1.分析程序
1.1 作业一
1.1.1 类图

第一次作业中OO的思想几乎没有体现,直接在主类中构建了几个方法分别进行读入、求导、输出,没有构建其他的类,这就导致程序几乎没有可扩展性。因为表达式类型简单,只采用了HashMap来存储每一项。规模最大的方法为write_out为59行。
1.1.2 复杂度分析

write_out和build两个方法的复杂度较高,因为按项读入、输出的时候需要对循环每一项,进行多种类型的判断。
1.1.3 关于bug
在化简时由于在Iterator循环的过程中对成员进行删除导致了bug,主要原因是对Iterator的实现原理不理解。互测阶段出现的bug是因为连续多个+-符号出现时没有考虑-对应-1,导致添加的项正负号相反。出现bug的原因是情况考虑不全面,自己测试的覆盖也不够广。
互测没能发现别人程序的bug,测试方向主要为+1,-1省略形式。在阅读别人代码的时候看见设置的捕获异常,读取数据的方法和自己只用正则不同,采取了正则表达式和for逐个字符处理相结合。
1.2 作业二
1.2.1 类图
作业二在作业一的基础上新建了两个类Term和Build,Term用来存储项,Build用来构建项和表达式,表达式仍然使用HashMap表示,但其中的成员为自定义的项类。主类中设置了求导、输出的方法。作业二相当于在作业一的基础上把项单独作为一个类抽离出来,Build有一点工厂模式的想法。但是由于第二次作业仍然比较简单,我采用的项构造和求导方法和作业一类似,找到一般表达式分类处理,这就导致作业三在作业二的基础上无法扩展。作业二在处理+-方面采用把多个连接的符号化简为一个,解决作业一出现的bug。
1.2.2 复杂度分析
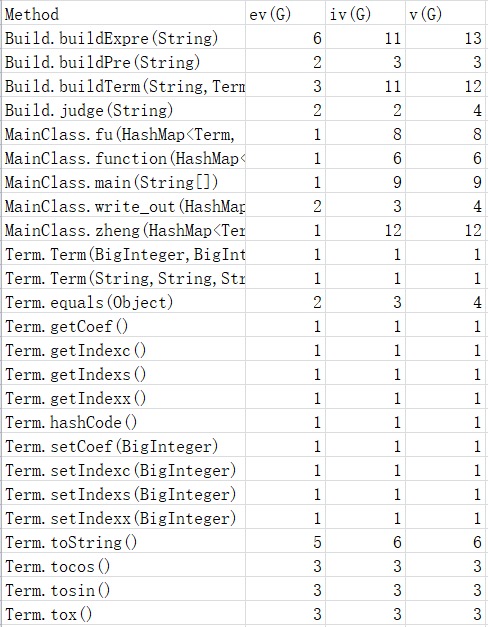

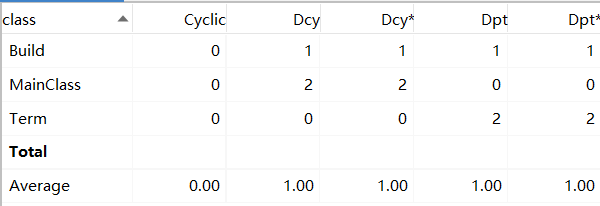
复杂度高的部分仍然集中在表达式的输出和构建,作业二的输出在作业一的基础上加入了三角函数的一般输出和特殊情况输出,判断的情况数增加。表达式的构建在作业一的基础上加了一步对*的拆分,使复杂度增加。
1.2.3 关于bug
强测出现bug,对每项求导后HashMap直接把重复的项覆盖而不是合并。设计时的考虑是在读入每项时进行合并,项不同求出的导数不同,但不同项的导数时可能相同的。
互测阶段采取测试边界值,比如指数的限制;对指导书的理解,输入指数的限制而不是对最终指数的限制;第一次自己犯的错误,比如+++1连在一起。最终找出3个bug。
1.3 作业三
1.3.1 类图

作业三的思路与作业二完全不同。作业三将求导法则和幂、三角函数各自建类,实现求导接口。整体思路是判断格式,构建表达式树,一级一级向下调用求导函数。
1.3.2 复杂度分析
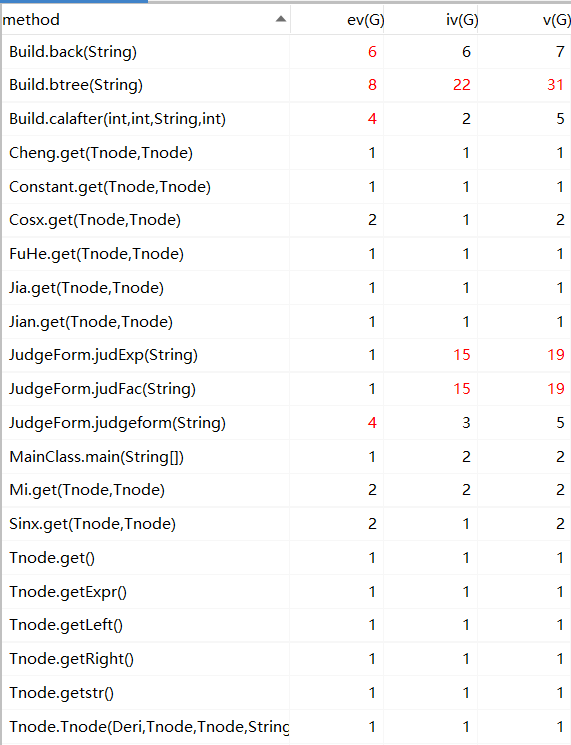

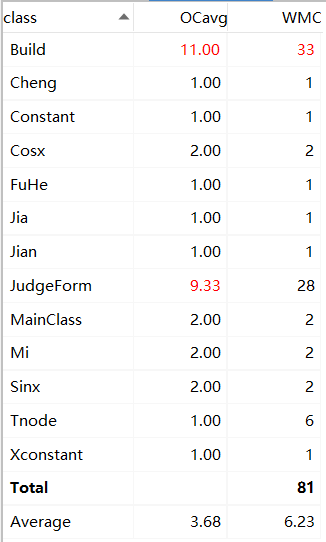
复杂度主要集中在构建树和判断格式。构建树和判断格式应用了递归的思想,导致复杂度增加。在构建树的部分采用最字符逐个分析的方法,在判断格式部分采用了正则表达式。


求导接口、树结点依赖的类很多。
1.3.3 关于bug
这次出现bug是三角函数内部的因子没有加括号。其次没注意到输出表达式的格式仍然要满足指导书中的格式要求,比如(x)**2是非法的。
互测阶段因为没有注意参考书互测数据的限制没能发现别人的bug。
2.应用对象创建模式
第一次作业格式简单,直接读入,加入到HashMap中。第二次作业有一点工厂模式的想法,在Build里面构建项和表达式。其实如果第一次作业就采用了工厂模式,第二次作业只需要加入三角函数的项,会方便的多,对代码结构的影响也不会太大。但是第三次作业加入了嵌套结构后,如果再分析每一项就会显得很冗杂,也不好管理。于是第三次作业没有再采用输入字符串返回项的方法,而是对整个字符串从内到外分析。对各种情况的分析应该仍能抽象出一个工厂,例如将判断+-*^等的if单独放入一个工厂类,但从外到内的分析涉及的参数太多。
3.对比和心得体会
很多同学加入了额外的功能比如异常捕获,这就使程序更加完善、可靠性更强,而且debug也更加方便。从第一次作业开始就要预测以后可能会添加的功能,在设计时多加考虑,增加程序的可扩展性,这样就能使以后的作业轻松很多。写代码的过程中要加入注释,这样能帮助自己理清思路,把各个模块的功能更合理清晰的安排。讨论区的内容在完成作业的过程中给我很大的帮助。要仔细阅读指导书,注意指导书的提示,这往往是某个测试点的细节。