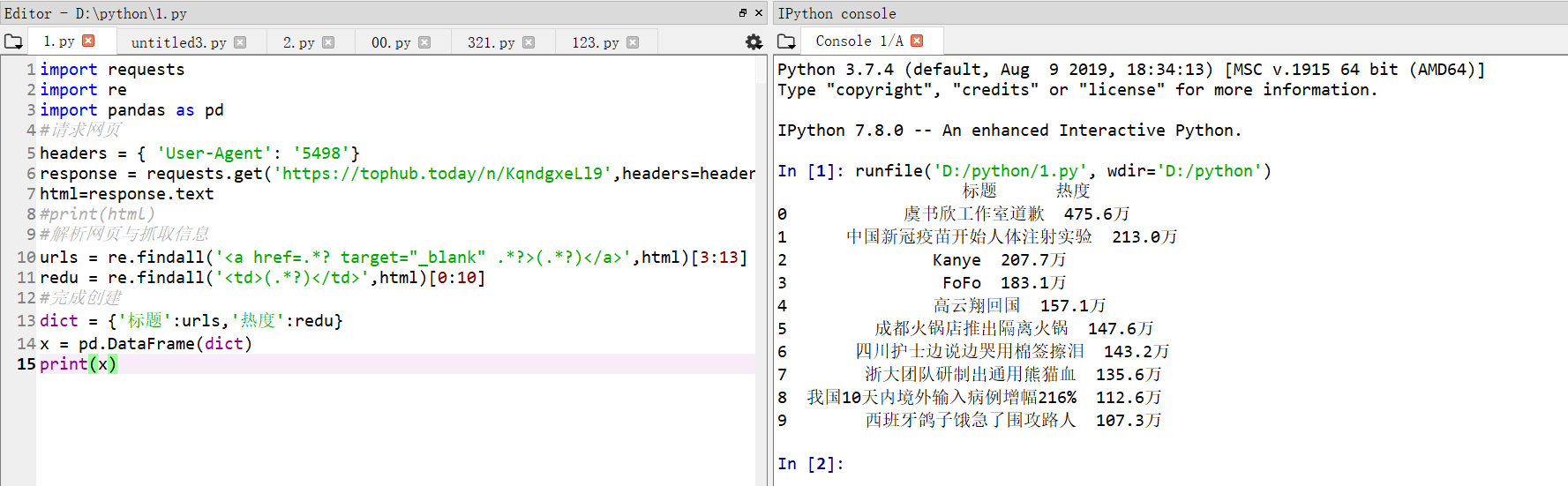
import requests
import re
import pandas as pd
#请求网页
headers = { 'User-Agent': '5498'}
response = requests.get(' https://tophub.today/n/KqndgxeLl9',headers=headers)
https://tophub.today/n/KqndgxeLl9',headers=headers)
html=response.text
#print(html)
#解析网页与抓取信息
urls = re.findall('<a href=.*? target="_blank" .*?>(.*?)</a>',html)[3:13]
redu = re.findall('<td>(.*?)</td>',html)[0:10]
#完成创建
dict = {'标题':urls,'热度':redu}
x = pd.DataFrame(dict)
print(x)