本人新书上市,请多多关照:《SQL Server On Linux运维实战 2017版从入门到精通》

对于关系数据库而言,CPU、内存和I/O子系统都是不可缺少的硬件资源,哪一个出问题都会直接影响性能,不过要注意很多表象,比如CPU利用率高,有时候仅仅是因为内存不够,CPU忙于把数据从内存和磁盘之间不停调度导致。所以要坚持从整体去思考的原则。
简介
SQL Server借助read-ahead reading(预读)、write-ahead logging、checkpoint和数据压缩等功能,使其在确保数据一致性和持久性的前提下能最大化读写性能。另外在Linux平台还引入了缓存机制,借用O_DIRECT标记来获取I/O最大化性能。
接下来对这些功能做下介绍。
Read-Ahead
SQL Server的数据页是固定8KB的,如果SQL Server每次读取一页时,I/O次数将非常多从而影响性能,因此SQL Server使用了叫read-ahead的机制,把数据页放入buffer pool。SQL Server认为当前正在执行的查询可能会需要这些数据页,因此把数据预先加载到内存的缓存中会更有效。预读用于表或索引中分布在多个页的数据行的扫描操作。
可以使用SET STATISTICS IO ON这个T-SQL命令来检查是否有预读,也可以用扩展事件跟踪file_read_completed。还可以使用sys.dm_os_performance_counters这个DMV筛选符合object_name = ‘SQLServer:Buffer Manager’ and counter_name = 'Readahead pages/sec’条件的值。
但是每次预读的大小非常依赖于表或索引的组织,因为它实际上是把数据连带取出,所以数据应该是要连续的。如果碎片很多,那么预读的效果就很不明显。另外跟SQL Server的版本也有关系,SQL Server 2017企业版最大的单次预读是1MB,而其他版本则更少。接下来简单演示一下。
Read-Ahead 演示
首先创建一个扩展事件跟踪这个行为,这里针对实例数据库WideWorldImporters进行,这个库将会多次被使用,如果现在还没环境可以参考SQL Server On Linux(3)——SQL Server 2019 For Linux 下载并部署示例数据库。
CREATE EVENT SESSION [tracesqlreads] ON SERVER
ADD EVENT sqlserver.file_read_completed(SET collect_path=(1)
ACTION(sqlserver.database_name,sqlserver.sql_text)
WHERE ([sqlserver].[database_name]=N'WideWorldImporters'))
ADD TARGET package0.event_file(SET filename=N'tracesqlreads')
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
GO
ALTER EVENT SESSION [tracesqlreads] ON SERVER STATE=START
GO
然后执行下面命令,先清空buffer,然后通过SELECT COUNT(*)查询数据,这个查询指定了INDEX=1,默认就是聚集索引,这个简单的操作底层实际上就是把数据从磁盘加载到内存。这里也使用了SET STATISTICS IO 命令获取IO的统计信息。
USE [WideWorldImporters]
GO
DBCC DROPCLEANBUFFERS
GO
SET STATISTICS IO ON
GO
SELECT COUNT(*) FROM Sales.Invoices WITH (INDEX=1)
GO
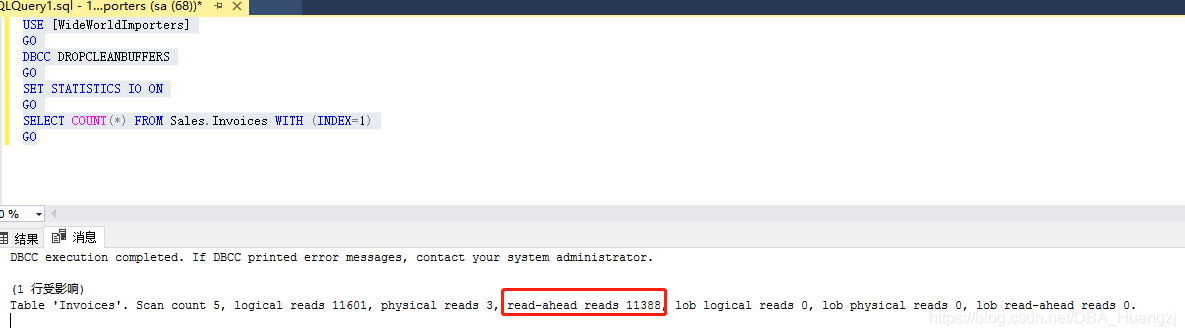
从下图可见read-ahead 有11388次
接下来停止扩展事件并查询结果:
--停止扩展事件
ALTER EVENT SESSION [tracesqlreads] ON SERVER STATE=STOP
GO
--查询扩展事件
SELECT [database_name] = xe_file.xml_data.value('(/event/action[@name="database_name"]/value)[1]','[nvarchar](128)'),
[read_size(KB)] = CAST(xe_file.xml_data.value('(/event/data[@name="size"]/value)[1]', '[nvarchar](128)') AS INT)/1024 ,
[file_path] = xe_file.xml_data.value('(/event/data[@name="path"]/value)[1]', '[nvarchar](128)')
--xe_file.xml_data
FROM
(
SELECT [xml_data] = CAST(event_data AS XML)
FROM sys.fn_xe_file_target_read_file('/var/opt/mssql/log/tracesqlreads*.xel', null, null, null)
) AS xe_file
GO
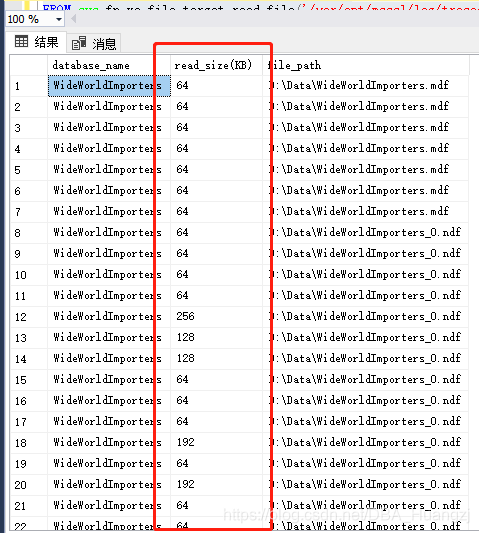
从下图结果可以看到实际取数的文件(file_path)和每次读取的大小(KB),有些文件上只读取了64KB每次,有些则为128KB,还有256等等。具体细节我们就不展开讨论,但是这里引出了另外一个最佳实践里面的建议,就是对大型数据库分多个数据文件(可能在同一个文件组也可能在不同文件组),并且分布在独立的物理驱动,同时让这些文件组尽可能初始化大小一致,增长程度一致。目的都是为了尽可能通过并行读取接近相同的数据量,一方面加快处理速度,另外一方面使操作不至于失衡。
Write-Ahead Logging
当SQL Server因为增删改等操作需要对buffer中的数据页进行修改时,如果必须等待每个已修改的数据页都写到磁盘才能算结束的话,那么SQL语句的性能将大大降低。但是由于SQL Server(关系数据库都一样)都包含事务日志文件,所以如果SQL Server能确保将所有的变更先写入日志文件,那么就没必要马上写入数据文件。
这种机制就叫做write-ahead logging(WAL,暂时称为预写式日志吧,中文其实不是很重要),WAL其实不是SQL Server的专利,大量的RDBMS(关系数据库管理系统)都有这个机制,比如Oracle、PG等。SQL Server通过这个机制,确保所有已提交事务的修改都能写进磁盘的事务日志文件,所有事务即使在数据文件未更新前均能保证事务的一致性,哪怕SQL Server On Linux/Windows突然出现宕机等情况下。
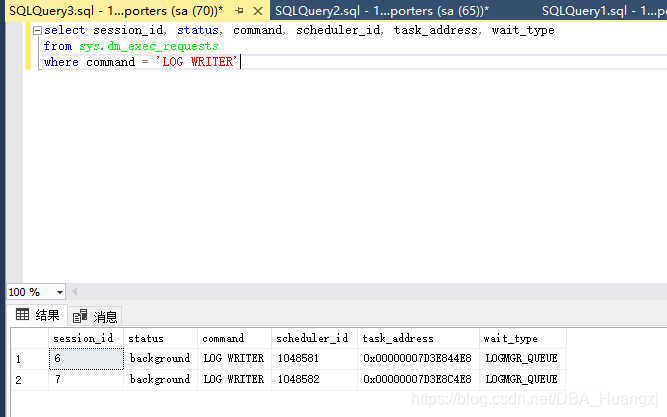
事务日志的写操作由后台任务LOG WRITER(可以通过sys.dm_exec_requests筛选LOG WRITER来查看)完成,为了得到更好的扩展性,从SQL Server 2016开始引入了基于NUMA节点的多个LOG WRITER任务。详见SQL 2016 – It Just Runs Faster: Multiple Log Writer Workers,比如本系列演示环境:
select session_id, status, command, scheduler_id, task_address, wait_type
from sys.dm_exec_requests
where command = 'LOG WRITER'
从SQL Server 2014也引入了一个叫delayed durability(延迟持久性)的功能,可以允许在事务未写入磁盘之前就标志事务已提交,从而加快事务的持续时间,提高响应速度,但是这种操作明显会带来数据丢失的风险。这部分的说明在“控制事务持续性”中可以查看。
Checkpoint,LazyWriters,Eager Writes
Checkpoints
加载到内存的数据,一旦被修改,就会标志为“脏页(dirty page)”,如果这些页一直都不移到磁盘做最终保存,那么事务日志就一直要记录这些信息,从而无限制地增长(单纯地限制增长也会导致数据库变成只读),日志的增长速度可以非常快,本人见过在几分钟之内就会增加几百G,很容易就导致服务器出现无法预估的空间增长从而最终停止服务。另外,超大的LDF文件也会在数据库备份和还原过程花费非常多的时间。
因此,SQL Server提供了一些技术来应对这类问题。默认情况下,SQL Server 2017使用“indirect checkpoint,间接检查点”来写入数据库页。它使用目标恢复时间(target recovery time)来决定什么时候获取脏页信息并写到对应的数据库数据文件中。这个目标恢复时间可以使用ALTER DATABASE TARGET_RECOVERY_TIME命令来配置,默认值为1分钟。
SQL Server还有一个automatic checkpoints的选项,这是SQL 2016之前的默认功能,使用sp_configure配置recovery interval来实现。但是在运行时可能会导致I/O写行为的密集出现。自动检查点使用后台任务CHECKPOINT来实现,(从sys.dm_exec_requests where command =‘RECOVERY WRITER’查看)。间接检查点的出现就是为了尽可能减少这种峰值的影响,它使用后台任务“RECOVERY WRITER”(从sys.dm_exec_requests where command =‘RECOVERY WRITER’查看)来进行操作。
除了上面两种主要的ckeckpoint类型之外,SQL Server还会针对某些特定的操作和事件触发checkpoint,完整的内容可以查阅官方文档:数据库检查点 (SQL Server)。如果要监控checkpoint,可以查看sys.dm_os_performance_counter 中object_name=’ SQLServer:Buffer Manager’ and counter_name=‘Background writer pages/sec’ (针对间接检查点)和查看sys.dm_os_performance_counter 中object_name=’ SQLServer:Buffer Manager’ and counter_name=‘Checkpoint pages/sec’ (针对自动检查点)。
Lazywrite
由于绝大部分服务器上的数据库体积都远大于物理内存的数量,所以内存无法真正缓存所有的数据。在系统运行的过程中,经常会出现所需的数据没有在缓存中,需要从硬盘上加载,但是缓存本身已经没有足够的空间,这个时候就需要吧缓存中的某些数据清空回去硬盘,首当其冲的就是那些在缓存中已被修改过的数据页(脏页),SQL Server使用WAL来进行这种操作以便保证数据的一致性,但是有些脏页还在未提交的事务中,它们可能在后续会被回滚,为了保证这种逻辑,在脏页写入之前,事务日志需要先记录。在所有buffer pool管理动作中写入脏页的操作统称lazywrite。通常由称为LAZY WRITER的后台进程执行(sys.dm_exec_requests where command=‘LAZY WRITER’)。
但是如果出现短时大容量数据变更,如SELECT …INTO/INSERT…SELECT等,使用lazywrite效率很低。这个时候SQL Server会使用Eager write(官网翻译为勤奋写入)来实现脏页写入。这种操作适合上面所述的属于大容量日志操作关联的脏页。以并行方式创建和写入新页,不需要等待整个操作完成就可以将页写入磁盘。
小结
检查点(checkpoint)、惰性写入(lazywrite)和勤奋写入(eager write)是三种脏页写入磁盘的方式。它们均不需要等待I/O操作完成,始终使用异步I/O实现。可以充分利用服务器的CPU和I/O资源。
数据压缩
对于B-tree索引而言,索引的层级直接影响索引效率,而层级的大小又跟数据页的数量有关系,如果每个数据页能容纳更多的数据,那么相同的数据就只需要更少的数据页从而提升索引性能,另外在数据库常规维护过程中,数据体积越小越好,这个就没必要多说了。SQL Server 从2008版开始引入了数据压缩技术,包含页压缩和行压缩,使得更少的数据页需要加载并驻留在buffer中,这个已经是很成熟的功能,在后续章节会提到另外一种压缩,就是使用列存储索引。但是注意压缩和解压由于需要额外的CPU进行计算,所以并不是所有地方都通用的。读者可以先行阅读Data Compression。这里先不多说。
总结
本文从SQL Server内部介绍了SQL Server关于I/O方面的特性。有些是SQL Server 2016开始引入的新特性,有些则是出现时间较久但是依旧有效的特性。下一篇将从配置层面去介绍如何最大化SQL Server特别是Linux平台的性能。
