Kafka简介及安装配置
一、简介
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,使用Scala语言编写,之后成为Apache项目的一部分,目前是Apache的一个顶级项目。
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。
它提供了类似于JMS(Java消息队列规范)的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群由多个kafka实例组成,每个实例(server)称为broker。
无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
总结:
Kafka是分布式消息队列,按topic分类存放数据,拥有Producer、Consumer、Broker三个角色,使用zookeeper做为集群的协调工具。
1、kafka的特点
1.高吞吐量
理论上Kafka每秒可以生产约25万消息(50MB),每秒处理55万消息(110MB),生产环境中在这个速度上下浮动,这个速度就相当于硬盘IO的速度。
2.持久化数据存储
可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
3.分布式系统易于扩展
所有的producer、broker和consumer都可以有多个,均为分布式的。无需停机即可扩展机器。
4.客户端维护状态
消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
二、基本概念
Kafka将消息以topic为单位进行归纳。topic之间的数据是相互隔离的。
将向Kafka topic发布消息的程序称为producers。
将预订topics并消费消息的程序称为consumer。
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息。
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
1、Topic
一个topic是对一组消息的归纳。
1.分区
Kafka针对对每个topic的日志进行了分区。
kafka中的分区是负载均衡和失败恢复的基本单位。
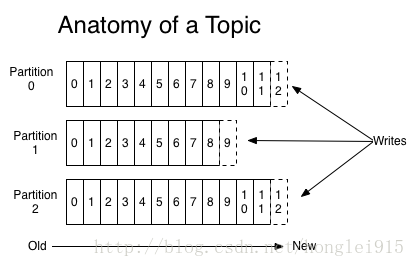
2.offset
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一标识一个消息。在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。
比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。过期之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
3.分区副本
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去同步leader的数据,并对外提供读操作。如果leader down了,followers中的一台则会自动成为leader。
集群中的每个服务器都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就据有较好的负载均衡。
将日志分区可以达到以下目的:
首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分区是负载均衡失败恢复分布式数据存储的基本单元。
2、Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
3、Consumers
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset。这个offset由consumer来维护,一般情况下随着consumer不断的读取消息,这offset的值会不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级,它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
消费消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。
1.队列模式
队列模式中,多个consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到。
通俗的来讲,consumers之间是竞争关系,都在从borker中抢数据,而这个数据只有一份,谁抢到就是谁的。
2.发布订阅模式
发布-订阅模式中消息被广播到所有的consumer中。这种模式之下,每个consumers都能得到相同的消息数据。
3.consumer group
Consumers可以加入一个consumer group,此组就是用来实现以上两种模式的。
1>组内
如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。
组内的Consumer是处在队列模式下,共同竞争一个topic内的消息,topic中的消息将被分发到组中的一个成员中,同一条消息只发往其中的一个消费者。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。
2>组间
如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。
而如果有多个Consumer group来消费相同的Topic中的消息,则组和组之间使用的就是发布订阅模式,是一个共享数据的状态。每一个组都可以获取到这个主题中的所有消息。
3>应用
常见的应用方式是,每个topic都有若干数量的consumer组来消费,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组都由若干consumer组成,在组内竞争实现负载均衡。实现了组内竞争负载均衡,组间共享互不影响,这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
4、与传统消息队列对比
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
5、选择Kafka的理由
为什么大数据环境下的消息队列常选择kafka?
分布式存储数据,提供了更好的性能、可靠性、可扩展能力。
利用磁盘存储数据,且按照主题、分区来分布式存放数据,持久化存储,提供海量数据存储能力。
采用磁盘存储数据,连续进行读写保证性能,性能和磁盘的性能相关和数据量的大小无关。
三、安装配置
1、下载安装
下载Kafka安装包,上传到Linux服务器。
解压:
tar -zxvf kafka_2.9.2-0.8.1.1.tgz解压完成就相当于安装完毕,不过还要进行响应的配置。
2、配置
1.伪分布式
1>server.properties
修改server.properties文件。
log.dirs=/tmp/kafka-logs此选项配置的是Kafka的数据存储位置,需要更改。
2>zookeeper.properties
修改zookeeper.properties配置文件。此文件是Kafka内置的Zookeeper的配置文件。Kafka为了保证软件的独立性,自己内置了一个Zookeeper,所以使用为分布式的情况下,不用专门安装Zookeeper。
如下项配置的是zookeeper的数据存储位置,默认在/tmp中,需要修改。
dataDir=/tmp/zookeeper3>启动kafka
启动zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties &启动kafka:
bin/kafka-server-start.sh config/server.properties2.完全分布式
1>server.properties
在config目录下,修改server.properties,在文件中修改如下参数:
broker.id=0 #当前server编号
port=9092 #使用的端口
log.dirs=/tmp/kafka-logs-1 #日志存储目录
zookeeper.connect=yun01:2181集群中broker.id要具有唯一性。
日志存放目录需要更改为规划目录,不能使用默认的/tmp目录。
Zookeeper需要配置Zookeeper集群中所有服务器的ip或主机名:端口。
2>启动
①启动zookeeper
在各个机器上执行如下启动命令:
zkServer.sh start②启动kafka
bin/kafka-server-start.sh ../config/server.properties &Kafka服务默认启动会占用控制台,所以可以后台运行。
3、测试
1.创建topic
创建一个拥有3个副本的topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic topicname2.查看
1>查看主题
bin/kafka-topics.sh --list --zookeeper localhost:21812>查看节点
查看每个节点的信息:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topicname3.生产消息
向topic发送消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topicname4.消费消息
消费消息:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic topicname5.实验:容错性
制造宕机,查看Kafka的容错性。
kill -9 7564
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topicname
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic topicname启动kafka:
启动zookeeper:
zkServer.sh start启动kafka:
bin/kafka-server-start.sh config/server.properties四、使用kafka
1、sell操作
1.创建topic
bin/kafka-topics.sh --create --zookeeper localhost:9092 --replication-factor 1 --partitions 1 --topic test2.查看topic
bin/kafka-topics.sh --list --zookeeper localhost:21813.生产消息
使用命令行producer从文件中或者从标准输入中读取消息并发送到服务端:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test4.消费消息
启动命令行consumer读取消息并输出到标准输出:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning2、JavaAPI操作
1.搭建开发环境
创建java工程,导入kafka相关包,jar包存在于Kafka安装包的libs目录中,拷贝时注意,里面不只有jar包,还含有其他类型的文件,只拷贝jar包即可。
2.代码实现
1>消费者
/**
接收数据
*/
@Test
public void ConsumerReceive() throws Exception{
Properties properties = new Properties();
properties.put("zookeeper.connect", "yun01:2181,yun02:2181,yun03:2181");//声明zk
// 必须要使用别的组名称, 如果生产者和消费者都在同一组,则不能访问同一组内的topic数据
properties.put("group.id", "group2xx");
properties.put("auto.offset.reset", "smallest");
// properties.put("zookeeper.session.timeout.ms", "400");
// properties.put("zookeeper.sync.time.ms", "200");
// properties.put("auto.commit.interval.ms", "1000");
// properties.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put("my-replicated-topic", 1); // 一次从主题中获取一个数据
Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumer.createMessageStreams(topicCountMap);
// 获取每次接收到的这个数据
KafkaStream<byte[], byte[]> stream = messageStreams.get("my-replicated-topic").get(0);
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while(iterator.hasNext()){
System.out.println("receive:" + new String(iterator.next().message()));
}
}2>生产者
/**
发送数据
*/
@Test
public void ProducerSend(){
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "192.168.242.101:9092");
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props ));
producer.send(new KeyedMessage<Integer, String>("my-replicated-topic","message~xxx123asdf"));
producer.close();
}