O YOLOv8 já foi lançado há algum tempo e tem as funções de detecção de alvo, segmentação de instância, detecção de pontos-chave, rastreamento e classificação, e o efeito atingiu SOTA, tornando o YOLOv8 preferido por muitos pesquisadores. Aqui usamos principalmente o código ultralítico publicado pelo github: https://github.com/ultralytics/ultralytics .
A seguir, registramos principalmente como criar um conjunto de dados de detecção de ponto-chave por nós mesmos e executar o projeto YOLOv8. A detecção do ponto chave no projeto YOLOv8, ou seja, o ramo pose , marca principalmente a parte esquelética do corpo humano para refinar e representar o movimento do corpo humano, conforme mostrado na figura abaixo.

Formato de anotação do conjunto de dados de detecção de ponto-chave YOLOv8-pose
Ao rotular o conjunto de dados, devemos primeiro descobrir qual é o formato de dados necessário para a detecção do ponto-chave da pose YOLOv8.
O código do site oficial fornece um conjunto de dados de amostra para detecção de ponto-chave de pose, denominado coco8-pose.yaml, podemos baixar o conjunto de dados de acordo com o URL interno e dar uma olhada nos requisitos específicos de formato de anotação.
O formato de anotação de dados e as imagens de anotação do coco8-pose são os seguintes. Vejamos primeiro o formato da anotação. Este arquivo é um arquivo que termina em .txt e contém 56 dados.
O primeiro dado é 0, indicando a categoria do alvo, que é pessoa; os próximos quatro dados indicam as coordenadas do quadro retangular; há 51 dados no verso, que é 17*3, indicando as coordenadas de 17 pontos-chave e se visível.
Entre eles, 0,00000 significa não invisível, 1,00000 significa bloqueado e invisível e 2,00000 significa visível. Como a parte inferior do corpo desta imagem não é visível, os dados de coordenadas e os rótulos dos próximos pontos nos dados do rótulo são ambos 0,00000.
0 0.671279 0.617945 0.645759 0.726859 0.519751 0.381250 2.000000 0.550936 0.348438 2.000000 0.488565 0.367188 2.000000 0.642412 0.354687 2.000000 0.488565 0.395313 2.000000 0.738046 0.526563 2.000000 0.446985 0.534375 2.000000 0.846154 0.771875 2.000000 0.442827 0.812500 2.000000 0.925156 0.964063 2.000000 0.507277 0.698438 2.000000 0.702703 0.942187 2.000000 0.555094 0.950000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000

A seguir, tomamos vacas como exemplo para apresentar como criar um conjunto de dados para detecção de pontos-chave.
Use o software "labelme" para rotular os pontos-chave da vaca
Ao rotular, devemos primeiro prestar atenção em alguns pontos:
Primeiro, ao marcar os pontos-chave, primeiro use uma moldura retangular para enquadrar o alvo e depois marque os pontos-chave;
em segundo lugar, os pontos-chave não precisam de uma ordem fixa, mas cada imagem deve ser consistente. Em outras palavras, quando o ponto 1 é o nariz, o ponto 1 de todas as imagens deve ser o nariz;
terceiro, o ponto ocluído também deve ser marcado;
quarto, como o labelme não pode marcar se o ponto chave está visível, o padrão é 1,00000, aqui não fazemos nenhum processamento e depois alteramos todos para 2,00000.
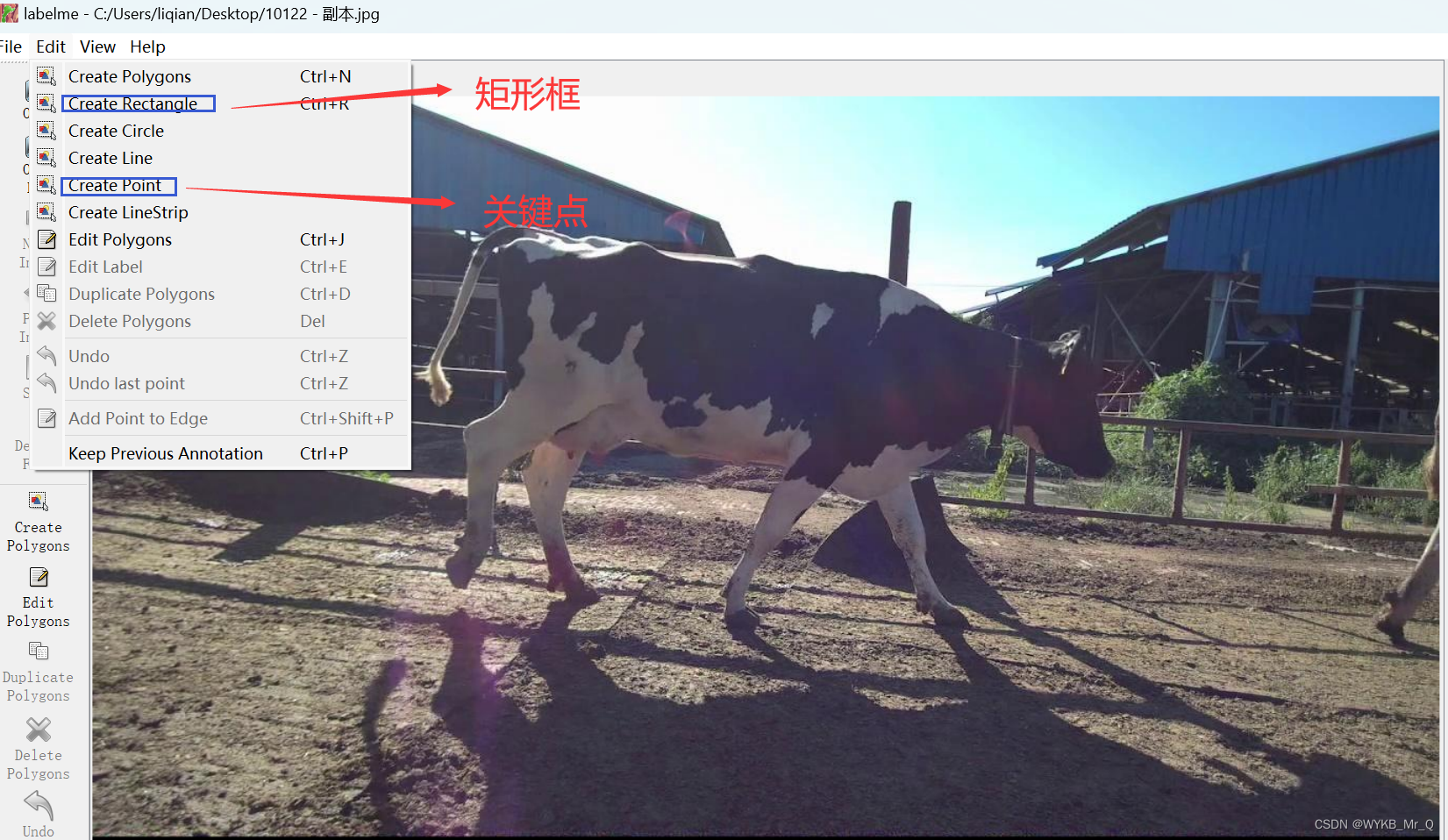

Na imagem, a caixa retangular está definida como etiqueta, que é o seu próprio tipo de dados, e os próximos pontos podem ser marcados diretamente com 1, 2, 3 ... mais conveniente. Se você pensa aqui, ainda existe um esqueleto, a ligação entre pontos, então não se preocupe, não há necessidade de marcar a ligação entre pontos e pontos. A linha de conexão é apenas a parte de visualização, que é desenhada para facilitar a observação. Nosso ponto principal aqui é prever os pontos-chave, e o resto pode ser ignorado.
Ao rotular pontos-chave e caixas retangulares, obtemos um arquivo .json que está em conformidade com a saída do labelme e, em seguida, precisamos convertê-lo em um arquivo .txt. Aqui, executamos duas etapas: primeiro convertemos a saída do rótulo para o formato coco e, em seguida, convertemos para o formato yolo.
rótulo para formato coco
A seguir está o código convertido para o formato coco. Precisamos dividir o conjunto de dados em conjunto de treinamento e conjunto de teste com antecedência e depois processá-lo duas vezes. Tomando o conjunto de treinamento como exemplo, primeiro coloque o arquivo .json marcado por labelme na pasta json e crie uma nova pasta coco para armazenar os resultados de saída.
No código a seguir, precisamos alterar o conteúdo das linhas 209-212, alterar a vaca em default="cow" para sua própria categoria e alterar 17 na linha 212 para o número de pontos-chave marcados por você.
import os
import sys
import glob
import json
import argparse
import numpy as np
from tqdm import tqdm
from labelme import utils
class Labelme2coco_keypoints():
def __init__(self, args):
"""
Lableme 关键点数据集转 COCO 数据集的构造函数:
Args
args:命令行输入的参数
- class_name 根类名字
"""
self.classname_to_id = {
args.class_name: 1}
self.images = []
self.annotations = []
self.categories = []
self.ann_id = 0
self.img_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1)
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
def _get_keypoints(self, points, keypoints, num_keypoints):
"""
解析 labelme 的原始数据, 生成 coco 标注的 关键点对象
例如:
"keypoints": [
67.06149888292556, # x 的值
122.5043507571318, # y 的值
1, # 相当于 Z 值,如果是2D关键点 0:不可见 1:表示可见。
82.42582269256718,
109.95672933232304,
1,
...,
],
"""
if points[0] == 0 and points[1] == 0:
visable = 0
else:
visable = 1
num_keypoints += 1
keypoints.extend([points[0], points[1], visable])
return keypoints, num_keypoints
def _image(self, obj, path):
"""
解析 labelme 的 obj 对象,生成 coco 的 image 对象
生成包括:id,file_name,height,width 4个属性
示例:
{
"file_name": "training/rgb/00031426.jpg",
"height": 224,
"width": 224,
"id": 31426
}
"""
image = {
}
img_x = utils.img_b64_to_arr(obj['imageData']) # 获得原始 labelme 标签的 imageData 属性,并通过 labelme 的工具方法转成 array
image['height'], image['width'] = img_x.shape[:-1] # 获得图片的宽高
# self.img_id = int(os.path.basename(path).split(".json")[0])
self.img_id = self.img_id + 1
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
def _annotation(self, bboxes_list, keypoints_list, json_path):
"""
生成coco标注
Args:
bboxes_list: 矩形标注框
keypoints_list: 关键点
json_path:json文件路径
"""
if len(keypoints_list) != args.join_num * len(bboxes_list):
print('you loss {} keypoint(s) with file {}'.format(args.join_num * len(bboxes_list) - len(keypoints_list), json_path))
print('Please check !!!')
sys.exit()
i = 0
for object in bboxes_list:
annotation = {
}
keypoints = []
num_keypoints = 0
label = object['label']
bbox = object['points']
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(self.classname_to_id[label])
annotation['iscrowd'] = 0
annotation['area'] = 1.0
annotation['segmentation'] = [np.asarray(bbox).flatten().tolist()]
annotation['bbox'] = self._get_box(bbox)
for keypoint in keypoints_list[i * args.join_num: (i + 1) * args.join_num]:
point = keypoint['points']
annotation['keypoints'], num_keypoints = self._get_keypoints(point[0], keypoints, num_keypoints)
annotation['num_keypoints'] = num_keypoints
i += 1
self.ann_id += 1
self.annotations.append(annotation)
def _init_categories(self):
"""
初始化 COCO 的 标注类别
例如:
"categories": [
{
"supercategory": "hand",
"id": 1,
"name": "hand",
"keypoints": [
"wrist",
"thumb1",
"thumb2",
...,
],
"skeleton": [
]
}
]
"""
for name, id in self.classname_to_id.items():
category = {
}
category['supercategory'] = name
category['id'] = id
category['name'] = name
# 17 个关键点数据
category['keypoint'] = [str(i + 1) for i in range(args.join_num)]
self.categories.append(category)
def to_coco(self, json_path_list):
"""
Labelme 原始标签转换成 coco 数据集格式,生成的包括标签和图像
Args:
json_path_list:原始数据集的目录
"""
self._init_categories()
for json_path in tqdm(json_path_list):
obj = self.read_jsonfile(json_path) # 解析一个标注文件
self.images.append(self._image(obj, json_path)) # 解析图片
shapes = obj['shapes'] # 读取 labelme shape 标注
bboxes_list, keypoints_list = [], []
for shape in shapes:
if shape['shape_type'] == 'rectangle': # bboxs
bboxes_list.append(shape) # keypoints
elif shape['shape_type'] == 'point':
keypoints_list.append(shape)
self._annotation(bboxes_list, keypoints_list, json_path)
keypoints = {
}
keypoints['info'] = {
'description': 'Lableme Dataset', 'version': 1.0, 'year': 2021}
keypoints['license'] = ['BUAA']
keypoints['images'] = self.images
keypoints['annotations'] = self.annotations
keypoints['categories'] = self.categories
return keypoints
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--class_name", default="cow", help="class name", type=str)
parser.add_argument("--input", default="./json", help="json file path (labelme)", type=str)
parser.add_argument("--output", default="./coco", help="output file path (coco format)", type=str)
parser.add_argument("--join_num", default=17, help="number of join", type=int)
# parser.add_argument("--ratio", help="train and test split ratio", type=float, default=0.5)
args = parser.parse_args()
labelme_path = args.input
saved_coco_path = args.output
json_list_path = glob.glob(labelme_path + "/*.json")
print('{} for json files'.format(len(json_list_path)))
print('Start transform please wait ...')
l2c_json = Labelme2coco_keypoints(args) # 构造数据集生成类
# 生成coco类型数据
keypoints = l2c_json.to_coco(json_list_path)
l2c_json.save_coco_json(keypoints, os.path.join(saved_coco_path, "keypoints.json"))
Formato Coco para formato yolo
A seguir está o código convertido para o formato yolo. Precisamos criar uma nova pasta txt para armazenar os resultados de saída. Se o seu local de armazenamento de dados acima for igual ao meu, você não precisa modificar o código. Se houver uma diferença, basta alterar os dados de entrada e os locais de saída nas linhas 12 a 17.
# COCO 格式的数据集转化为 YOLO 格式的数据集
# --json_path 输入的json文件路径
# --save_path 保存的文件夹名字,默认为当前目录下的labels。
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
# 这里根据自己的json文件位置,换成自己的就行
parser.add_argument('--json_path',
default='coco/keypoints.json', type=str,
help="input: coco format(json)")
# 这里设置.txt文件保存位置
parser.add_argument('--save_path', default='txt', type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = round(x * dw, 6)
w = round(w * dw, 6)
y = round(y * dh, 6)
h = round(h * dh, 6)
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {
} # coco数据集的id不连续!重新映射一下再输出!
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(category['name']+"\n")
id_map[category['id']] = i
# print(id_map)
# 这里需要根据自己的需要,更改写入图像相对路径的文件位置。
# list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
counter=0
for i in range(len(ann["keypoints"])):
if ann["keypoints"][i] == 2 or ann["keypoints"][i] == 1 or ann["keypoints"][i] == 0:
f_txt.write(" %s " % format(ann["keypoints"][i] + 1,'6f'))
counter=0
else:
if counter==0:
f_txt.write(" %s " % round((ann["keypoints"][i] / img_width),6))
else:
f_txt.write(" %s " % round((ann["keypoints"][i] / img_height),6))
counter+=1
f_txt.write("\n")
f_txt.close()
Dessa forma, você pode obter os mesmos dados de anotação de pontos-chave que o formato yolo, como segue:
0 0.507031 0.44294 0.516927 0.542824 0.758333 0.49213 2.000000 0.706901 0.324306 2.000000 0.59362 0.245602 2.000000 0.477734 0.213194 2.000000 0.355339 0.188889 2.000000 0.323437 0.419213 2.000000 0.296094 0.463194 2.000000 0.266797 0.637963 2.000000 0.344271 0.463194 2.000000 0.336458 0.506019 2.000000 0.365755 0.663426 2.000000 0.526563 0.506019 2.000000 0.498568 0.58125 2.000000 0.482292 0.695833 2.000000 0.595573 0.515278 2.000000 0.608594 0.598611 2.000000 0.639193 0.696991 2.000000
Mostrar conexões de esqueleto corretas
Se você treinar diretamente, descobrirá que o resultado da previsão é assim, a conexão dos segmentos de reta está errada, o que não é o que você deseja.
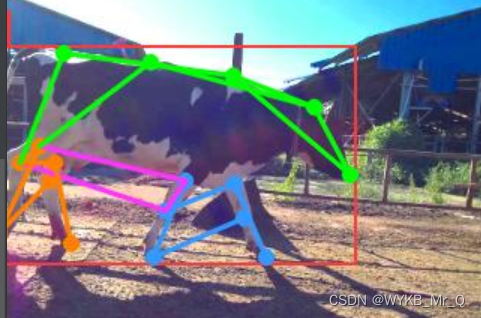
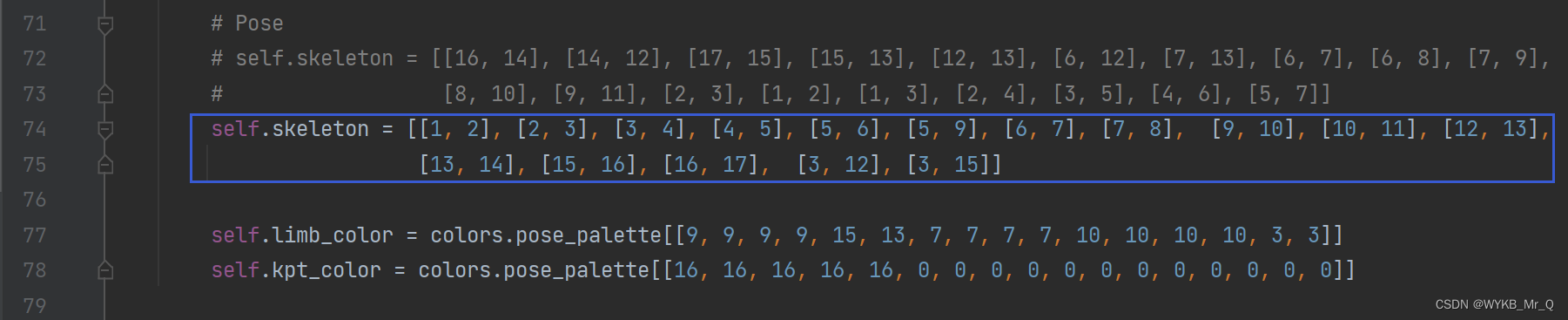
Aqui, você só precisa alterar o arquivo ./ultralytics-main\ultralytics\yolo\utils\plotting.py e self.skeletonalterar os parâmetros para suas próprias linhas de conexão. Aqui, conecte de acordo com os rótulos de pontos-chave marcados anteriormente.
Os seguintes self.limb_colorparâmetros são a configuração de cor da linha de conexão agora, self.kpt_colorque é a configuração de cor do ponto-chave. Você pode tentar ajustá-lo sozinho e precisa garantir que a quantidade corresponda.
Esta é a minha previsão, apenas um experimento experimental, mas pode-se ver que já é o caso.

Link de referência: https://blog.csdn.net/m0_57458432/article/details/128220346
https://blog.csdn.net/m0_57458432/article/details/128222620?spm=1001.2014.3001.5502
Registros diários de aprendizagem, vamos trocar e discutir juntos! Contato de infração ~