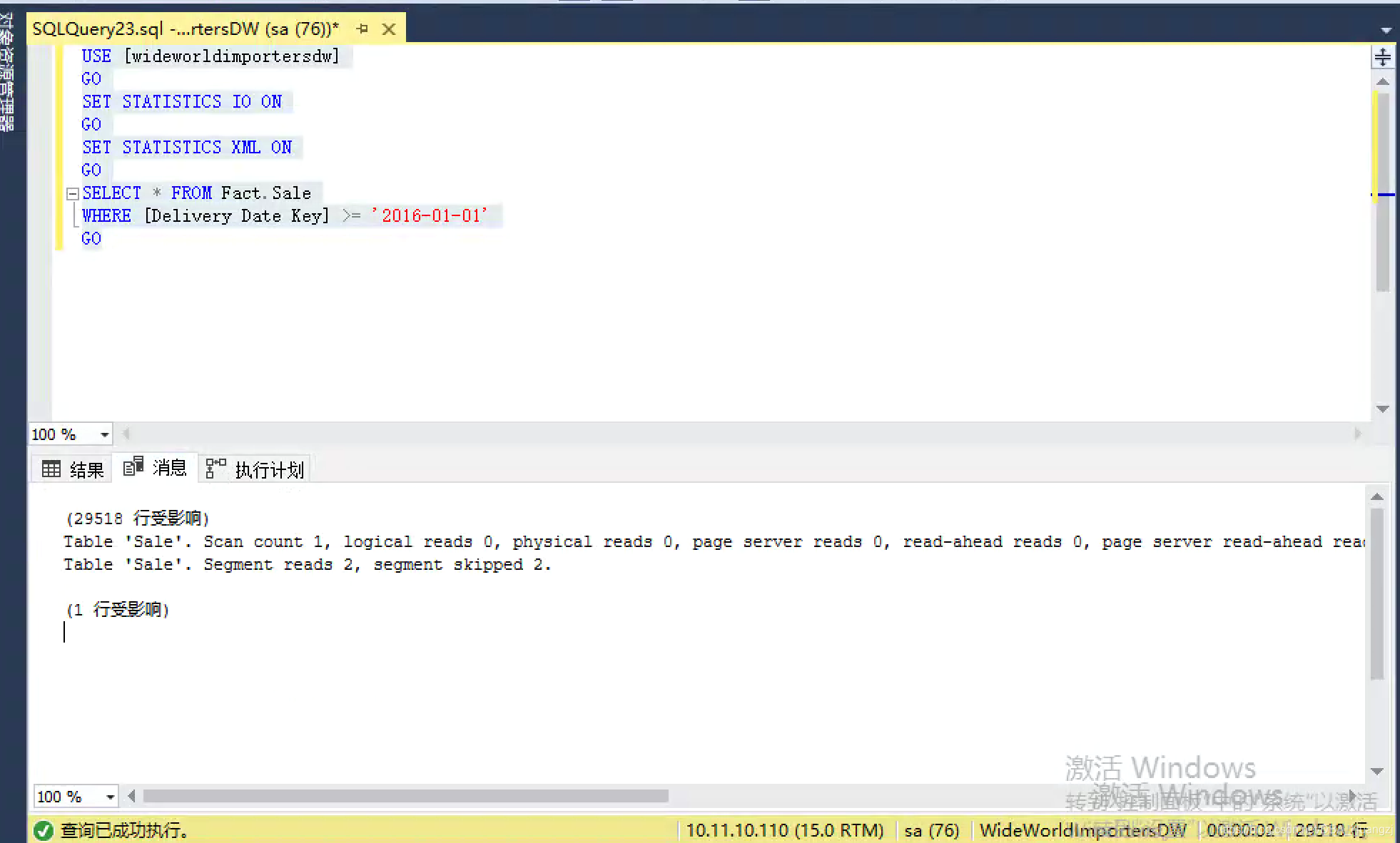
USE [wideworldimportersdw]
GO
SET STATISTICS IO ON
GO
SET STATISTICS XML ON
GO
SELECT * FROM Fact.Sale
WHERE [Delivery Date Key] >= '2016-01-01'
GO
执行时间和I/O统计信息如下:
Table ‘Sale’. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 644, lob physical reads 39, lob page server reads 0, lob read-ahead reads 627, lob page server read-ahead reads 0.
Table ‘Sale’. Segment reads 2, segment skipped 2.
lob logical reads是指SQL Server通过聚集列存储索引在内存的cache中查询所需数据的读取次数。SQL Server把列存储索引存储在LOB中,所以我们这里用的是lob的值而不是前面的logical reads。
第二部分的Segment reads是指片段的读取次数,segment skipped是片段消除数量,这里有点误导,实际上应该是rowgroups read和rowgroups skipped。这里的解读是聚集列存储索引有4(2+2)个rowgroups,由于片段消除导致可以跳过2个,也就是说只需要读取4个里面的2个即可。
再看另外一个查询:
USE [wideworldimportersdw]
GO
SET STATISTICS IO ON
GO
SET STATISTICS XML ON
GO
SELECT [Customer Key], Quantity
FROM Fact.Sale
WHERE [Delivery Date Key] >= '2016-01-01'
GO
Table ‘Sale’. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 49, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table ‘Sale’. Segment reads 2, segment skipped 2.
这个查询相对于前面的来说就是列少了,可以看到lob logical reads从644降到49,因为列少,所以所需的片段更少,当数据量非常大的时候,这种降幅是很明显的。
总结
从这个演示中得到几点:
- 不管是行存储索引还是列存储索引,对于关系型数据库,总是使用表的所有列并不是最佳实践。
- 用SET STATISTICS IO 来获取I/O信息的过程中,对于列存储索引,要看Lob logical reads和Lob physical reads。对于行存储索引,我们一般看logical reads/physical reads即可。
- 演示里面没有说明,但是额外说一下,对于聚集列存储索引,截至目前版本2019,都没有查找操作,也就是说只能看到聚集列存储索引扫描操作。
