本文讲解双目系统
入门
原文:http://avisingh599.github.io/vision/visual-odometry-full/
I will basically present the algorithm described in the paper Real-Time Stereo Visual Odometry for Autonomous Ground Vehicles, with some of my own changes.
- 论文下载地址:(Howard2008,https://www-robotics.jpl.nasa.gov/publications/Andrew_Howard/howard_iros08_visodom.pdf)
这是一篇较旧的论文,但很容易理解,这就是为什么我在第一个实现中使用它的原因。相同的MATLAB源代码可在github(https://github.com/avisingh599/vo-howard08)上找到。
What is odometry?
机器人里程表是一个更通用的术语,通常指的不仅是估计行进的距离,还包括估计移动机器人的整个轨迹。 因此,对于每个时间实例t,都有一个向量 描述了该实例机器人的完整姿态。 注意,这里的αt,βt,γt是欧拉角,而xt,yt,zt是机器人的直角坐标系。
欧拉角:http://mathworld.wolfram.com/EulerAngles.html
What’s visual odometry?
我们的工作是使用来自此摄像头的视频流来构建6自由度轨迹 6-DOF( s)。
6-DOF: https://en.wikipedia.org/wiki/Six_degrees_of_freedom
Why stereo, or why monocular?
When we are using just one camera, it’s called Monocular Visual Odometry.
When we’re using two (or more) cameras, it’s refered to as Stereo Visual Odometry.
在单眼VO中,您只能说在x中移动了一个单位,在y中移动了两个单位
而在双目中,您可以说您在x中移动了一米,在y中移动了2米,通常更健壮(由于有更多数据可用)。
但是,在物体与摄像机之间的距离过大的情况下(与到立体系统的两个摄像机之间的距离相比),立体情况会退化为单目情况。因此,假设您有一个很小的机器人(例如robobees),那么拥有双目系统就没有用了,而采用SVO之类的单眼VO算法会更好。
系统输入
我们有来自一对摄像机的(灰度/彩色)图像流。 将在时间t和t + 1捕获的左右帧称为It1,Itr,It + 1l,It + 1r。
系统输出
对于每对立体图像,我们需要找到旋转矩阵R和平移矢量t,它们描述了两个帧之间车辆的运动。
过程An outline:
如果您不了解上面看到的某些术语(例如视差图或FAST功能),请不要担心。 它们中的大多数将在后面的文字中进行详细说明,以及在MATLAB中使用它们的代码。
第一步:Capture images:
第二:Undistort, Rectify the above images.不失真,校正以上图像。
第三:Compute the disparity map from , and the map $D_{t+1} from .计算视差图 ,
第四:Use FAST algorithm to detect features in Itl, It+1l and match them.使用FAST算法检测 中的特征并进行匹配。
第五:Use the disparity maps Dt, Dt+1 to calculate the 3D posistions of the features detected in the previous steps. Two point Clouds Wt, Wt+1 will be obtained使用视差图Dt,Dt1计算在先前步骤中检测到的特征的3D位置。 将获得两点云Wt,Wt + 1
第六:Select a subset of points from the above point cloud such that all the matches are mutually compatible.从上面的点云中选择点的子集,以使所有匹配项相互兼容。
第七:Estimate R,t from the inliers that were detected in the previous step.
图像校正
在计算视差图之前,我们必须执行许多预处理步骤。
不失真:此步骤可补偿镜头失真。 它是在校准过程中获得的失真参数的帮助下执行的。
纠正:执行此步骤是为了缓解视差图计算的问题。 在这一步骤之后,所有对极线都变得平行于水平线,并且视差计算步骤仅需要在一个方向上执行其对匹配块的搜索。
这两个操作都是在MATLAB中实现的,并且由于我在实现中使用的KITTI视觉Odometry数据集已经实现了这些操作,因此在我的实现中找不到用于它们的代码。
matlab中:
- rectifyStereoImages:https://www.mathworks.com/help/vision/ref/rectifystereoimages.html?searchHighlight=rectifyStereoImages
- undistortimage:https://www.mathworks.com/help/vision/ref/undistortimage.html
视差图计算
给定一对来自立体摄像机的图像,我们可以计算视差图。 假设物理世界F中的特定3D位于左图像中的位置(x,y),并且同一特征位于第二幅图像中的(x + d,y)上,然后是位置(x,y )在视差图上的值为d。 请注意,由于图像已校正,因此y坐标相同。 因此,我们可以将像平面中每个点的视差定义为:d = xl-xr
Block-Matching Algorithm块匹配算法
使用滑动窗口计算每个点的视差。 对于左图像中的每个像素,将在其周围生成一个15x15像素宽的窗口,并存储该窗口中所有像素的值。 然后,在右侧图像中的同一坐标处构造此窗口,然后将其水平滑动,直到绝对差总和(SAD)最小。 我们的实现中使用的算法是该块匹配技术的高级版本,称为“半全局块匹配算法”。 一个函数直接在MATLAB中实现此算法:
disparityMap1 = disparity(I1_l,I1_r, 'DistanceThreshold', 5);
FAST
我的方法使用FAST拐角检测器。现在,我将简要说明检测器的工作原理,但是如果您想真正了解它的工作原理,则必须查看原始的论文和源代码。http://www.edwardrosten.com/work/fast.html
假设有一个点P,我们要测试它是否为拐角。我们围绕该点绘制一个16px圆周的圆,如下图所示。对于位于该圆的圆周上的每个像素,我们查看是否存在一组连续的像素,这些像素的强度比原始像素的强度超出某个因子I;对于另一组连续的像素,如果强度小于至少是同一因素I。如果是,那么我们将此点标记为拐角。
使用启发式方法排除绝大多数非角,其中首先检查1,9,5,13处的像素,并且其中至少三个必须具有较高的强度,至少为I,或者必须具有强度降低相同的数量I,使该点成为拐角。之所以选择这种特殊方法,是因为其与其他流行的兴趣点检测器(例如SIFT)相比具有计算效率高。

bucketing
我们用这种方法做的另一件事是所谓的“bucketing存储桶”。 如果我们仅对整个图像运行特征检测器,则很有可能大多数特征都将集中在图像的某些丰富区域,而某些其他区域将没有任何表示。 这对我们的算法不利,因为它依赖于静态场景的假设,并且要找到“真实”静态场景,我们必须查看所有图像,而不仅仅是图像的某些区域。
为了解决此问题,我们将图像划分为网格(大约100x100像素),并从每个网格中最多提取20个特征,从而保持特征的更均匀分布。
points1_l = bucketFeatures(I1_l, h, b, h_break, b_break, numCorners);
function points = bucketFeatures(I, h, b, h_break, b_break, numCorners)
% input image I should be grayscale
y = floor(linspace(1, h - h/h_break, h_break));
x = floor(linspace(1, b - b/b_break, b_break));
final_points = [];
for i=1:length(y)
for j=1:length(x)
roi = [x(j),y(i),floor(b/b_break),floor(h/h_break)];
corners = detectFASTFeatures(I, 'MinQuality', 0.00, 'MinContrast', 0.1, 'ROI',roi );
corners = corners.selectStrongest(numCorners);
final_points = vertcat(final_points, corners.Location);
end
end
points = cornerPoints(final_points);
KLT跟踪器
令Itl中检测到的特征集为Ft,It + 1l中对应的特征集为Ft + 1。
In MATLAB, this is again super-easy to do, and the following three lines intialize the tracker, and run it once.
tracker = vision.PointTracker('MaxBidirectionalError', 1);
initialize(tracker, points1_l.Location, I1_l);
[points2_l, validity] = step(tracker, I2_l);
请注意,在我当前的实现中,我只是跟踪从一帧到下一帧的点,然后再次执行检测部分,但更好的实现是,只要点的数量不低于 一个特定的阈值。
Triangulation of 3D PointCloud
Ft和Ft + 1中所有点的真实世界3D坐标是使用视差图中与这些特征相对应的视差值相对于左摄像机计算的,
两个相机P1和P2的已知投影矩阵。 我们首先使用P1和P2中的数据形成重投影矩阵Q:

cx =左摄像机光学中心的x坐标(以像素为单位)
cy =左摄像机光学中心的y坐标(以像素为单位)
f =第一个相机的焦距
Tx =右摄像机相对于第一个摄像机的x坐标(以米为单位)
我们使用以下关系获取Ftl和Ft + 1l中每个要素的3D坐标

令从中获得的点云集称为Wt和Wt + 1。
To have a better understanding of the geometry that goes on in the above equations, you can have a look at the Bible of visual geometry i.e. Hartley and Zisserman’s Multiple View Geometry.
http://www.robots.ox.ac.uk/~vgg/hzbook/
The Inlier Detection Step
it does not have an outlier detection step, but it has an inlier detection step.
我们假设场景是刚性的,因此在时间实例t和t + 1之间一定不能改变。
结果,点云Wt中任意两个特征之间的距离必须与Wt + 1中相应点之间的距离相同。
如果任何两个特征之间的距离都不相同,则可能是两个要素中至少一个要素的3D三角剖分出现了错误,或者我们对移动进行了三角化。而我们不能在下一步中使用它。
为了获得最大的一致性匹配集,我们形成一致性矩阵M使得:
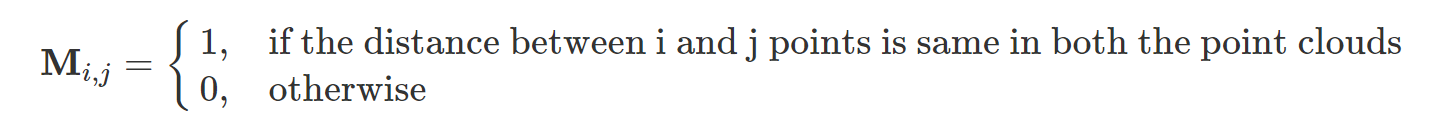
现在,从原始点云中,我们希望选择最大的子集,以使它们是该子集中的所有点彼此一致的(归约一致性矩阵中的每个元素均为1)。
This problem is equivalent to the Maximum Clique Problem, with M as an adjacency matrix.
此问题等效于最大分团问题,其中M为邻接矩阵。
在计算复杂度理论中,分团问题(clique problem)是图论中的一个NP完全(NP-complete)问题。
A cliques is basically a subset of a graph, that only contains nodes that are all connected to each other. An easy way to visualise this is to think of a graph as a social network, and then trying to find the largest group of people who all know each other.
分团是图的子集,只包含彼此连接的节点。
一种简单的可视化方法是将图形视为社交网络,然后尝试找到最大的彼此认识的人群。
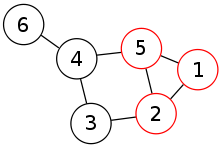
已知此问题是NP-complete的,因此对于任何实际情况都找不到最佳解决方案。
NP完全问题(NP-C问题),是世界七大数学难题之一。 NP的英文全称是Non-deterministic Polynomial的问题,即多项式复杂程度的非确定性问题。

因此,我们采用贪婪的启发式greedy heuristic 方法,这使我们有了一个接近最佳解决方案的分团:
- 选择具有最大degree的节点,然后初始化分团以包含该节点。
- 从现有分团 中,确定节点v的子集,这些节点v连接到分团中存在的所有节点。
- 从集合v中,选择一个连接到v中其他节点最大数量的节点。从第2步重复进行,直到无法再将其他节点添加到分团 中。
function cl = updateClique(potentialNodes, clique, M)
maxNumMatches = 0;
curr_max = 0;
for i = 1:length(potentialNodes)
if(potentialNodes(i)==1)
numMatches = 0;
for j = 1:length(potentialNodes)
if (potentialNodes(j) & M(i,j))
numMatches = numMatches + 1;
end
end
if (numMatches>=maxNumMatches)
curr_max = i;
maxNumMatches = numMatches;
end
end
end
if (maxNumMatches~=0)
clique(length(clique)+1) = curr_max;
end
cl = clique;
function newSet = findPotentialNodes(clique, M)
newSet = M(:,clique(1));
if (size(clique)>1)
for i=2:length(clique)
newSet = newSet & M(:,clique(i));
end
end
for i=1:length(clique)
newSet(clique(i)) = 0;
end
R和t的计算
为了确定旋转矩阵R和平移矢量t,我们使用Levenberg-Marquardt非线性最小二乘最小化来最小化以下总和:

MATLAB中的“优化工具箱”直接在函数lsqnonlin中实现Levenberg-Marquardt算法,该函数需要提供一个需要最小化的矢量目标函数以及一组可以改变的参数。
这就是在MATLAB中表示要最小化的函数的方式。
function F = minimize(PAR, F1, F2, W1, W2, P1)
r = PAR(1:3);
t = PAR(4:6);
%F1, F2 -> 2d coordinates of features in I1_l, I2_l
%W1, W2 -> 3d coordinates of the features that have been triangulated
%P1, P2 -> Projection matrices for the two cameras
%r, t -> 3x1 vectors, need to be varied for the minimization
F = zeros(2*size(F1,1), 3);
reproj1 = zeros(size(F1,1), 3);
reproj2 = zeros(size(F1,1), 3);
dcm = angle2dcm( r(1), r(2), r(3), 'ZXZ' );
tran = [ horzcat(dcm, t); [0 0 0 1]];
for k = 1:size(F1,1)
f1 = F1(k, :)';
f1(3) = 1;
w2 = W2(k, :)';
w2(4) = 1;
f2 = F2(k, :)';
f2(3) = 1;
w1 = W1(k, :)';
w1(4) = 1;
f1_repr = P1*(tran)*w2;
f1_repr = f1_repr/f1_repr(3);
f2_repr = P1*pinv(tran)*w1;
f2_repr = f2_repr/f2_repr(3);
reproj1(k, :) = (f1 - f1_repr);
reproj2(k, :) = (f2 - f2_repr);
end
F = [reproj1; reproj2];
结果验证
如果满足以下条件,则可以说R和t的特定集合是有效的:
如果集团中的特征数量至少为8。
重投影误差ϵ小于某个阈值。
上述限制有助于处理嘈杂的数据。
一个重要的“ hack”
如果您在现实世界的序列上运行上述算法,将会遇到一个很大的问题。 当诸如卡车或货车的大型车辆占据摄像机视野的大部分时,场景刚度的假设就不再成立。
为了处理此类数据,我们引入了一个简单的技巧:仅当主导运动为正向时才接受tranlsation/rotation矩阵。
This is known to improve results significantly on the KITTI dataset, though you won’t find in this hack explicitly written in most of the papers that are published on the same!
附录
贪心算法
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅仅是在某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关。)
所以,对所采用的贪心策略一定要仔细分析其是否满足无后效性。
二、贪心算法的基本思路
建立数学模型来描述问题
把求解的问题分成若干个子问题
对每个子问题求解,得到子问题的局部最优解
把子问题的解局部最优解合成原来问题的一个解
三、该算法存在的问题
不能保证求得的最后解是最佳的
不能用来求最大值或最小值的问题
只能求满足某些约束条件的可行解的范围
四、贪心算法适用的问题
贪心策略适用的前提是:
局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可以做出判断。
五、贪心选择性质
所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,换句话说,当考虑做何种选择的时候,我们只考虑对当前问题最佳的选择而不考虑子问题的结果。这是贪心算法可行的第一个基本要素。贪心算法以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用贪心算法求解的关键特征。
六、贪心算法的实现框架
从问题的某一初始解出发:
while (朝给定总目标前进一步)
{
利用可行的决策,求出可行解的一个解元素。
}
由所有解元素组合成问题的一个可行解;
