出处 :IEEE on Transactions on Information Forensics and Security 2018
摘要 :Keypoint-based detection methods 用在复制粘贴篡改检测,对于 large-scale geometric transformations 鲁棒性好。但当篡改区域是 small or smooth regions 时,keypoint 的数量很有限。
本文提出基于 hierarchical feature point matching 分层特征点匹配的复制粘贴篡改检测算法。
- 通过降低对比度阈值和缩放输入图像,可以在 small or smooth region 产生大量关键点
- 提出新颖的分层匹配策略来解决关键点匹配问题
- 进一步提出了一种新的迭代定位技术 iterative localization technique,利用鲁棒特性 ( 包括主导方向 dominant orientation 和尺度信息 scale information ) 和每个关键点的颜色信息来精确定位篡改区域。
(code)[https://github.com/YuanmanLi/FE-CMFD-HFPM.]
数据集 FAU [6], GRIP [12], MICC-F220[3], MICC-F600 [16], CMH [15] and COVERAGE [34]
实验环境 desktop equipped with Core-i7 and 8-GB RAM, operating in single-thread modality.
metrics TPR、 FPR、 F-score, 从图像、像素角度评估。computational complexity
相关工作
近年的复制粘贴检测可大致分两组
dense-field(或基于块)的方法,输入图像分为 overlapped and regular blocks ,然后通过block matching 来定位。
为增强对于几何变换的鲁棒性,有 Discrete Cosine Transform (DCT) 离散余弦变换,Discrete Wavelet Transform (DWT) 小波变换,Principal Component Analysis (PCA) 主成分分析,Singular Value Decomposition (SVD)奇异值分解的方法,基于块的方法比基于关键点的方法更准确,但复杂度更高。
但是,目前的 dense-field 的方法在缩放、旋转、添加噪声的情况下都不好
sparse-field(或基于关键点)的方法
SIFT算法 :是一种基于尺度空间的、对图像缩放、旋转甚至仿射变换鲁棒性好的图像局部特征
SIFT 实现步骤: 1. 提取关键点 2. 关键点描述3. 关键点匹配 4. 消除错配点
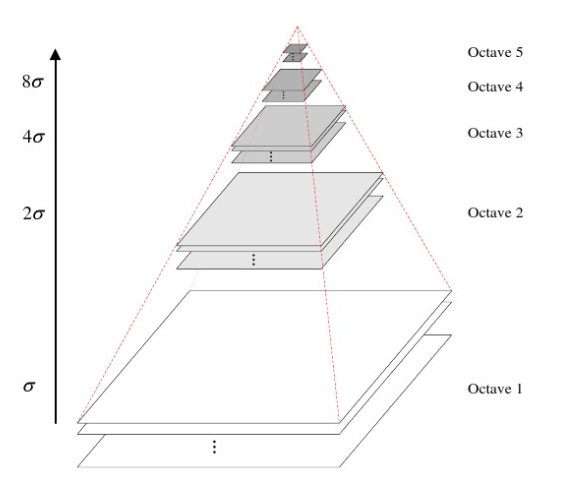
要找到的关键点是很稳定的,比如角点、边缘点、暗区域的亮点以及亮区域的暗点,具有三个特征:尺度 方向 大小关键点检测:图像与高斯核卷积,产生多尺度空间
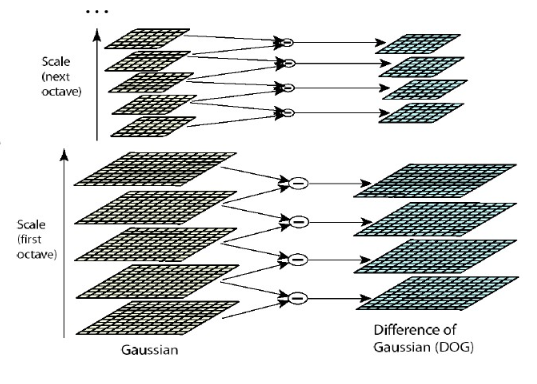
构造DoG函数,简化计算
寻找 DOG 的局部极值点
-->关键点精确定位:上述找到的极值点要进一步检验,舍去一些点,包括去除对比度值低的点
-->关键点方向分配
-->关键点描述
-->关键点匹配
-->消除错配点
本文的算法结构 特征提取-->匹配-->篡改定位
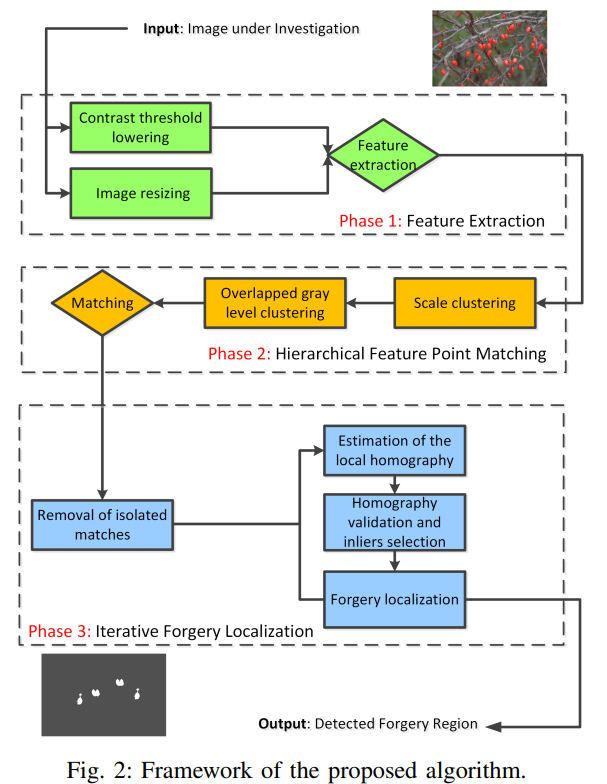
Ⅲ 特征提取
采用 SIFT 算法提取特征,但是,SIFT 在小的和光滑的区域产生不了很多关键点,这会削弱检测表现。所以作者提出两个策略改进SIFT,从而能在小的和光滑的区域产生大量关键点
降低对比度阈值
SIFT算法中,通过 i)差分高斯金字塔检测到极值点后,要 ii)关键点的定位和过滤,即利用已知的离散极值点对尺度空间DoG函数进行曲线插值得到连续空间的极值点
对于一点,对比度值为
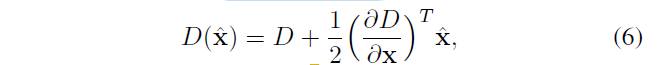
D是高斯差分函数,x^是相对插值中心的偏移量
然后要删除对比度小于阈值c的极值点 ,通常c=4。但小的光滑的区域的极值点对比度低于阈值,会被删去 ,如图4 (b),产生的关键点数量少,就不能为篡改检测提供充足的证据
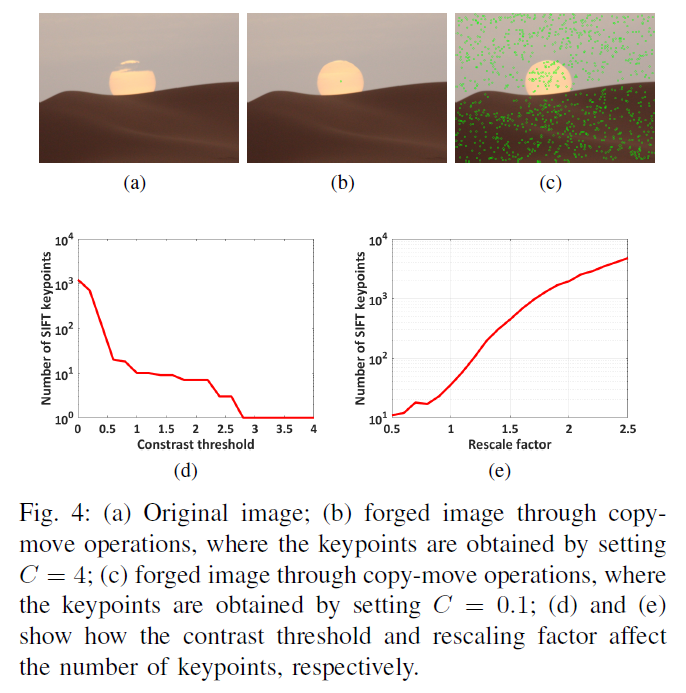
因此,为保证在小的光滑的区域产生大量关键点,应该要降低阈值 c ,但是 c 又不能太低,太低的话会产生很多不稳定的关键点,引发关键点匹配问题。
因此,做实验来选择合适的 c 点。选取100 幅有光滑区域的图像(包含月亮,沙漠,天空等),先把每个图像划分成大小相同重叠的块,再选取具有最小方差的块作为这个尺寸的 patch,共有100×100 到 500×500 5个尺寸,最终得到500个 patches
根据公式 7 得到合适的 c 值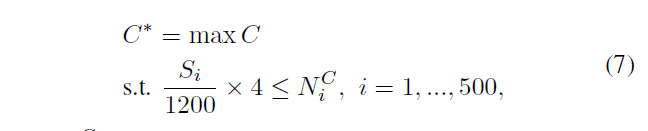
C 是对比度阈值,从 4 调到 0,step=0.01,约束条件是\(N^{c}_{i}\) ,i-th patch 的关键点数目至少保证在\(S^{i}\)大小的 patch 上每 1200 像素有 4 个关键点。图4 d 是 c 值和关键点数量的关系,c=0.01时是最优解,只比c=0.1好一点,考虑到错误匹配,设置c=0.1。图4c 是 c=0.1 的结果
缩放输入图像
缩放输入图像能大大提升关键点的数量,如图4e,虽然s越大,关键点越多,但s太大的时候,造成关键点紧密聚集,会恶化关键点匹配问题,因此折衷选择 s=2
以上两个方法可以大量增加关键点数量,但是会造成关键点匹配困难和错误匹配的问题,所以下文提出匹配策略和定位技术改善以上问题
Ⅳ 分层特征匹配
A关键点匹配问题
如图 5a 是篡改图像
5b :5个直接匹配,2990个关键点,c=4,s=1
5c :1个直接匹配,35601个关键点,c=0.1,s=2
5d :54个scale clustering匹配,35601个关键点,c=0.1,s=2

使用上述方法后,关键点数量翻了10倍多,匹配数却从5降到1,这是因为相邻位置或者不同尺度的同一位置生成更多的关键点,相应的 descriptors 非常相似,违背了公式5的匹配条件,称为 keypoint matching problem-I
关键点匹配 对于篡改图像建立关键点描述子集合,通过任意两关键点描述子的相似性度量完成匹配,使用欧式距离
两点之间,直线最短。欧式距离描述两点间的直线距离
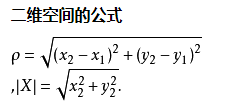
公式5 中,要配对的关键点(\(R_{i},\)\(R_{i}\))要满足
\[ \frac{R_{i}最近的点R_{j}的距离}{R_{i}次近的点S_{j}的距离}<threshold \]
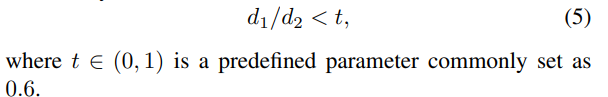
匹配算法的计算复杂度大大增加,称为 keypoint matching problem-II
为解决上述2个问题,提出分层特征点匹配算法,算法结构如图6,
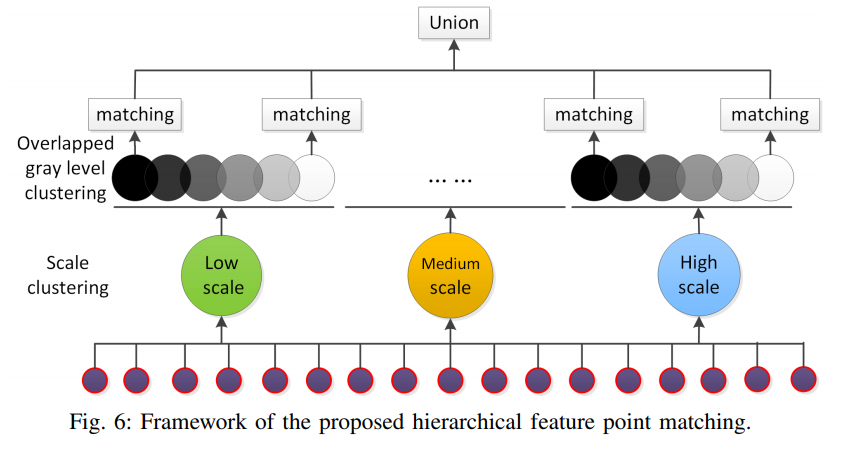
包括两部分,1)通过尺度聚类进行组匹配 2)通过重叠灰度等级聚类进行组匹配
B通过尺度聚类进行组匹配
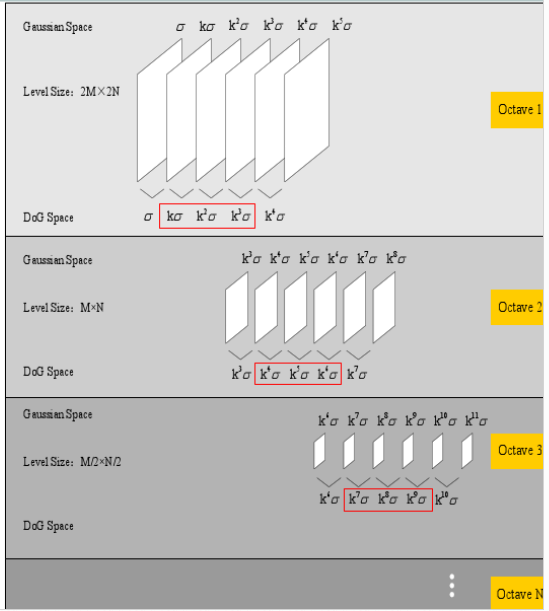
如图3,SIFT算法中,高斯图像以 octave 为组,在尺度空间检测关键点。使用了Ⅲ的方法后,不同尺度的关键点紧密聚集, 由于1. 高尺度的octaves的关键点数量相对低尺度的少 2. 高尺度联合匹配关键点对于大规模缩放鲁棒性好,因此本文的解决办法是每一个较低尺度的单个 octave 内分别进行匹配,而在多个较高尺度的 octave 内共同进行匹配。
根据公式 8,把关键点分为 3 组 ,octave1,octave2,octave3 以上是一组
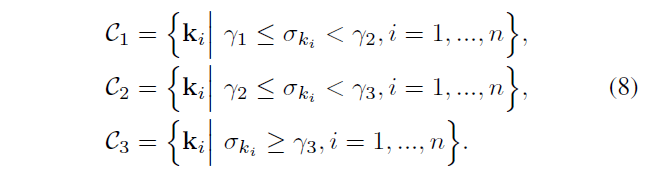
\(\gamma_{i}\) 是第 i 个octave中第一个 DoG 图像的尺度值。 \(\sigma_{k}\)是关键点k的尺度值,越大图像越平滑
因此,减轻了 keypoint matching problem-I 问题,如图5d。
注意 上述可增加匹配对的数量,但一定程度上牺牲了对于图片缩放的鲁棒性。考虑到C3包含high-scale的所有关键点,一定程度上保留了对于图片缩放的鲁棒性。C1 C2的匹配对于小规模缩放具有鲁棒性
C Group matching via overlapped gray level clustering
通过重叠灰度等级聚类进行分组匹配
根据SIFT公式5,需要在同组内所有关键点进行距离计算,从而匹配。但随着关键点数量增加,计算负担加重。因此,在本文的结构中,一个有效的匹配算法很重要,提出一个匹配策略——重叠灰度等级聚类进行匹配
在复制粘贴检测中,一个先验知识是,正确匹配的对应该在两个相似的局部区域中也就是有相似的像素值。所以,提出先根据关键点的灰度值分类,再在每一类灰度值里应用公式 5 进行匹配。
只把所有关键点分离成几个灰度值类,可能会造成丢失在不同灰度值类之间正确匹配的对,因此,把 0-255 划分成 L 个重叠的子集,step = c1,overlapped step = c2,如公式9
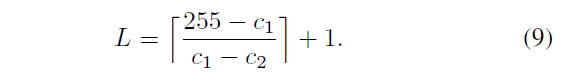

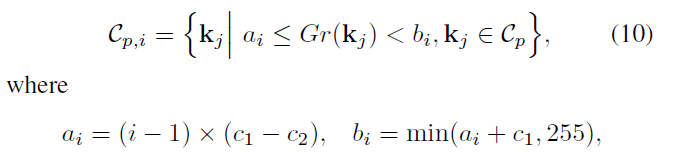
\(C_{p,i}\)表示一个 scale clustering 中的第 i 个 overlpped gray level clustering 里的关键点,\(a_{i}\)\(b_{j}\)代表这组灰度值的开始点和结束点
P表示一副图像的所有匹配对,\(P_{p,i}\)表示一个一个 scale clustering 中的第 i 个 overlpped gray level clustering 里的匹配对,有公式11
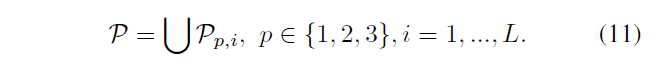
为消除匹配错误,使用
Ⅴ iterative forgery location
迭代篡改定位
基于关键点的复制粘贴检测算法,在定位时存在问题
存在多个篡改区域时,homograohy 不唯一,且篡改区域数量未知
所有匹配的对没有匹配顺序,因此篡改点和对应的原始点在匹配过程中没有分离
RANSAC算法是对单个homography进行估计的,且匹配对应当有匹配顺序。
以前的解决办法:
1)基于关键字聚类的算法如[3]、[15],提出先将匹配的关键字按位置聚类,将伪造的关键字与对应的原始关键字分离成不同的聚类;然后,连接两个集群的匹配被分配一个一致的匹配顺序(从一个集群到另一个集群)[3];
2)基于关键点分割的算法如[5],首先将整幅图像分割成小的非重叠区域,然后在每个分割区域之间进行匹配。如果区域包含足够数量的匹配点,则区域被视为复制-移动的对应。
存在的问题
1)多个篡改区域,真实的聚类未知,或者篡改定位区域挨的很近,容易把篡改区域和真实区域划分为一个聚类
2)大尺寸图像分割计算量大,很难找到普遍适用的算法参数
我们的办法
1)不需要任何聚类或者分割过程
2)充分利用关键点的鲁棒性特征(主方向和尺度信息)和颜色信息
3)篡改定位非常准确
具体步骤
Step 1): 删除孤立的匹配对;
Step 2): 局部单应性估计;
Step 3): 利用主导方向进行单应性验证和inliers选择;
Step 4): 使用比例和颜色信息进行篡改定位。
A Removal of isolated matched pairs
复制粘贴检测的先验知识:篡改在连续的形状里进行 ,所以正确匹配的关键点不应该孤立在局部区域中。根据公式12,抛弃孤立的匹配对

\(N_{K}\),\(N_{k'}\)指距离匹配对(k,k')的距离<\(T_{iso}=100\)的匹配对数量
剩下有效匹配对的集合,定义为 M
B Estimation of the local homography
从 M 中随机挑选(k,k'),如公式14,\(C_{K}\),\(C_{k'}\)表示 \(M_{keys}\) 的关键点里距离 k 和 k‘ 近的关键点
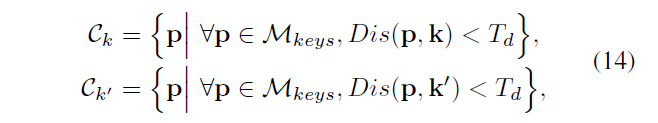
\(M_{keys}\)指 M 中的关键点, \(T_{d}\)=100,DIS(p,k) 计算两个关键点的欧式距离
产生\(M_{k}\) 包含距离(k,k')近的所有关键点对,(匹配顺序是从\(C_{K}\) 到 \(C_{k'}\))
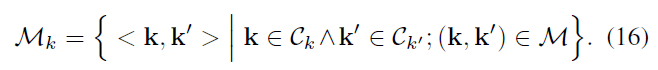
(https://blog.csdn.net/xuyangcao123/article/details/70916767)

\(M_{k}\) 中的对来自两个局部连续区域,假设他们的 homograhy \(H_k{}\)相同,因此解决了 Ⅴ 开头提到的问题。
[16]建议估计一组仿射矩阵,每个仿射矩阵也由一部分匹配的对(三个随机选择的邻近的对)计算。他们的目标是在一个概念空间中聚集匹配的对。
而我们使用来自两个相邻局部区域的所有匹配对估计仿射矩阵,再使用所有的 inliers 进行 refine
C Homography validation and inliers selection using the dominant orientation
单应性验证和利用主方向选择 inliers
RANSAC方法不是完全准确,尤其当 inliers 数量不够多时。我们提出了一种新颖的单应性验证和输入点选择方法,利用与每个关键点相关的主导方向。
在SIFT 算法中,dominant orientation 在旋转不变性中发挥重要作用。
<k,k'> 是正确的匹配对,关键点的主方向的 offset \(\theta_{k'}-\theta_{k}\)应该 be compatible with 估计的affine homography \(H_k{}\)。 尽管一些错误的匹配对可能obey the same homography transformation,但是他们的主方向不会 be compatible with \(H_k{}\)
\(H_k{}\) 写作
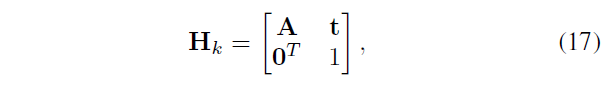
A 是2×2 的非奇异矩阵,\(t=[t_{x},t_{y}]^{T}\) 是 transition vector 过渡矩阵
奇异值分解公式
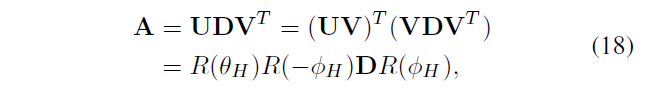
\(R(\theta_{h})\),\(R(\phi_{h})\) 代表旋转操作,参数是\(\theta_{h}\),\(\phi_{h}\)
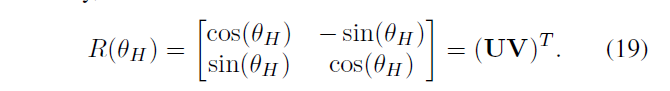
复制粘贴 patch 可能会顺时针或逆时针旋转,所以把 \(\theta_{h}\) 映射到 (0,\(2\pi\)] 空间
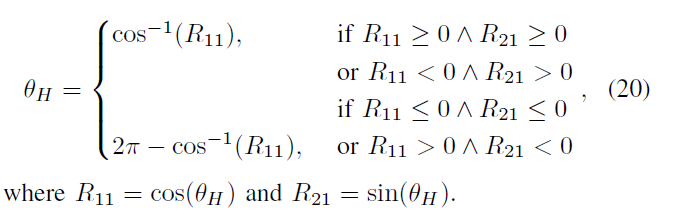
定义函数,来验证 \(H_k{}\) 是否正确
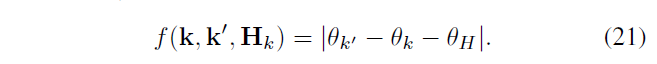
对于估计正确的 \(H_k\) 和匹配正确的对 <k,k'> ,f 应接近于 0 .
\(\hat{M_{k}}\) 表示对\(H_k\) 做RANSAC 算法结果后返回的 inliers 集合,知 \(\hat{M_{k}} \subseteq {M_{k}}\) ,为消除错误的 inliers,当且仅当 \(\hat{M_{k}}\) 中 90% 以上的对满足公式 22 时,接受\(H_k\) (\(T_\theta=15\))
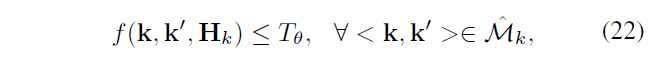
有了 \(H_k\) 以后, 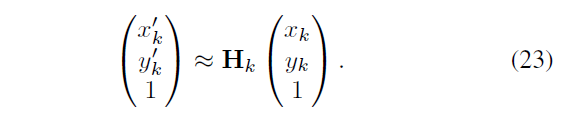
用\(M_H\) 表示选择的 liners ,k 表示一个关键点
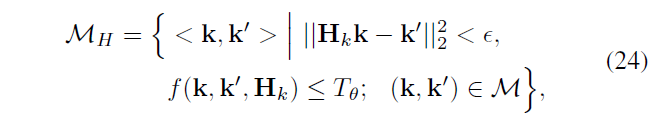
再用得到的 linera refine \(H_k\)
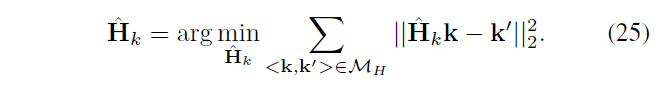
D Forgery localization in dense fields
提出在密集域定位篡改的算法
- 根据每个输入点的尺度信息构造可疑区域
- 通过验证颜色信息的一致性来细化可疑区域
为 \(M_H\) 的每个 inlier 点 k 构造一个局部的圆形可疑区域
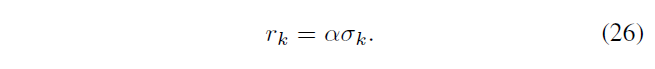
\(\sigma_k\) 是 k 的尺度值,\(\alpha=16\) 是一个超参数
\(M_H\) 的每个点有匹配顺序,所以得到两个可疑区域 S S'
利用颜色信息优化可疑区域
S 中的 k 经过单应性矩阵转化为 k*
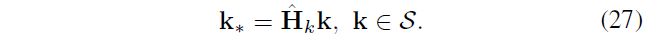
当 k 和 k* 的 R G B 信息相似时,把 k 和 k* 看作是一对复制粘贴点
Q1 表示基于 S 计算得到的所有复制粘贴点,
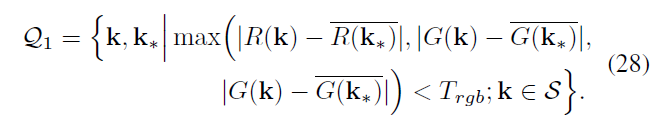
其中 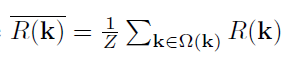
\(\Omega(k)\) 是k的3×3 领域,Z 是归一化因子,阈值 \(T_rgb=10\)
S’ 中的 k‘ 以相反的方式转化
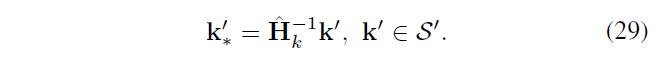
Q2 表示基于 S’ 计算得到的所有复制粘贴点,
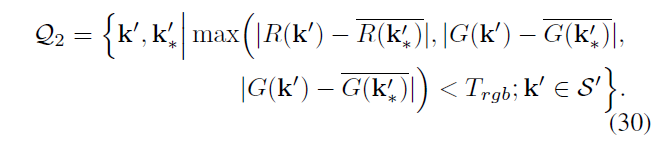
B代表篡改定位二值图,1 表示篡改区域,0 表示原图 ,首先B 初始化为 0 ,再把Q1 Q2标记的点记为1
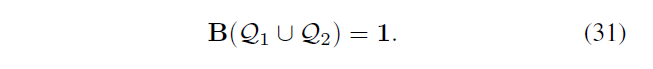
注意,通过上面的step 2)-4),我们最多可以得到满足一个单应性变换的复制-移动区域。然而,当进行多个克隆时,单应性可能不是唯一的。我们的定位算法是迭代的,如图2所示。
具体来说,在我们的方法中,step 2)-4)将重复 K 次迭代(在我们的实验中K = 15)。在每个迭代中,我们只使用匹配对的一部分来估计一个单应性矩阵
在完成所有的迭代后,在B上:删除小区域,通过形态闭合操作填补小间隙,
最终生成被检测到的伪造区域
Ⅵ 实验
数据集:
- FAU:包含48张原始图像和48张对应的具有真实复制-移动操作的篡改图像,平均分辨率约为3000×2300
- GRIP:包含80个原始图像和80个逼真的复制移动篡改,大小相同都是 768×1024。值得注意的是,GRIP中的一些篡改补丁非常光滑,这对基于稀疏采样 (如 SIFT ) 的复制-移动篡改检测是一个挑战
- MICC-F220:由110幅篡改过的图像和110幅未篡改过的图像组成,分辨率从722×480到800×600不等
- MICC-F600:由160幅篡改图像和440幅原始图像组成,图像分辨率从800×533到3888×2592不等
- CMH:包括108个真实的克隆图像,分辨率从845×634到1296×972不等
- (COVERAGE)[https://github.com/wenbihan/coverage]:该数据集有100个原始-篡改的图像对,平均分辨率为400×486。每张图片都包含相似但真实的物体。在我们的实验中,我们使用了由91个原始-篡改的图像对组成的子集,排除 9 个发布的ground truth不正确的图像对。
检测结果
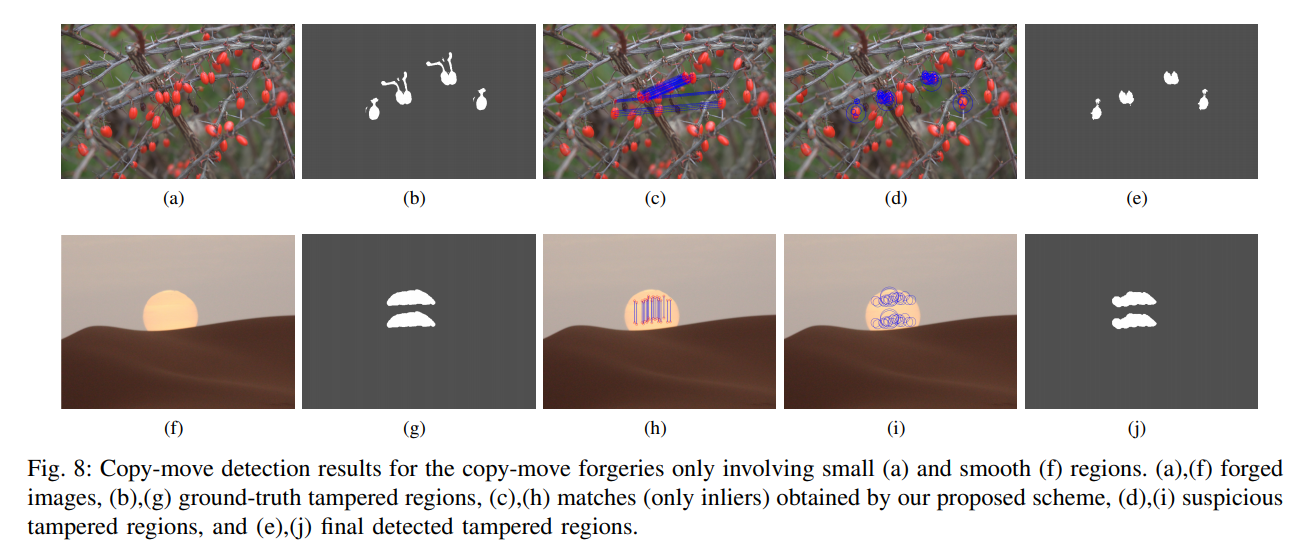
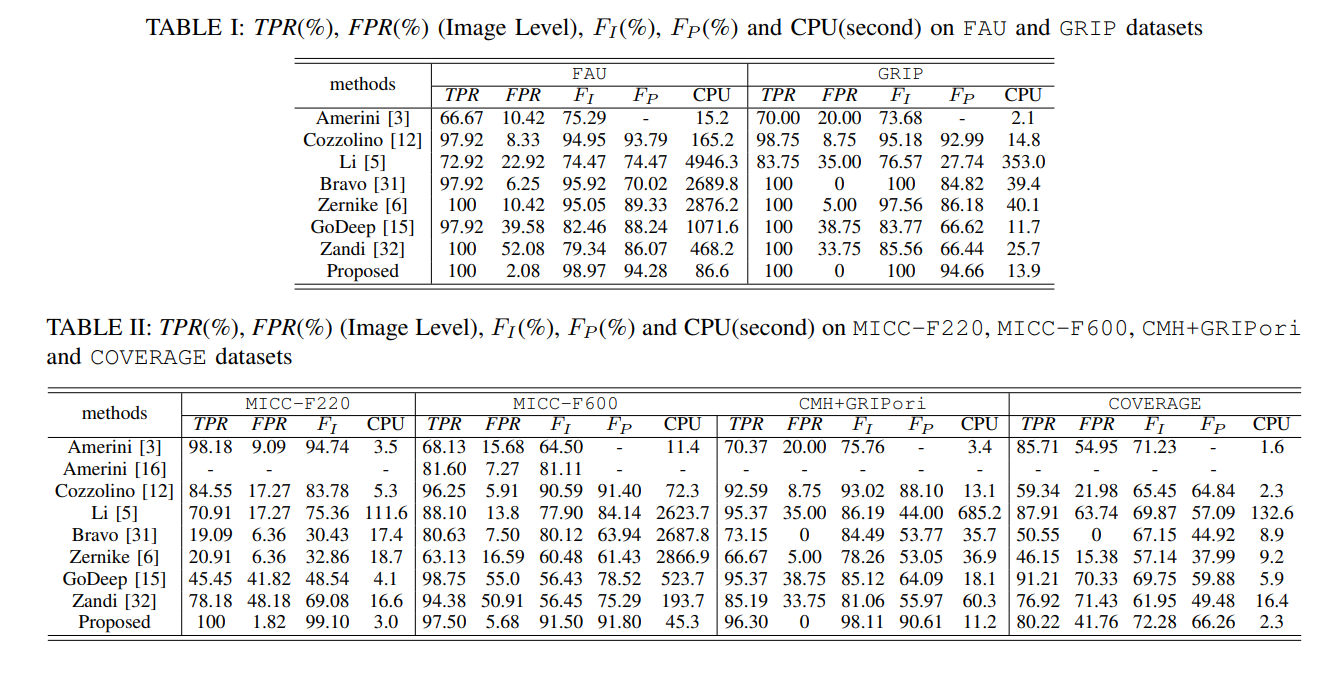
图8 ,表1 2 ,是在 FAU GRIP 上的结果
鲁棒性检测
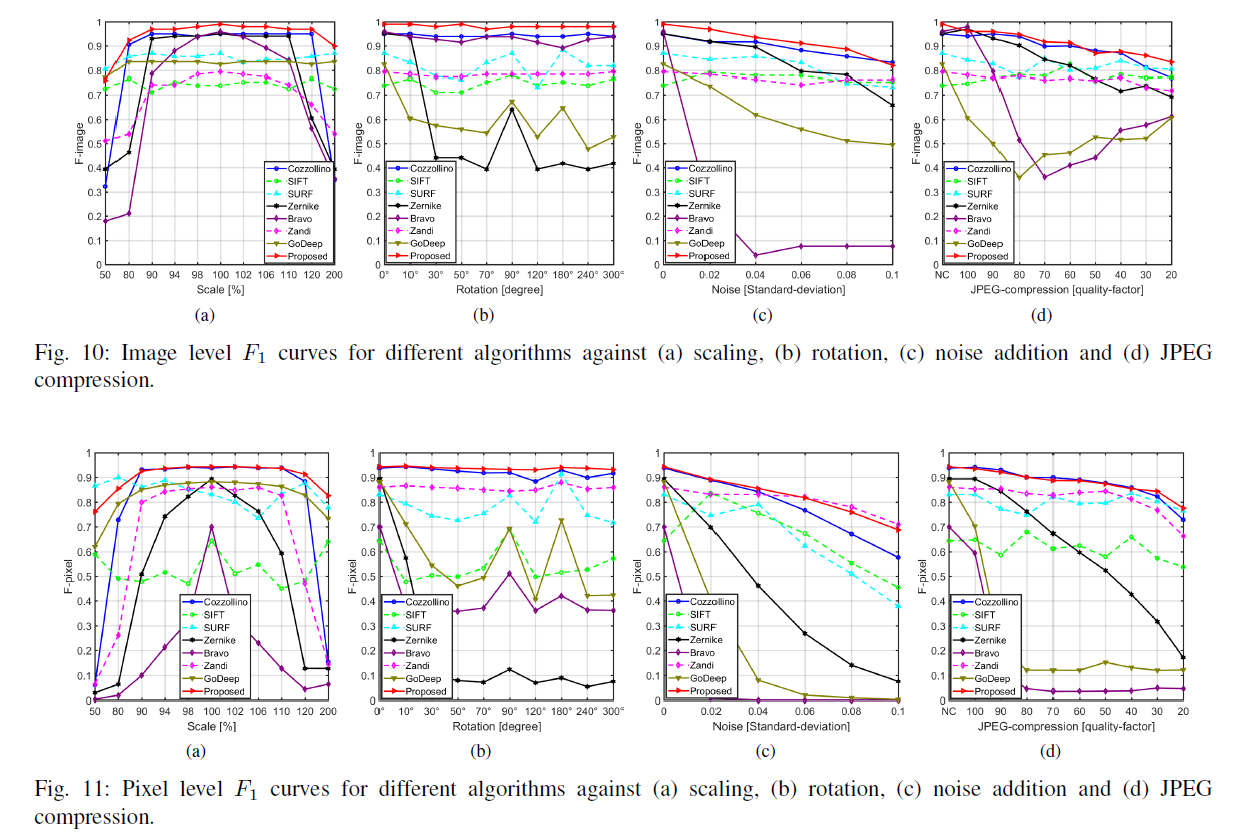
表3 是算法的不同阶段对于表现的影响 ,在FAU数据集上
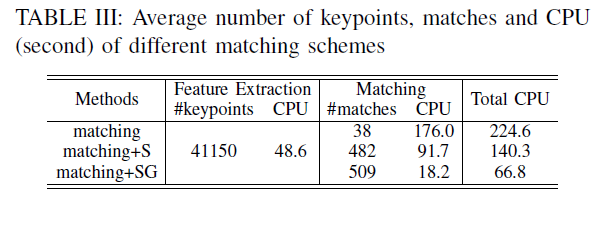
matching 表示传统匹配方法
matching+S 表示仅对 scale 聚类进行组匹配
matching+SG 表示本文提出的分层匹配方法(包括尺度聚类和重叠灰度值聚类)
参考
https://wenku.baidu.com/view/87270d2c2af90242a895e52e.html?re=view