文章目录
1. Java内存模型

1. 可见性
退不出的循环:
先来看一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
public class Test32 {
// 易变
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(true){
if(!run) {
break;
}
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
}
为什么呢?分析一下:
(1) 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
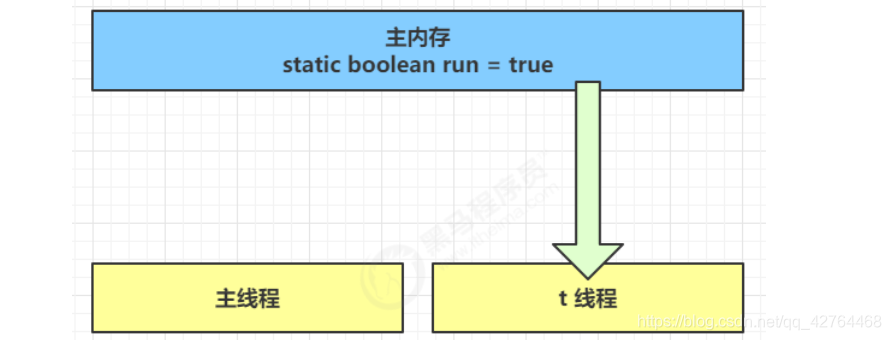
(2) 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
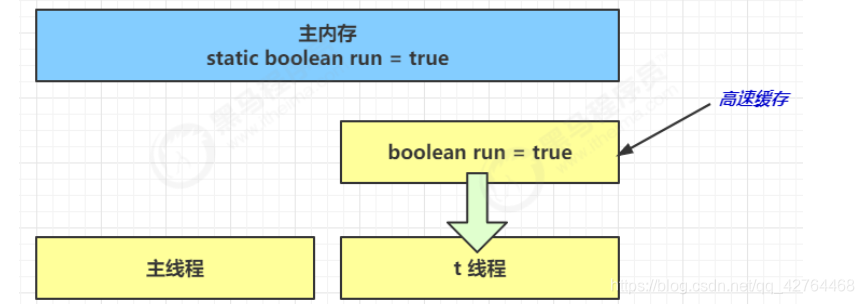
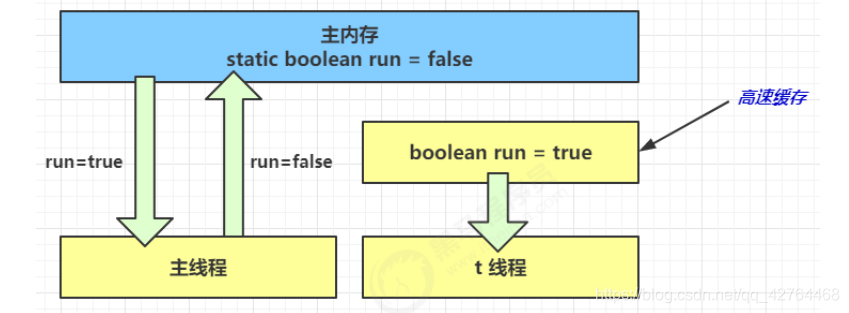
(3) 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
解决方法:
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
@Slf4j(topic = "c.Test32")
public class Test32 {
// 易变
volatile static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(true){
if(!run) {
break;
}
}
});
t.start();
sleep(1);
run = false;
}
}

2. 可见性 vs 原子性

3. 有序性
 volatile 修饰的变量,可以禁用指令重排
volatile 修饰的变量,可以禁用指令重排
4. volatile原理
 1、如何保证可见性:
1、如何保证可见性:
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中

而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据

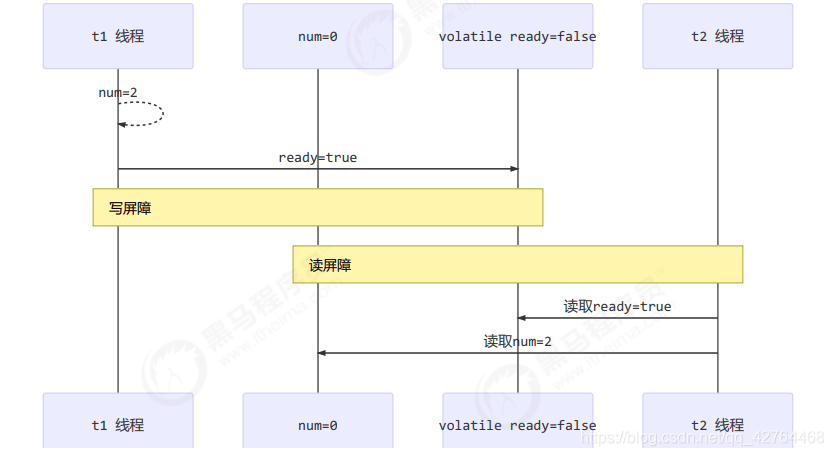 2、如何保证有序性:
2、如何保证有序性:
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后

读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前

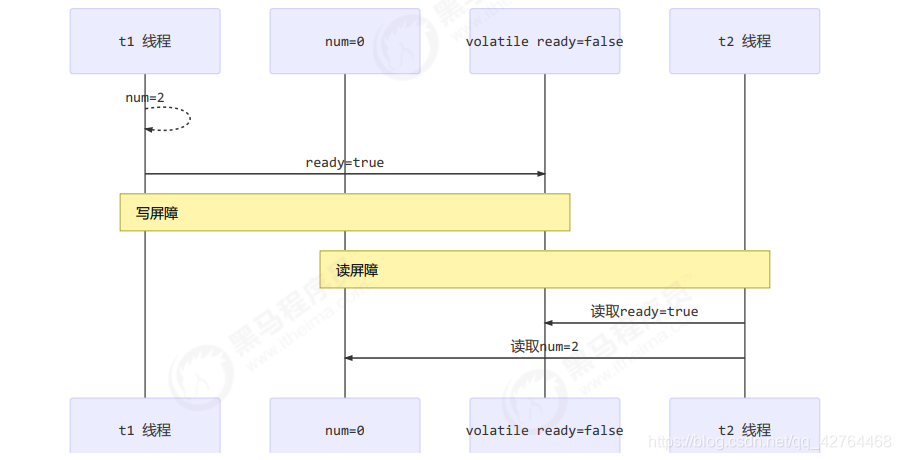 还是那句话,不能解决指令交错:
还是那句话,不能解决指令交错:
写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
而有序性的保证也只是保证了本线程内相关代码不被重排序
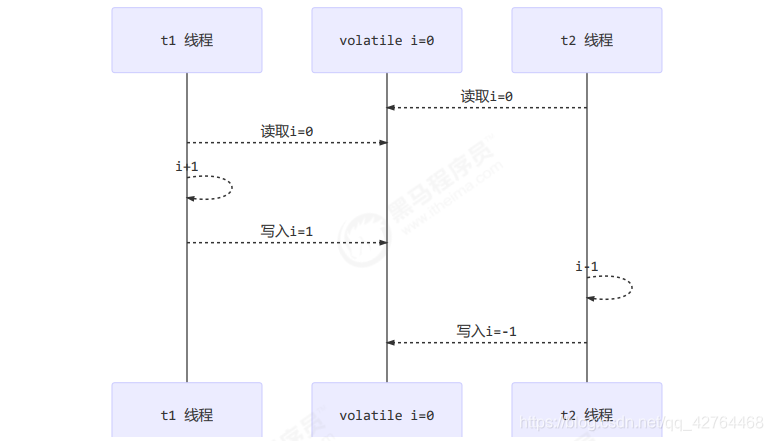
3、double-checked locking 问题
单例设计模式:
 以上的实现特点是:
以上的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
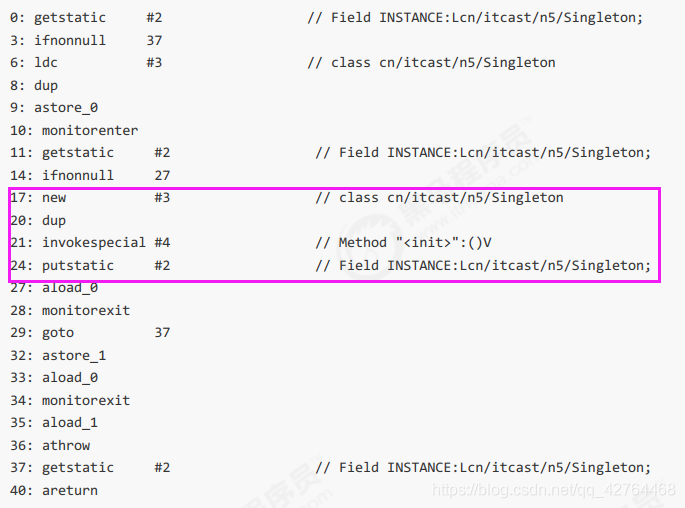

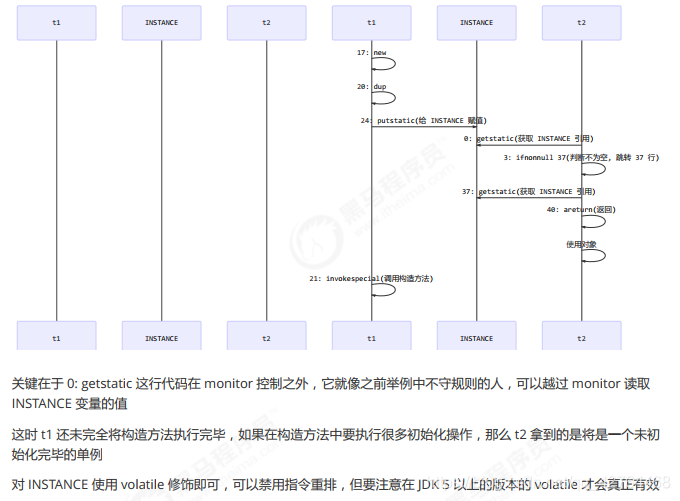

// -------------------------------------> 加入对 INSTANCE 变量的读屏障
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
3: ifnonnull 37
6: ldc #3 // class cn/itcast/n5/Singleton
8: dup
9: astore_0
10: monitorenter -----------------------> 保证原子性、可见性
11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
14: ifnonnull 27
17: new #3 // class cn/itcast/n5/Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
// -------------------------------------> 加入对 INSTANCE 变量的写屏障
27: aload_0
28: monitorexit ------------------------> 保证原子性、可见性
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
40: areturn
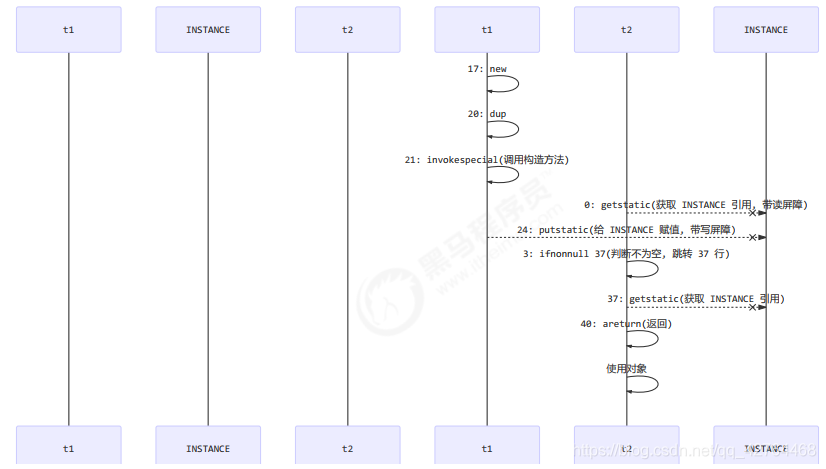
如上面的注释内容所示,读写 volatile 变量时会加入内存屏障,保证下面两点:
- 可见性
写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据 - 有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
5. happens-before
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
- 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见

- 线程对 volatile 变量的写,对接下来其它线程对该变量的读可见

- 线程 start 前对变量的写,对该线程开始后对该变量的读可见

- 线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待它结束)

- 线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过t2.interrupted 或 t2.isInterrupted)
- 对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
2. 无锁
问题提出:
public class TestAccount {
public static void main(String[] args) {
Account account = new AccountCas(10000);
Account.demo(account);
}
}
//使用无锁的方式也能保证线程安全
class AccountCas implements Account {
private AtomicInteger balance;
public AccountCas(int balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return balance.get();
}
@Override
public void withdraw(Integer amount) {
while(true) {
// 获取余额的最新值
int prev = balance.get();
// 要修改的余额
int next = prev - amount;
// 真正修改
if(balance.compareAndSet(prev, next)) {
break;
}
}
// balance.getAndAdd(-1 * amount);
}
}
//对成员变量使用同步保证线程安全
class AccountUnsafe implements Account {
private Integer balance;
public AccountUnsafe(Integer balance) {
this.balance = balance;
}
@Override
public Integer getBalance() {
synchronized (this) {
return this.balance;
}
}
@Override
public void withdraw(Integer amount) {
synchronized (this) {
this.balance -= amount;
}
}
}
interface Account {
// 获取余额
Integer getBalance();
// 取款
void withdraw(Integer amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(Account account) {
List<Thread> ts = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(10);
}));
}
long start = System.nanoTime();
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance()
+ " cost: " + (end-start)/1000_000 + " ms");
}
}
1. CAS与Volatile
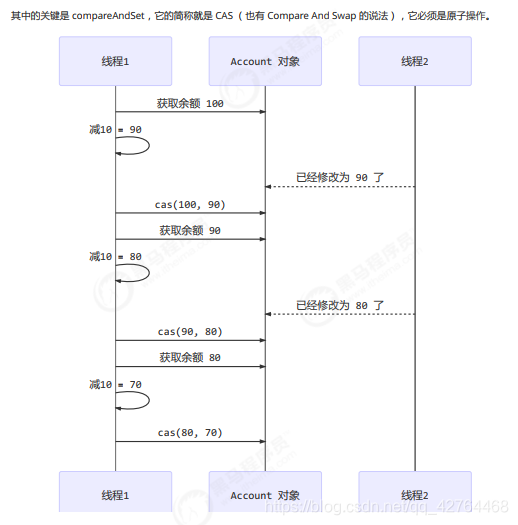
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
1、CAS:compareAndSet
@Override
public void withdraw(Integer amount) {
while (true) {
// 获取余额的最新值
int prev = balance.get();
// 要修改的余额
int next = prev - amount;
// 真正修改
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
2、volatile:
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意:
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
3、为什么无锁效率高:
- 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。
- 打个比喻:线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火,等被唤醒又得重新打火、启动、加速… 恢复到高速运行,代价比较大
- 但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
4、CAS的特点:
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
- CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思,因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一,但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
2. 原子整数

以 AtomicInteger 为例:
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++
System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i
System.out.println(i.incrementAndGet());
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i
System.out.println(i.decrementAndGet());
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i--
System.out.println(i.getAndDecrement());
// 获取并加值(i = 0, 结果 i = 5, 返回 0)
System.out.println(i.getAndAdd(5));
// 加值并获取(i = 5, 结果 i = 0, 返回 0)
System.out.println(i.addAndGet(-5));
// 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.getAndUpdate(p -> p - 2));
// 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.updateAndGet(p -> p + 2));
// 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
// getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
3. 原子引用

数据类型有可能不是整型的,而是引用类型AtomicReference:
public class Test35 {
public static void main(String[] args) {
DecimalAccount.demo(new DecimalAccountCas(new BigDecimal("10000")));
}
}
class DecimalAccountCas implements DecimalAccount {
private AtomicReference<BigDecimal> balance;
public DecimalAccountCas(BigDecimal balance) {
this.balance = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return balance.get();
}
@Override
public void withdraw(BigDecimal amount) {
while(true) {
BigDecimal prev = balance.get();
BigDecimal next = prev.subtract(amount);
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
}
AtomicStampedReference:
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
// 这个共享变量被它线程修改过?
String prev = ref.get();
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C"));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}

主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程希望:
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号:AtomicStampedReference
@Slf4j(topic = "c.Test36")
public class Test36 {
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B", ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A", ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
}
结果:
15:45:25.595 c.Test36 [main] - main start...
15:45:25.634 c.Test36 [main] - 版本 0
15:45:25.860 c.Test36 [t1] - change A->B true
15:45:25.862 c.Test36 [t1] - 更新版本为 1
15:45:26.360 c.Test36 [t2] - change B->A true
15:45:26.361 c.Test36 [t2] - 更新版本为 2
15:45:27.361 c.Test36 [main] - change A->C false
AtomicMarkableReference:
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A ->C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference
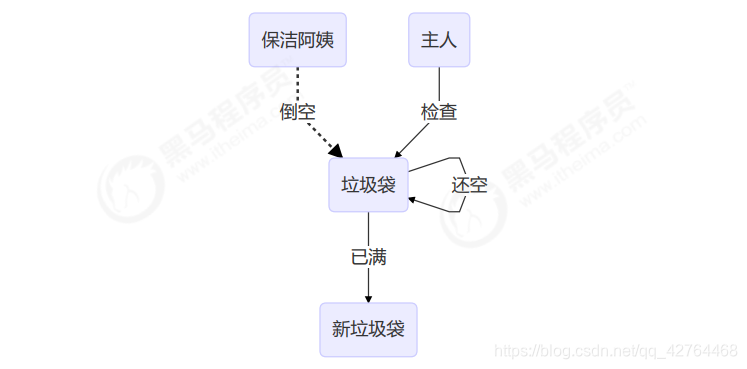
@Slf4j(topic = "c.Test38")
public class Test38 {
public static void main(String[] args) throws InterruptedException {
GarbageBag bag = new GarbageBag("装满了垃圾");
// 参数2 mark 可以看作一个标记,表示垃圾袋满了
AtomicMarkableReference<GarbageBag> ref = new AtomicMarkableReference<>(bag, true);
log.debug("start...");
GarbageBag prev = ref.getReference();
log.debug(prev.toString());
new Thread(() -> {
log.debug("start...");
bag.setDesc("空垃圾袋");
ref.compareAndSet(bag, bag, true, false);
log.debug(bag.toString());
},"保洁阿姨").start();
sleep(1);
log.debug("想换一只新垃圾袋?");
boolean success = ref.compareAndSet(prev, new GarbageBag("空垃圾袋"), true, false);
log.debug("换了么?" + success);
log.debug(ref.getReference().toString());
}
}
class GarbageBag {
String desc;
public GarbageBag(String desc) {
this.desc = desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return super.toString() + " " + desc;
}
}
4. 原子数组

如不想修改引用本身,但是想修改对象里面的值,就可以使用原子数组,比如修该数组里的值,但不是数组的引用。
5. 字段更新器

@Slf4j(topic = "c.Test40")
public class Test40 {
public static void main(String[] args) {
Student stu = new Student();
AtomicReferenceFieldUpdater updater =
AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
//将null更新成张三
System.out.println(updater.compareAndSet(stu, null, "张三"));
System.out.println(stu);
}
}
@Data
class Student {
volatile String name;
}
6. 原子累加器
public class Test41 {
public static void main(String[] args) {
//使用AtomicLong
for (int i = 0; i < 5; i++) {
demo(
() -> new AtomicLong(0),
(adder) -> adder.getAndIncrement()
);
}
//使用LongAdder
for (int i = 0; i < 5; i++) {
demo(
() -> new LongAdder(),
adder -> adder.increment()
);
}
}
/*
() -> 结果 提供累加器对象
(参数) -> 执行累加操作
*/
private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
List<Thread> ts = new ArrayList<>();
// 4 个线程,每人累加 50 万
for (int i = 0; i < 4; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
long start = System.nanoTime();
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start) / 1000_000);
}
}
结果:LongAdder()效率更高
2000000 cost:45
2000000 cost:23
2000000 cost:32
2000000 cost:56
2000000 cost:41
2000000 cost:36
2000000 cost:14
2000000 cost:19
2000000 cost:20
2000000 cost:17
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
