spark中常用的算子:
map算子:
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素,途中每个方框表示一个RDD分区,左侧的分区经过用户自定义函数f 映射为右侧的新RDD分区,但是,实际只有等到action算子触发后,这个f函数才会和其他函数在一个stage中的数据进行运算
mapValues算子:
针对(key,value)型数据中的value进行map操作 而不对key进行处理 图中的方框代表RDD分区 a=>a+2 代表针对(V1,1)这样的Key value数据对,数据支队value中的1进行加2的操作
flatmap 算子
将原来R得到中的每个元素通过函数f转换为新的元素,并将生成的RDD的每个分区中多个集合中的元素合并为一个集合
mapPartition算子:
针对每一个分区 ,在函数中通过这个分区整体的迭代器对整个分区的元素进行操作
union算子: 取并集
需要保证两个RDD元素的数据类型相同,返回的RDD数据类型和被合并的RDD元素数据类型相同,并不进行去重操作,保存所有元素
**intersection算子:**取交集
该函数返回两个RDD的交集,并且去重
groupbykey算子:
在执行该算子之前,需要将元素通过函数生成相应的Key,数据就转化为key-value格式,之后利用该算子将Key相同的元素分为一组 可以指定最后生成多少个分区 groupbykey(x),x确定了分区个数和分区函数,决定了并行化的程度
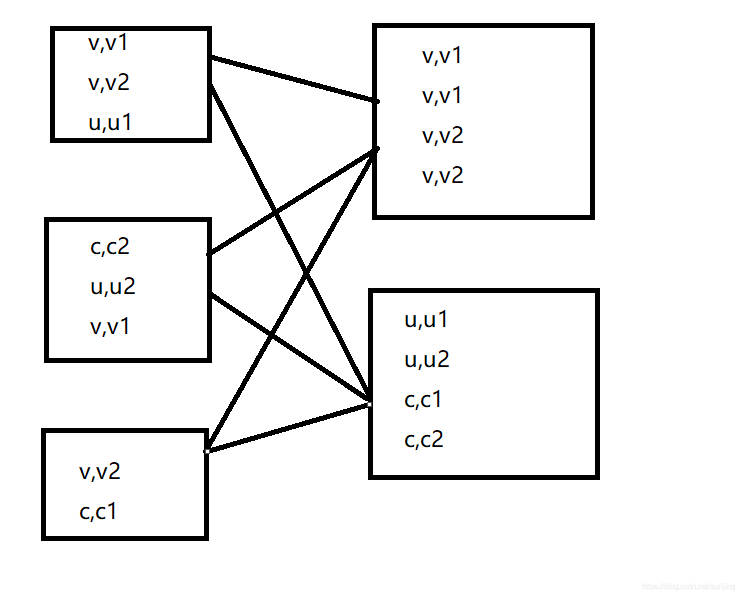
Combinebykey : aggregateByKey foldByKey reduceByKey 等函数都是基于该函数实现的 相当于将元素为(int,int的rdd转变为了(int seq[int])类型元素的RDD)
(V1,2)
(V1,1)------>(V1,seq(2,1))
Reducebykey:
两个值合并成一个值,(int,int v)====>(int,intC)
通过用户自定义函数(A,B):(A+B)函数,将相同key的数据(v1,1),(v1,2)---->(v1,3)
aggregatebykey :
以分区为单位进行操作,aggregatebykey(初始值,函数1,函数2)
例:函数1定义的逻辑是求每个key的多个value的最大值,
函数2定义的逻辑是求和,
底层实现:
1.针对每一个分区内相同的key,一次比较初始值和v1,返回值和v2,返回值….直到获取到最大值
2.将不同分区得到的统计结果进行汇总,汇总的方式是将相同key的统计结果相加
Sortbykey:
按照key值排序
join算子:
对两个需要连接的RDD进行cogroup函数操作,将先相同key的数据能够放到同一个分区,在cogroup操作之后形成的新RDD对每个key下的元素进行笛卡尔积的操作,返回的结果再展平,对应key下的所有元祖形成一个集合,返回RDD[(K,(V,W))]
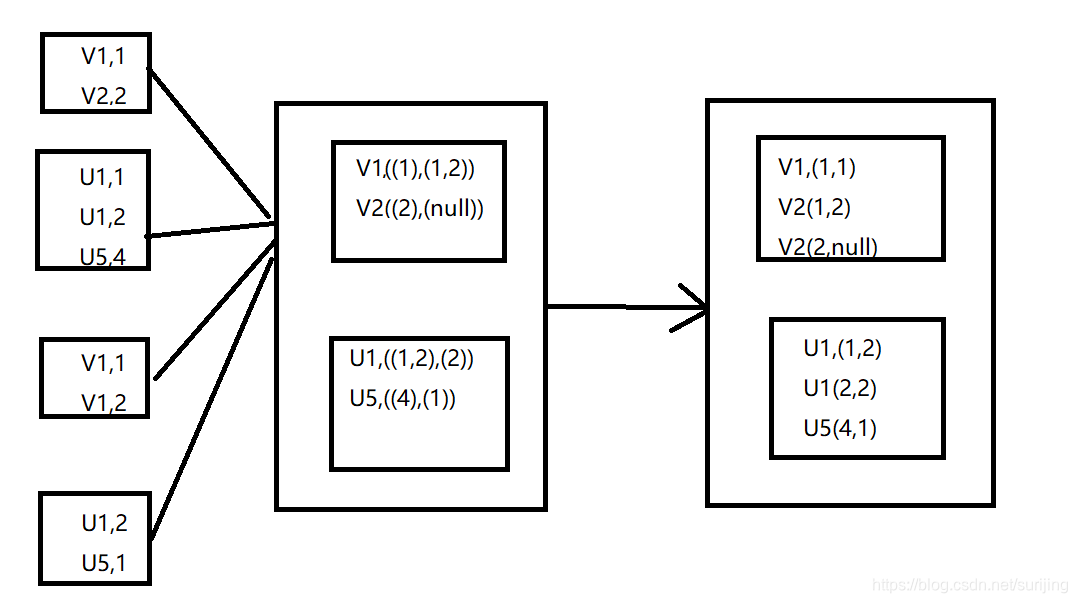
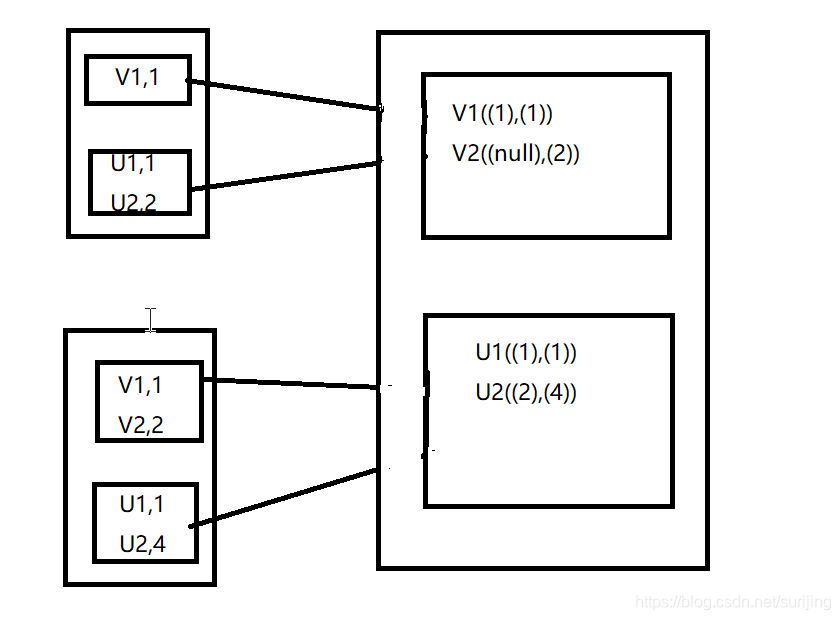
cogroup算子:
cogroup函数将两个RDD进行协同划分,对在两个RDD中的key-value类型的元素,每个RDD相同key的元素分别聚合为一个集合,并且返回两个RDD中对应key的元素集合的迭代器:(K,(Iterable[V],Iterable[W]))其中,value是两个RDD下相同key的两个数据集合的迭代器所构成的元祖
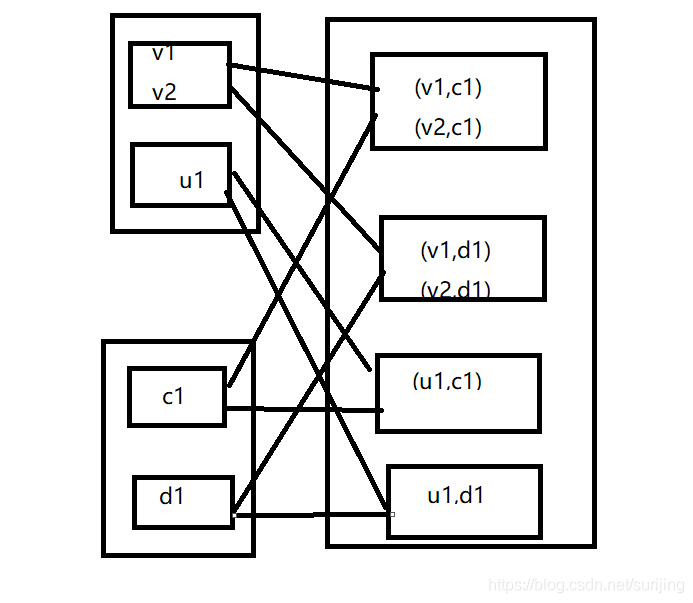
cartesian算子:
对两个RDD内的所有元素进行笛卡尔积操作
repartition算子:
对输入RDD重新分区
输出分区为输入分区子集
filter算子:
对元素进行过滤,返回值为boolen类型,true在RDD中保留,false将被过滤
Sample(false,0.001,20):
False:是否放回
0.001:概率
20:随机数种子
对于RDD中每个partition的数据按照抽样率进行抽样,并返回一个新的RDD
Takesample(action算子):
直接可以打印数据集
java开发:
package com.spark;
import java.io.File;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.cassandra.cli.CliParser.newColumnFamily_return;
import org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.intervalLiteral_return;
import org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.nullCondition_return;
import org.apache.hadoop.ipc.RetriableException;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.netlib.blas.Srot;
public class RDDOperation {
static String basedir = System.getProperty("user.dir"+File.separator+"conf"+File.separator);
public static void main(String[] args) {
SparkConf conf =new SparkConf().setAppName("RDDOperation").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
mapDemo(sc);
System.out.println("-------------");
flatMapDemo(sc);
System.out.println("-------------");
filterDemo(sc);
System.out.println("-------------");
sampleDemo(sc);
System.out.println("-------------");
mapPartitionDemo(sc);
System.out.println("-------------");
groupByKeyDemo(sc);
System.out.println("-------------");
reduceByKeyDemo(sc);
System.out.println("-------------");
}
private static void mapDemo(JavaSparkContext sc) {
List<String> list =Arrays.asList("hadoop hbase hdfs spark storm","java scala python");
JavaRDD<String> stringRdd =sc.parallelize(list);//只有一个分区
// [hadoop hbase hdfs spark storm, java scala python]
// System.out.println(stringRdd.collect());
// map函数把rdd中的每一个元素传进来 一个元素“hadoop hbase hdfs spark stormpoiup”
JavaRDD<String[]>splitRdd =stringRdd.map(
new Function<String,String[]>(){
public static final long serialVersionUID=1L;
// call方法会被反复调用
public String[] call(String v1) {
return v1.split(" ");
}
});
List<String[]> result =splitRdd.collect();
for (int i = 0; i <result.size(); i++) {
for(String s :result.get(i)) {
System.out.println("Array"+i+"Data:"+ s);
}
}
}
private static void flatMapDemo(JavaSparkContext sc) {
List<List<String>> list =Arrays.asList(
Arrays.asList("hadoop hbase hdfs spark storm","java scala python"),
Arrays.asList("java scala python","beijing","zhejiang","shanghai"));
JavaRDD<List<String>> stringRdd =sc.parallelize(list);
JavaRDD<String>flatmapRdd=stringRdd.flatMap(
new FlatMapFunction<List<String>, String>() {
private static final long serialVersionUID=1L;
List<String> list =new ArrayList<String>();
String[] wordArr = null;
StringBuilder sb = new StringBuilder();
@Override
public Iterable<String> call(List<String> s) {
for (int i =0;i<s.size();i++) {
sb.append(s.get(i));
sb.append(" ");
}
wordArr = sb.toString().split(" ");
for (String word : wordArr) {
list.add(word);
}
return list;
}
});
System.out.println("source data "+ stringRdd.collect());
System.out.println("flatmapoutput"+ flatmapRdd.collect());
}
private static void filterDemo(JavaSparkContext sc) {
List<String> list = Arrays.asList("hadoop hbase hdfs spark strom","java scala r");
JavaRDD<String> stringRdd = sc.parallelize(list);
JavaRDD<String> filterRDD = stringRdd.filter(
new Function<String, Boolean>()
{
private static final long servialVersionUID=1L;
public Boolean call(String s) {
// s 包含两个元素
return s.contains("j");
// 返回“java scala r”
}
});
System.out.println(filterRDD.collect());
}
private static void mapPartitionDemo(JavaSparkContext sc) {
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
JavaRDD<Integer> intRdd = sc.parallelize(list,2);
// 传进来的是一个一个分区
JavaRDD<Integer> mapPartitionRdd = intRdd.mapPartitions(
new FlatMapFunction<Iterator<Integer>, Integer>() {
private static final long servialVersionUID=1L;
public Iterable<Integer> call(Iterator<Integer> integerIterator) throws Exception {
List<Integer> list =new ArrayList<>();
while (integerIterator.hasNext()) {
list.add(integerIterator.next());
}
list.add(0);
return list;
}
});
System.out.println(mapPartitionRdd.collect());
}
private static void sampleDemo(JavaSparkContext sc) {
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
JavaRDD<Integer> intRdd= sc.parallelize(list);
// 是否放回采样 采样的概率 随机种子
JavaRDD<Integer> sampleRdd = intRdd.sample(false, 0.001,20);
System.out.println(sampleRdd.partitions().size());
System.out.print(sampleRdd.collect());
}
private static void groupByKeyDemo(JavaSparkContext sc) {
List<String> list =Arrays.asList("dog","tiger","lion","cat","spider","elephent");
JavaPairRDD<Integer, String> pairRDD = sc.parallelize(list).keyBy(new Function<String, Integer>() {
private static final long serialVersionUID=1L;
public Integer call(String v1) {
return v1.length();
}
});
JavaPairRDD<Integer, Iterable<String>> groupByPairRDD = pairRDD.groupByKey();
System.out.println(groupByPairRDD.collect());
}
private static void reduceByKeyDemo(JavaSparkContext sc) {
List<String> list = Arrays.asList("dog","cat","owl","gnu","ant");
JavaPairRDD<Integer, String> pairRDD = sc.parallelize(list).keyBy(new Function<String, Integer>() {
private static final long serialVersionUID=1L;
public Integer call(String v1) {
return v1.length();
// 返回 3,dog 3,cat....
}
});
//
JavaPairRDD<Integer, String> reduceByRdd = pairRDD.reduceByKey(
// 两个输入 一个输出
// 1.<k1,v1>中的v1 和 <k2,v2>中的v2 -----》 v1_v2
// v1-v2 v3----》v1-v2-v3
new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
// TODO Auto-generated method stub
return v1 + "-" + v2;
}
});
System.out.print(reduceByRdd.collect());
}
}
