Este artigo pretende usar o conjunto de dados de melancia caseiro para treinamento de modelo de aprendizado profundo,
analisando o áudio da mão batendo na melancia, realizando a transformada rápida de Fourier para extrair características do domínio da frequência, usando um modelo de rede neural convolucional unidimensional para modelo treinamento e construção de modelo de detecção de maturação de melancia.
Índice
1. Pré-processamento de conjunto de dados
1. Coleta de dados
O conjunto de dados de áudio utilizado para o treinamento do modelo foi adquirido e gravado por mim.Na
coleta de áudio, os métodos de bater na melancia são divididos em três categorias: batida (P), brincadeira (T) e batida (Q).
Informações sobre Melancia:
Há um total de 939 peças de áudio de Melancia coletadas.
O conjunto de dados contém um total de 158 amostras de melancia, e cada melancia tem vários dados de áudio.
86 amostras de melancia são selecionadas como conjunto de treinamento, 36 conjuntos de teste e 36 conjuntos de verificação. A
proporção básica de dados é 6:2:2
| melancia | Mal passado | Maduro | maduro demais | Parcialmente nascido | soma |
|---|---|---|---|---|---|
| Número de melancias | 25 | 76 | 31 | 26 | 158 |
| Número de áudios | 145 | 440 | 192 | 162 | 939 |
| Rótulo | 0 | 1 | 2 | 3 |
2. Pré-processamento de dados
Devido ao conjunto de dados auto-coletados, cada duração de áudio é entre 6 e 30 segundos e contém vários sinais de batida. Os dados precisam ser pré-processados.
2.1 Detecção de endpoint
Link detalhado para detecção de endpoint: detecção de endpoint usando método de limite duplo usando matlab
Detecção de ponto final: refere-se à determinação do ponto inicial e final da fala a partir de um sinal contendo fala.Significado
: pode não apenas aumentar o número de amostras, mas também reduzir cálculos desnecessários durante o treinamento da rede e melhorar a precisão do treinamento do modelo.

Renderizações de detecção de endpoint de limite duplo de parâmetro duplo
Pode-se ver na figura que após o processamento da detecção do ponto final, o número de amostras aumentou e o comprimento do sinal foi bastante reduzido.
Vale a pena notar:
1. O tempo de áudio não deve ser muito curto.
Supondo que a frequência de amostragem seja de 16kHZ e que cada amostra de dados precise extrair os primeiros 1000 dados do sinal no domínio da frequência para representar o sinal, deve-se garantir que a duração de cada áudio interceptado é de pelo menos 0,0625s. (Claro, cada áudio interceptado contém pelo menos um sinal de excitação)
Frequência de amostragem = número de pontos de amostragem por unidade de tempo = número de pontos de amostragem/tempo de amostragem
2. A configuração do limite deve ser razoável.
Como há muitos áudios, o processamento em lote é necessário. Antes do processamento em lote, a configuração do limite deve ser razoável.
Suponha que apenas o método de limite duplo de parâmetro único seja usado, ou seja, baseado no método de energia de curto prazo.A detecção de ponto final define o limite (amp1 e amp2) com base na energia média de curto prazo do áudio (ou outros parâmetros) para que o sinal de excitação possa ser encontrado normalmente.

Defina limites adequadamente para encontrar sinais de excitação eficazes

2.2 Aprimoramento de dados
Se a quantidade de dados não for suficiente após a detecção do ponto final do áudio, outros aprimoramentos de dados poderão ser realizados. (A detecção do ponto final também é considerada aprimoramento de dados).
Ao realizar o aprimoramento de dados, é melhor fazer apenas algumas pequenas alterações para que haja uma pequena diferença entre os dados aprimorados e os dados de origem. Lembre-se de não alterar a estrutura dos dados originais, caso contrário, serão gerados "dados sujos". Ao processar os dados de áudio, o aumento pode ajudar o modelo a evitar overfitting e se tornar mais geral.
As alterações feitas no áudio são as seguintes: adição de ruído, alongamento da forma de onda e correção de agudos.
Ruído
adicionado O ruído adicionado é ruído branco gaussiano com valor médio de 0 e desvio padrão de 1.
#####增加噪声#####
def add_noise(data):
# 0.02为噪声因子
wn = np.random.normal(0, 1, len(data))
return np.where(data != 0.0, data.astype('float64') + 0.02 * wn, 0.0).astype(np.float32)
O Waveform Stretching
altera a velocidade/duração de um som sem afetar seu tom.
#####波形拉伸#####
def time_stretch(x, rate):
# rate:拉伸的尺寸,
# rate > 1 加快速度
# rate < 1 放慢速度
return librosa.effects.time_stretch(x, rate)
Correção de agudos
A correção de tom apenas altera o tom sem afetar a velocidade do som.
#####音高修正#####
def pitch_shifting(x, sr, n_steps, bins_per_octave=12):
# sr: 音频采样率
# n_steps: 要移动多少步
# bins_per_octave: 每个八度音阶(半音)多少步
return librosa.effects.pitch_shift(x, sr, n_steps, bins_per_octave=bins_per_octave)
Exemplo
import librosa
import numpy as np
import matplotlib.pyplot as plt
import soundfile as sf
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
fs = 16000
wav_data, y = librosa.load(r"C:\Users\Administrator\Desktop\test\10_28_1190001.wav", sr=fs, mono=True)
#####1.增加噪声#####
def add_noise(data):
# 0.02为噪声因子
wn = np.random.normal(0, 1, len(data))
return np.where(data != 0.0, data.astype('float64') + 0.02 * wn, 0.0).astype(np.float32)
#####3.波形拉伸#####
def time_stretch(x, rate):
# rate:拉伸的尺寸,
# rate > 1 加快速度
# rate < 1 放慢速度
return librosa.effects.time_stretch(x, rate)
#####4.音高修正#####
def pitch_shifting(x, sr, n_steps, bins_per_octave=12):
# sr: 音频采样率
# n_steps: 要移动多少步
# bins_per_octave: 每个八度音阶(半音)多少步
return librosa.effects.pitch_shift(x, sr, n_steps, bins_per_octave=bins_per_octave)
data_noise = add_noise(wav_data)
data_stretch = time_stretch(wav_data, rate=2)
data_pitch2 = pitch_shifting(wav_data, fs, n_steps=-6, bins_per_octave=12) # 向下移三音(如果bins_per_octave为12,则六步)
# 绘图
plt.subplot(2, 2, 1)
plt.title("波形图", fontsize=15)
time = np.arange(0, len(wav_data)) * (1.0 / fs)
plt.plot(time, wav_data)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅', fontsize=15)
plt.subplot(2, 2, 2)
plt.title("加噪", fontsize=15)
plt.plot(time, data_noise)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅/Hz', fontsize=15)
plt.subplot(2, 2, 4)
plt.title("高音修正", fontsize=15)
plt.plot(time, data_pitch2)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅/Hz', fontsize=15)
plt.subplot(2, 2, 3)
plt.title("波形拉伸", fontsize=15)
time = np.arange(0, len(data_stretch)) * (1.0 / fs)
plt.plot(time, data_stretch)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅/Hz', fontsize=15)
plt.tight_layout()
plt.show()

2.3 Transformada Rápida de Fourier (FFT)
Execute a transformada rápida de Fourier no sinal obtido após a detecção do ponto final (ou aprimoramento de dados) para obter suas características de amplitude-frequência. Extraia os primeiros 1.000 dados (ou mais) do sinal no domínio da frequência para representar o sinal.
Visualize a transformada de Fourier de uma perspectiva física , na verdade nos ajuda a mudar o método tradicional de análise de sinais no domínio do tempo para pensar na análise de problemas no domínio da frequência. O diagrama tridimensional a seguir pode nos ajudar a entender melhor essa conversão de ângulos: o
 sinal frontal no domínio do tempo Após a decomposição por Transformada de Fourier, ela se torna uma superposição de diferentes sinais de onda senoidal. Em seguida, analisamos as frequências dessas ondas senoidais para transformar um sinal no domínio da frequência. É difícil ver as características de alguns sinais no domínio do tempo. Mas se for transformado no domínio da frequência, é fácil ver as características. É por isso que muitas análises de sinal usam a transformação FFT. Além disso, a FFT pode extrair o espectro de um sinal, que também é frequentemente usado na análise de espectro.
sinal frontal no domínio do tempo Após a decomposição por Transformada de Fourier, ela se torna uma superposição de diferentes sinais de onda senoidal. Em seguida, analisamos as frequências dessas ondas senoidais para transformar um sinal no domínio da frequência. É difícil ver as características de alguns sinais no domínio do tempo. Mas se for transformado no domínio da frequência, é fácil ver as características. É por isso que muitas análises de sinal usam a transformação FFT. Além disso, a FFT pode extrair o espectro de um sinal, que também é frequentemente usado na análise de espectro.
Para computadores, apenas dados discretos e de comprimento finito podem ser processados. Outros tipos de transformação só podem ser usados em cálculos matemáticos. Na frente dos computadores, só podemos usar o método DFT, e FFT é apenas uma versão rápida do algoritmo DFT.
Em relação a como implementar o fft, existe uma biblioteca fft em numpy.Os
exemplos de programas específicos são os seguintes:
import numpy.fft as nf
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
import os
import re
from scipy.io import wavfile
# coding=utf-8
import os
import shutil
import pandas as pd
import numpy as np
import scipy.io as sio
# 对原始数据进行fft快速傅里叶变换之后,
# 每个类别整体对数据进行归一化并写入csv文件里存储数据
def myfft(sourceDir, targetDir):
# 列出源目录文件和文件夹
for file in os.listdir(sourceDir):
# 拼接完整路径
sourceFile = os.path.join(sourceDir, file)
for files in os.listdir(sourceFile):
sourceFile1 = os.path.join(sourceFile, files)
data = []
for files1 in os.listdir(sourceFile1):
# 对每一个音频数据进行fft快速傅里叶变换
try:
rate, data1 = wavfile.read(f'{
sourceDir}/{
file}/{
files}/{
files1}')
xf = np.fft.fft(data1) # 快速傅里叶变换
xff = np.abs(xf) # 取复数的绝对值,即复数的模(双边频谱)
n = 2 ** 15 # n>2*rate 即>32000 ,取了2^15 = 32768
y = xff / n # 归一化处理
y1 = y[0:(int(n / 2))] # 由于对称性,只取一半区间
data.append(y1[0:1000]) #取前一千个数据点
except Exception as e:
continue
data = np.array(data)
print(data.shape)
#对所有的数据进行标准化处理
zscore_scaler = preprocessing.StandardScaler()
data2 = zscore_scaler.fit_transform(data)
test = pd.DataFrame(data=data2)
test.to_csv(f'{
targetDir}/{
file}{
files}.csv', encoding='utf-8', header=False,index=False) # 保存为csv格式文件
if __name__ == "__main__":
# 每个类别分别进行一次,完成之后得到4个.csv文件
myfft("F:/文件/文件/watermelon/watermelon_data/split_data",
"F:/文件/文件/watermelon/make_DataSet1")


Renderizações FFT de áudio único
2.4 Produção de conjuntos de dados
Há um total de mais de 900 faixas de áudio originais, que foram expandidas para mais de 60.000 após o aprimoramento dos dados de detecção de endpoint.
Maturação da melancia e rótulos correspondentes
| Maturidade | Rótulo |
|---|---|
| Mal passado | 0 |
| Maduro | 1 |
| maduro demais | 2 |
| Parcialmente nascido | 3 |
Particionamento de conjunto de dados
Por que dividir o conjunto de dados? O
aprendizado profundo usa um grande número de classificadores lineares ou não lineares, funções de excitação diferenciáveis ou não diferenciáveis e camadas de pooling para extrair automaticamente as características do objeto de observação.
Ter uma capacidade de classificação tão boa trará dois problemas:
em redes complexas, muitos W perderam há muito tempo o significado dos pesos nas estatísticas, não conseguem obter explicações físicas claras e não conseguem realizar engenharia reversa com eficácia. Pesquisa.
A rede pode aprender muito de coisas, incluindo informações sobre ruído ou informações de casos especiais contidas na amostra.
Portanto, os motivos e métodos de prevenção de overfitting são os seguintes:
Motivo: Poucas amostras não são suficientes para generalizar suas características comuns. Muitos parâmetros podem caber em conteúdos de recursos extremamente complexos.
Razão para melhoria: Aumentar o número de amostras, mais o melhor em teoria.
Método de verificação: Pegue algumas amostras para verificação. Normalmente, todos os dados de amostra obtidos serão divididos em três conjuntos.
Conjunto de treinamento : um conjunto de amostra usado para aprendizado. Esses vetores são usados para determinar cada coeficiente específico na rede. Eles são usados para treinar o modelo.
Conjunto de validação : É um conjunto de amostra usado para ajustar os parâmetros do classificador. Durante o processo de treinamento, o modelo de rede será imediatamente verificado no conjunto de validação. Observaremos simultaneamente o desempenho do modelo nos dados do conjunto de validação e se o O valor da função de perda é A precisão diminuirá? A precisão está melhorando? Ela é usada para ajustar os hiperparâmetros.
Conjunto de teste : faz parte do conjunto de dados configurado para testar a capacidade do modelo após o treinamento, principalmente sua capacidade de classificação, sendo usado para testar a precisão do modelo e avaliar sua capacidade de generalização.
Como os dados
são um conjunto de dados de pequena escala, a taxa de divisão de dados é baseada em7: 3: 1A proporção é dividida em conjunto de treinamento, conjunto de teste e conjunto de verificação. O conjunto de treinamento e o conjunto de teste são divididos na proporção de 70% e 30% e, em seguida, 10% são retirados do conjunto de treinamento como conjunto de verificação.
Resumo do processamento
: Após a detecção do ponto final e aprimoramento dos dados do áudio original, a transformação rápida de Fourier é executada e os primeiros 1000 pontos de dados de cada sinal de áudio são considerados seus valores característicos. Os
valores característicos dos dados de áudio de cada nível de maturidade são resumidos . , armazenado em formato csv para posterior treinamento do modelo.
Leia os dados csv de 4 categorias e rotule-os de acordo.
O código do programa é o seguinte:
# 汇总所有的数据,并绘制标签
def makeall(file0, file1, file2, file3, name, savefile):
eight_medium = pd.read_csv(file0, header=None) # 8分熟
mature = pd.read_csv(file1, header=None) # 成熟
overrripe = pd.read_csv(file2, header=None) # 过熟
ripe_yet = pd.read_csv(file3, header=None) # 偏生
bfs_data = np.asarray(eight_medium)
cs_data = np.asarray(mature)
gs_data = np.asarray(overrripe)
ps_data = np.asarray(ripe_yet)
data = np.concatenate((bfs_data, cs_data, gs_data, ps_data))
bfs_label = np.zeros((bfs_data.shape[0], 1))
cs_label = np.ones((cs_data.shape[0], 1))
gs_label = 2 * np.ones((gs_data.shape[0], 1))
ps_label = 3 * np.ones((ps_data.shape[0], 1))
label = np.concatenate(((bfs_label, cs_label, gs_label, ps_label)))
variable = pd.DataFrame(label) # 将变量转化为dataframe数据结构
variable.to_csv(f'{
savefile}/{
name}_label.csv', header=None, index=None)
variable = pd.DataFrame(data) # 将变量转化为dataframe数据结构
variable.to_csv(f'{
savefile}/{
name}_data.csv', header=None, index=None) # 存储为没有表头和索引的csv文件
if __name__ == "__main__":
savefile = './makelabel/z-score_fft_alldata_0'
name = 'train'
savename = 'train_all'
t0_train = f'{
savefile}/{
name}0.csv'
t1_train = f'{
savefile}/{
name}1.csv'
t2_train = f'{
savefile}/{
name}2.csv'
t3_train = f'{
savefile}/{
name}3.csv'
makeall(t0_train, t1_train, t2_train, t3_train, savename, savefile)

2. Treinamento de modelo
1. Projeto do modelo
O projeto do modelo proposto é baseado em uma rede neural convolucional simples, com acréscimos e melhorias feitas em sua estrutura.
Estrutura Tensorflow
de aprendizado profundo do Tensorflow. Seja em um servidor, dispositivo de borda ou rede, o TensorFlow facilita o treinamento e a implantação de modelos; a criação e o treinamento de modelos avançados sem sacrificar a velocidade ou o desempenho.
Keras
tf.keras é a interface API de alto nível do TensorFlow 2.0. Ele fornece novos estilos e padrões de design para o código do TensorFlow, o que melhora muito a simplicidade e a reutilização do código TF. As autoridades também recomendam o uso de tf.keras para design de modelo. e desenvolvimento .
Use o modelo de aprendizado profundo em Keras - o modelo universal (modelo funcional do modelo) para definir o modelo. O modelo universal pode projetar redes neurais muito complexas com qualquer topologia. Comparado com o modelo sequencial (sequencial), ele só pode ser projetado linearmente e sequencialmente. Ao adicionar camadas, o modelo geral pode construir com mais flexibilidade a estrutura da rede e definir o relacionamento entre cada nível. A
interface do modelo funcional é uma forma de os usuários definirem modelos complexos, como modelos de múltiplas saídas, modelos direcionados acíclicos ou modelos com camadas compartilhadas. Em outras palavras, contanto que seu modelo não seja um modelo completo como VGG, ou seu modelo exija mais de uma saída, você deve sempre escolher um modelo funcional. Modelos funcionais são o tipo mais comum de modelo , modelos sequenciais ( Sequencial) é apenas um caso especial disso.
A Rede Neural Convolucional CNN
(CNN) é uma rede neural feed-forward frequentemente usada para processar dados com uma estrutura semelhante a uma grade, como imagens ou sons. As CNNs se destacam no reconhecimento de imagem e fala porque podem Os recursos são extraídos automaticamente sem intervenção manual.
O núcleo da CNN é a camada convolucional, que executa uma operação de convolução nos dados de entrada deslizando uma pequena janela (chamada kernel de convolução) para extrair características locais. A camada convolucional é geralmente seguida por uma camada de pooling (Pooling Layer), que é usada para reduzir a dimensão do mapa de recursos e reduzir a quantidade de cálculo.
As redes convolucionais têm duas características principais:
① Existe pelo menos uma camada convolucional usada para extrair recursos.
② A camada convolucional da rede convolucional funciona por meio de compartilhamento de peso, o que reduz bastante o número de pesos W, possibilitando Durante o treinamento, o a velocidade de convergência é significativamente mais rápida do que a da rede BP totalmente conectada ao atingir a mesma taxa de reconhecimento.
A seguir está uma rede neural convolucional unidimensional (1DCNN) baseada em uma rede neural convolucional simples.
O design do modelo é o seguinte
Parâmetros específicos para cada camada de design do modelo
| Camada (tipo) | Kernel_size | Número do filtro | Formato de saída |
|---|---|---|---|
| conv1d | 3x1 | 8 | (1000, 8) |
| max_pooling1d | (1000, 8) | ||
| normalização em lote | (1000, 8) | ||
| conv1d_1 | 3x1 | 16 | (1000, 16) |
| max_pooling1d_1 | (1000, 16) | ||
| batch_normalização_1 | (1000, 16) | ||
| conv1d_2 | 3x1 | 32 | (1000, 32) |
| max_pooling1d_2 | (500, 32) | ||
| batch_normalização_2 | (500, 32) | ||
| achatar | 16.000 | ||
| cair fora | 16.000 | ||
| denso | 32 | 32 | |
| denso_2 | 4 | 4 |
O procedimento é o seguinte
def mymodel():
inputs = keras.Input(shape=(1000, 0))
h1 = layers.Conv1D(filters=8, kernel_size=3, strides=1, padding='same', activation='relu')(inputs)
h1 = layers.MaxPool1D(pool_size=2, strides=1, padding='same')(h1)
h1 = layers.BatchNormalization()(h1)
h2 = layers.Conv1D(filters=16, kernel_size=3, strides=1, padding='same', activation='relu' )(h1)
h2 = layers.MaxPool1D(pool_size=2, strides=1, padding='same')(h2)
h2 = layers.BatchNormalization()(h2)
h2 = layers.Conv1D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(h2)
h2 = layers.MaxPool1D(pool_size=2, strides=2, padding='same')(h2)
h2 = layers.BatchNormalization()(h2)
h3 = layers.Flatten()(h2) # 扁平层,方便全连接层传入数据
h4 = layers.Dropout(0.2)(h3) # Droupt层舍弃百分之20的神经元
h4 = layers.GaussianNoise(0.005)(h4)
h4 = layers.Dense(32, activation='relu')(h4) # 全连接层,输出为32
outputs = layers.Dense(4, activation='softmax')(h4) # 再来个全连接层,分类结果为4种
deep_model = keras.Model(inputs, outputs, name='1DCNN') # 整合每个层,搭建1DCNN模型成功
return deep_model
2. Configurações de hiperparâmetros de treinamento de modelo
Hiperparâmetros geralmente se referem a alguns valores de parâmetros definidos antes do início da etapa de treinamento do algoritmo de aprendizado de máquina.Esses valores de parâmetros geralmente não podem ser aprendidos por meio do próprio algoritmo - em contraste, eles podem ser aprendidos no algoritmo. Ou aqueles parâmetros aprendidos, como peso w e tendência b.
Parâmetros de treinamento em lote
Ao treinar uma rede neural, dois parâmetros precisam ser definidos, ou seja, lote e época.
O primeiro é o tamanho (lote), o número total de amostras em um lote, ou seja, o número de amostras usadas para treinar o rede uma vez. Ao treinar a rede, a entrada de todos os dados na rede requer muitos cálculos. Geralmente dividimos os dados em vários lotes, passamos para a rede lote por lote e atualizamos os parâmetros após cada lote ser transmitido. Isso tem duas vantagens: por um lado, é um lote Todos os dados no gradiente determinam em conjunto a direção dessa descida do gradiente, por isso não é fácil se perder ao descer, reduzindo a aleatoriedade; por outro lado, porque o número de amostras em um lote são muito menores do que todo o conjunto de dados, a quantidade de cálculo também é pequena. Não muito grande.
O número de conjuntos de treinamento lidos a cada vez é chamado de tamanho do lote. Em uma rede neural convolucional, um lote grande geralmente pode fazer a rede convergir mais rapidamente. No entanto, devido à limitação de recursos de memória, o lote é muito grande. Isso pode causar memória insuficiente ou travamento do kernel do programa. Bath_size geralmente assume um valor de [16, 32, 64, 128].
Em segundo lugar, colocar todos os dados de amostra no modelo de rede neural para um treinamento é chamado de Época 1.
Suponha que o número de todas as amostras seja 1.000, definimos o tamanho do lote como 10, ou seja, lendo 10 dados por vez para treinamento, então um A rodada de treinamento de dados precisa ser lida 100 vezes para completar o treinamento. Neste
design, a Época é definida como 100 e o Tamanho do lote é definido como 128.
Função de perda
A função de perda é uma função usada para medir a diferença entre os resultados de previsão do modelo e os resultados reais.No aprendizado de máquina, geralmente usamos a função de perda para otimizar os parâmetros do modelo para que o modelo possa ajustar melhor os dados. Funções de perda comuns, incluindo erro quadrático médio, entropia cruzada, etc. Este projeto escolheu "sparse_categorical_accuracy".
Taxa de aprendizagem A
taxa de aprendizagem (taxa de aprendizagem ou lr) refere-se à magnitude da atualização dos pesos da rede no algoritmo de otimização. A taxa de aprendizagem é um dos hiperparâmetros que mais afeta o desempenho. Em comparação com outros hiperparâmetros, o ajuste da taxa de aprendizagem é mais Uma maneira de efetivamente controlar a capacidade efetiva do modelo. Portanto, para treinar uma rede neural, um dos principais hiperparâmetros que precisam ser definidos é a taxa de aprendizado. É importante escolher a taxa de aprendizado ideal. A
taxa de aprendizado pode ser constante ou gradualmente reduzido, baseado em impulso ou adaptativo. Diferentes algoritmos de otimização determinam diferentes taxas de aprendizado. Quando a taxa de aprendizado é muito grande, o modelo pode não convergir e a perda continua oscilando para cima e para baixo; quando a taxa de aprendizado é muito pequena, o modelo converge lentamente, o que requer mais tempo de treinamento. Normalmente, o valor de lr é [0,01, 0,001, 0,0001].
A taxa de aprendizado deste projeto é definida como 0,001.
Otimizador
Quando os dados, o modelo e a função de perda são determinados, o modelo matemático da tarefa foi determinado e, em seguida, um otimizador adequado (Optimizer) deve ser selecionado para otimizar o modelo.A
classe base do otimizador fornece um método para calcular a perda de gradiente, e Gradiente podem ser aplicados a variáveis. Os otimizadores mais comumente usados são SGDM e Adam. (SGD) embora a convergência seja lenta, adicionar impulso Momentum pode acelerar a convergência. Ao mesmo tempo, o algoritmo estocástico de descida de gradiente com impulso tem um melhor solução ideal. Ou seja, o modelo terá maior precisão depois de convergir. SGDM é amplamente utilizado em CV, enquanto Adam basicamente varre PNL, RL, GAN, síntese de fala e outros campos. Atualmente, Adam é um rápido otimizador convergente e comumente usado, como No campo da PNL, modelos clássicos como Transformer e BERT usam Adam e sua variante AdamW.Portanto
, o algoritmo projetado para aprendizagem adaptativa da taxa de aprendizagem desta vez é o algoritmo de otimização da taxa de aprendizagem de Adam .
3. Modelo de indicadores de avaliação de desempenho
Medir a qualidade de um modelo é uma questão fundamental no aprendizado profundo. A avaliação do modelo consiste em julgar se o modelo ajustado pela rede neural é excelente. Em muitos casos, é difícil julgar a qualidade do modelo à primeira vista, tantos surgiram indicadores de avaliação do modelo, o que é confuso. A matriz é um dos indicadores para julgar os resultados do modelo. A matriz de confusão é o método mais básico, intuitivo e simples para calcular a precisão do modelo de classificação. O A matriz de confusão conta o número de observações classificadas pelo modelo de classificação na classe errada e na classe certa, respectivamente. Em seguida, os resultados são exibidos em uma tabela. Tomando o modelo de duas classificações como exemplo, a forma da matriz de confusão é mostrada na tabela. figura.

Gráfico de matriz de confusão
4. Treinamento de modelo
Depois de determinar o design do modelo e as configurações dos hiperparâmetros de treinamento do modelo, o treinamento do modelo começa.
O código de implementação é o seguinte
"""
本段本代码是进行模型训练
"""
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
#os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from tensorflow.keras import layers, models, Model, Sequential
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
from numpy import random
#固定随机种子,在调用seed_tensorflow后还需设置model.fit中shuffle=False、worker=1.
#保证每次训练结果一致
def seed_tensorflow(seed=42):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
seed_tensorflow(42)
def read_csv_file(train_data_file_path, train_label_file_path):
"""
读取csv文件并将文件进行拼接
:param train_data_file_path: 训练数据路径
:param train_label_file_path: 训练标签路径
:return: 返回拼接完成后的路径
"""
# 从csv中读取数据
train_data = pd.read_csv(train_data_file_path, header=None)
train_label = pd.read_csv(train_label_file_path, header=None)
# 将数据集拼接起来
# 数据与标签拼接
dataset_train = pd.concat([train_data, train_label], axis=1)
dataset = pd.concat([dataset_train], axis=0).sample(frac=1, random_state=0).reset_index(drop=True)
return dataset
def get_train_test(dataset, data_ndim=1):
# 获得训练数据和标签
X_train = dataset.iloc[:, :-1]
y_train = dataset.iloc[:, -1]
# 为了增加模型的泛化能力,需要打乱数据集
index = [i for i in range(len(X_train))]
random.seed(42)
random.shuffle(index)
X_train = np.array(X_train)[index]
y_train = np.array(y_train)[index]
# 改变数据维度让他符合(数量,长度,维度)的要求
X_train = np.array(X_train).reshape(X_train.shape[0], X_train.shape[1], data_ndim)
print("X shape: ", X_train.shape)
return X_train, y_train
# 保存最佳模型
class CustomModelCheckpoint(keras.callbacks.Callback): # 使用回调函数来观察训练过程中网络内部的状态和统计信息r然后选取最佳的进行保存
def __init__(self, model, path): # (自定义初始化)
self.model = model
self.path = path
self.best_loss = np.inf # np.inf 表示+∞,是没有确切的数值的,类型为浮点型 自定义最佳损失数值
def on_epoch_end(self, epoch, logs=None): # on_epoch_end(self, epoch, logs=None)在每次迭代训练结束时调用。在不同的方法中这个logs有不同的键值
val_loss = logs['val_loss'] # logs是一个字典对象directory;
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True) # overwrite=True覆盖原有文件 # 此处为保存权重没有保存整个模型
self.best_loss = val_loss
def mymodel():
inputs = keras.Input(shape=(1000, 1))
h1 = layers.Conv1D(filters=8, kernel_size=3, strides=1, padding='same', activation='relu')(inputs)
h1 = layers.MaxPool1D(pool_size=2, strides=1, padding='same')(h1)
h1 = layers.BatchNormalization()(h1)
h2 = layers.Conv1D(filters=16, kernel_size=3, strides=1, padding='same', activation='relu')(h1)
h2 = layers.MaxPool1D(pool_size=2, strides=1, padding='same')(h2)
h2 = layers.BatchNormalization()(h2)
h2 = layers.Conv1D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(h2)
h2 = layers.MaxPool1D(pool_size=2, strides=2, padding='same')(h2)
h2 = layers.BatchNormalization()(h2)
h3 = layers.Flatten()(h2) # 扁平层,方便全连接层传入数据
h4 = layers.Dropout(0.2)(h3) # Droupt层舍弃百分之20的神经元
h4 = layers.GaussianNoise(0.005)(h4)
h4 = layers.Dense(32, activation='relu' )(h4) # 全连接层,输出为32
outputs = layers.Dense(4, activation='softmax')(h4) # 再来个全连接层,分类结果为4种
deep_model = keras.Model(inputs, outputs, name='1DCNN') # 整合每个层,搭建1DCNN模型成功
return deep_model
def bulid(X_train, y_train, X_test, y_test,X_val,y_val, batch_size=128, epochs=100):
"""
搭建网络结构完成训练
:param X_train: 训练集数据
:param y_train: 训练集标签
:param X_test: 测试集数据
:param y_test: 测试集标签
:param X_val: 验证集数据
:param y_val: 验证集标签
:param batch_size: 批次大小
:param epochs: 循环轮数
:return: acc和loss曲线
"""
model = mymodel()
model.compile(optimizer=tf.keras.optimizers.Adam(lr = 0.001,decay=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size,
validation_data=(X_val,y_val),
workers =1,
callbacks=[CustomModelCheckpoint(model, r'mybestcnn_minmax_fft_4.h5')])
keras.models.save_model(model,'./mycnn.h5')
model.summary()
# 获得训练集和测试集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 评估模型
scores = model.evaluate(X_test, y_test, verbose=1)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
y_predict = model.predict(X_test)
y_pred_int = np.argmax(y_predict, axis=1)
print(classification_report(y_test, y_pred_int, digits=4))
# 绘制acc曲线
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# 绘制混淆矩阵
y_pred_gailv = model.predict(X_test, verbose=1)
y_pred_int = np.argmax(y_pred_gailv, axis=1)
con_mat = confusion_matrix(y_test.astype(str), y_pred_int.astype(str))
con_mat = np.delete(con_mat, [0, 2, 4, 6], axis=0)
con_mat = np.delete(con_mat, [1, 3, 5, 7], axis=1)
classes = list(set(y_train))
classes.sort()
# plt.imshow(con_mat, cmap=plt.cm.Blues)
plt.imshow(con_mat, cmap='Blues')
indices = range(len(con_mat))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.title('Confusion Matrix')
plt.xlabel('guess')
plt.ylabel('true')
for first_index in range(len(con_mat)):
for second_index in range(len(con_mat[first_index])):
plt.text(first_index, second_index, con_mat[second_index][first_index], va='center', ha='center')
plt.show()
if __name__ == "__main__":
"""
频域数据集
"""
#训练集
x_train_csv_path = f'./makelabel/train_all_data.csv'
y_train_csv_path = f'./makelabel/train_all_label.csv'
dataset1 = read_csv_file(x_train_csv_path, y_train_csv_path)
X_train, y_train = get_train_test(dataset=dataset1, data_ndim=1)
#测试集
x_test_csv_path = f'./makelabel/test_all_data.csv'
y_test_csv_path = f'./makelabel/test_all_label.csv'
dataset2 = read_csv_file(x_test_csv_path, y_test_csv_path)
X_test, y_test = get_train_test(dataset=dataset2, data_ndim=1)
#验证集
x_val_csv_path = f'./makelabel/val_all_data.csv'
y_val_csv_path = f'./makelabel/val_all_label.csv'
dataset3 = read_csv_file(x_val_csv_path, y_val_csv_path)
X_val, y_val = get_train_test(dataset=dataset3, data_ndim=1)
# 模型训练
bulid(X_train, y_train, X_test, y_test,X_val,y_val)
5. Resultados e análises de treinamento de modelo
5.1 Resultados de treinamento de três tipos de conjuntos de dados
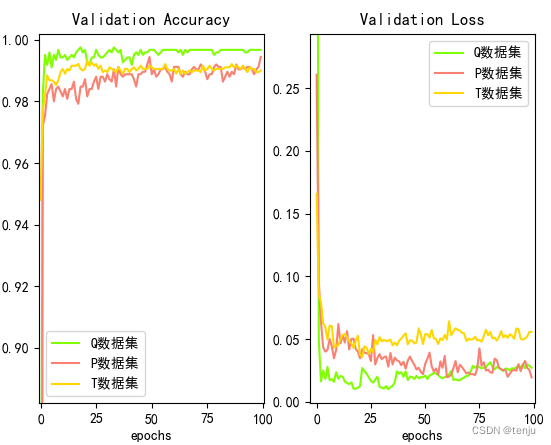
Como pode ser visto na figura, a precisão dos três conjuntos de validação de dados pode chegar a 99%,
entre os quais o conjunto de dados Q tem a maior precisão.Todos
os três conjuntos de dados atingiram mais de 98% após treinamento por 20 épocas.
Através da matriz de confusão obtida após testar o conjunto de testes em cada conjunto de dados, analisa-se o efeito de detecção do modelo em cada nível de maturidade, conforme mostrado na tabela.As
taxas de reconhecimento individuais dos três conjuntos de dados atingiram 99%, e o a precisão média também atingiu 99%,
os dados acima mostram que o modelo de classificação é muito robusto e pode detectar melhor a maturidade da melancia.
|
Pontuação F1
conjunto de dados
|
Mal passado | Maduro | maduro demais | Parcialmente nascido | média |
|---|---|---|---|---|---|
| P | 0,9958 | 0,9972 | 0,9975 | 0,9954 | 0,9965 |
| P | 0,9950 | 0,9942 | 0,9948 | 0,9926 | 0,9941 |
| T | 0,9924 | 0,9955 | 0,9945 | 0,9925 | 0,9937 |
| TODOS | 0,9935 | 0,9983 | 0,9973 | 0,9948 | 0,9960 |
Para testar o efeito de reconhecimento do modelo quando diferentes métodos de toque são misturados, todos os dados são fundidos e então treinados. A
curva de treinamento é mostrada na figura
. Após 100 épocas, a precisão do conjunto de verificação do modelo atinge 99,66%, e a perda converge para 0,02.
 A figura abaixo mostra a matriz de confusão obtida após testar o conjunto de teste em todos os dados.
A figura abaixo mostra a matriz de confusão obtida após testar o conjunto de teste em todos os dados.
A matriz de confusão mostra que o modelo ainda tem alguns erros de julgamento.
Através da matriz de confusão, a precisão média do modelo no conjunto de teste pode ser obtida como 99,78% .

5.2 Comparando o desempenho do modelo
Para comparar o desempenho do modelo, alguns modelos clássicos de redes neurais convolucionais são selecionados para experimentos comparativos.
Os modelos de redes neurais convolucionais selecionados são todos adaptados bidimensionais e unidimensionais. Os
modelos convolucionais selecionados neste artigo são ResNet18, MobileNet , AlexNet, VGGNet e GoogLeNet foram usados para experimentos comparativos; antes do experimento, o mesmo conjunto de treinamento, taxa de aprendizado, parâmetros de treinamento em lote (época, tamanho do lote), otimizador e função de perda foram usados para conduzir o mesmo processo de treinamento.
Os resultados de reconhecimento de cada modelo são mostrados na tabela
| Identificar modelo | Quantidade de parâmetros do modelo | categoria única | média | |||
|---|---|---|---|---|---|---|
| Mal passado | Maduro | maduro demais | Parcialmente nascido | |||
| 1DCNN | 514.516 | 0,9935 | 0,9983 | 0,9973 | 0,9948 | 0,9960 |
| VGG16 | 41.619.780 | 0,9855 | 0,9967 | 0,9972 | 0,9855 | 0,9912 |
| Alex Net | 12.360.900 | 0,9757 | 0,9928 | 0,9913 | 0,9797 | 0,9849 |
| GoogleNet | 3.527.476 | 0,9792 | 0,9945 | 0,9938 | 0,9803 | 0,9870 |
| ResNet18 | 3.856.772 | 0,9403 | 0,9741 | 0,9730 | 0,9587 | 0,9615 |
| MobileNet | 487.711 | 0,8765 | 0,9610 | 0,9607 | 0,9344 | 0,9332 |
Por fim,
se houver algum erro no artigo, sinta-se à vontade para apontá-lo na área de comentários ou mensagem privada.
Iniciantes e novatos ainda estão aprendendo, então espero que Haihan ~