源代码链接:https://github.com/chineseocr/chineseocr
算法相关解读参考:添加链接描述
下载模型文件:
百度云盘链接
git clone 从原github网站上下载所有代码时,darknet目录下的文件不会自动下载到该目录下,需要从darknet网站下载相关文件上传到darknet目录下
由于原github网站上的源代码中的web启动及访问服务的部分实现不了,无法按照源代码访问对应的网站获得OCR识别结果,所以引用了flask接口,修改了相关代码,最后可通过启动app.py后执行post-demo.py的脚本直接获得识别后的结果。
以下是相关代码修改的部分:
post-demo.py:
端口可以自己随便定

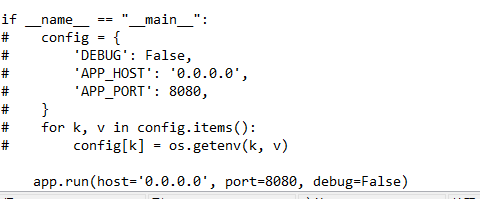
修改app.py相关部分:

构建docker镜像:
dockerfile文件:

构建镜像:
docker build -t chineseocr:v1 .
启动镜像:
docker run -i -t chineseocr:v1 /bin/bash
运行app.py脚本:
docker run --gpus all -v /....../chineseocr:/chineseocr -w/chineseocr chineseocr:v1 python app1.py
查看服务是否启动成功:
docker ps

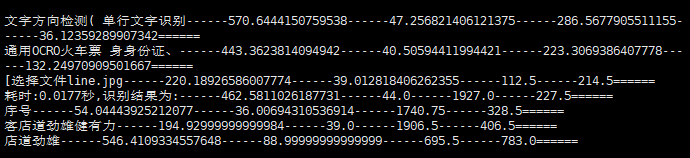
然后运行post-demo.py脚本调用服务,得到OCR识别结果:
cd /.../chineseocr
python post-demo.py
由于环境问题和一些脚本的问题,之后会上传包含相关的所有代码和文件的链接:
添加链接描述
