zookeeper 简单说 就是 一句原语 团结和睦一直对外
通过一个hadoop的namenode的HA例子引入,上小图

zookeeper 1注册 2监听事件 3 回调函数
值得注意的是回调函数是 zkfc自己的,是zkfc当初注册在zk cluster上的
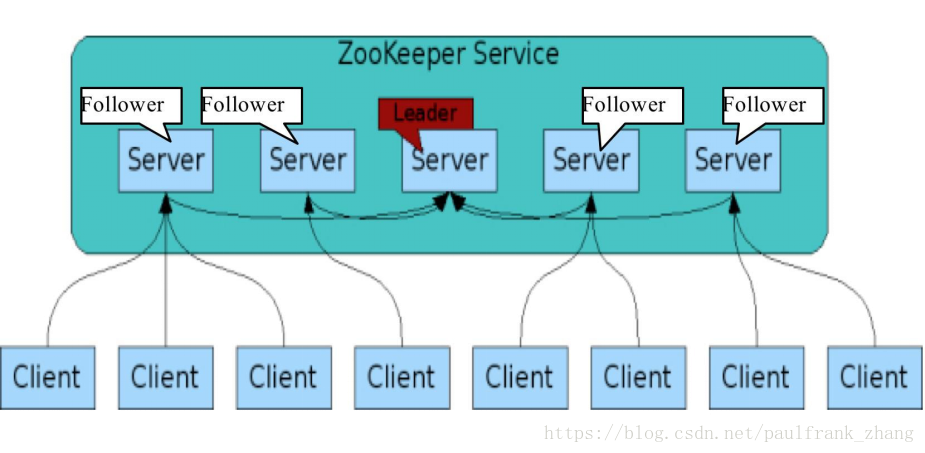
选leader的过程
每个server都会有个 server_id(my_id)和zxid.
事务zxid优先级高于s_id.
传递性
过半机制
角色模型
集群状态
选举模式 安其内
广播模式 壤其外
Server状态
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
主从分工
领导者(leader)
负责进行投票的发起和决议,更新系统状态
学习者(learner)
包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并向客户端返回结果,在选主过程中参与投票
Observer
可以接受客户端连接,将写请求转发给 leader,但observer不参加投票过程,只同步leader 的状态,observer的目的是为了扩展系统,提高读取 速度
客户端(client)
请求发起方

会话session
客户端与集群节点建立TCP连接后获得一个session
如果连接的Server出现问题,在没有超过Timeout时间时,可以连接其他节点
同一session期内的特性不变
Session是由谁来创建的?
Leader:产生一个唯一的session,放到消息队列,让所有server知道
(过半)