prefácio
No Redis, existe um tipo de dados. Ao armazenar, duas estruturas de dados são usadas para armazená-los separadamente. Então, por que o Redis faz isso? Isso fará com que os mesmos dados ocupem o dobro do espaço?
Cinco tipos básicos de objetos de coleção
Um objeto de coleção no Redis é uma coleção não ordenada que contém elementos do tipo string e os elementos da coleção são exclusivos e não podem ser repetidos.
Existem duas estruturas de dados subjacentes para objetos de coleção: intset e hashtable. Internamente, a codificação é usada para distinguir:

codificação intset
intset (conjunto de inteiros) pode conter valores inteiros do tipo int16_t, int32_t, int64_t, e é garantido que não haja elementos duplicados no conjunto.
A estrutura de dados intset é definida da seguinte forma (no código-fonte inset.h):
typedef struct intset {
uint32_t encoding;//编码方式
uint32_t length;//当前集合中的元素数量
int8_t contents[];//集合中具体的元素
} intset;
复制代码A figura a seguir é um diagrama simplificado do armazenamento de objetos de coleção de um intset:

codificação
A codificação dentro do intset registra o tipo de armazenamento de dados do conjunto inteiro atual, existem três tipos principais:
- INTSET_ENC_INT16
Neste momento, cada elemento em contents[] é um valor inteiro do tipo int16_t, o intervalo é: -32768 ~ 32767 (-2 à 15ª potência ~ 2 à 15ª potência - 1).
- INTSET_ENC_INT32
Neste momento, cada elemento em contents[] é um valor inteiro do tipo int32_t, o intervalo é: -2147483648 ~ 2147483647 (-2 à 31ª potência ~ 2 à 31ª potência - 1).
- INTSET_ENC_INT64
Neste momento, cada elemento em contents[] é um valor inteiro do tipo int64_t e o intervalo é: -9223372036854775808 ~ 9223372036854775807 (-2 à 63ª potência ~ 2 à 63ª potência - 1).
conteúdo[]
contents[] Embora a definição da estrutura seja escrita como tipo int8_t, o tipo de armazenamento real é determinado pela codificação acima.
Atualização de coleção de inteiros
Se os elementos no conjunto de inteiros forem todos de 16 bits no início e forem armazenados no tipo int16_t, outro inteiro de 32 bits precisará ser armazenado, o conjunto de inteiros original precisará ser atualizado e o inteiro de 32 bits pode ser armazenado após a atualização Armazenado em uma coleção de inteiros. Isso envolve a atualização do tipo do conjunto inteiro. O processo de atualização tem principalmente 4 etapas:
- Expanda o tamanho do espaço da matriz subjacente de acordo com o tipo do elemento recém-adicionado e aloque o novo espaço de acordo com o número de bits dos elementos existentes após a atualização.
- Converta os elementos existentes e coloque os elementos convertidos de volta na matriz, um por um, de trás para frente.
- Coloque o novo elemento no início ou no final do array (porque a condição para acionar a atualização é que o tipo inteiro do array atual não pode armazenar o novo elemento, então o novo elemento é maior ou menor que o elemento existente).
- Modifique a propriedade de codificação para a codificação mais recente e modifique a propriedade de comprimento de forma síncrona.
PS: Assim como a codificação de objetos string, uma vez que o tipo da coleção de inteiros é atualizado, a codificação permanecerá e não poderá ser rebaixada.
Exemplo de atualização
1. Suponha que temos um armazenamento de coleção cuja codificação é int16_t e armazena internamente 3 elementos:

2. Neste momento, um inteiro 50000 precisa ser inserido, e verifica-se que não pode ser armazenado, e 50000 é um inteiro do tipo int32_t, portanto, é necessário solicitar um novo espaço e o tamanho do aplicativo espaço é 4 * 32 - 48=80.

3. Agora há 4 elementos a serem colocados no novo array, e o array original está classificado em 3º, então é necessário mover os 3 atualizados para os bits 64-95.

4. Vá em frente e mova o 2 atualizado para 32-63 bits.

5. Continue a mover o 1 atualizado para os bits 0-31.

6. O 50000 será então colocado nos bits 96-127.

7. Finalmente, os atributos de codificação e comprimento serão modificados e a atualização será concluída após a modificação.
codificação de tabela de hash
A estrutura da tabela de hash foi analisada detalhadamente na descrição anterior do objeto de hash, se você quiser saber mais sobre ela, clique aqui.
conversão de codificação intset e hashtable
O Redis optará por usar a codificação intset quando uma coleção atender às duas condições a seguir:
- Todos os elementos mantidos por um objeto de coleção são valores inteiros.
- O número de elementos armazenados no objeto de coleção é menor ou igual a 512 (esse limite pode ser controlado pelo arquivo de configuração set-max-intset-entries).
Uma vez que os elementos da coleção não atendem às duas condições acima, a codificação da tabela de hash será selecionada.
Comandos comuns para objetos de coleção
- sadd key member1 member2: Inclua um ou mais elementos membros na chave set e retorne o número de adições bem-sucedidas. Se o elemento já existir, ele será ignorado.
- membro da chave sismember: Determine se o membro do elemento existe na chave definida.
- srem key member1 member2: Remova os elementos na chave definida e os elementos inexistentes serão ignorados.
- smove source dest member: Mova o elemento membro da coleção source para dest ou não faça nada se o membro não existir.
- chave smembers: Retorna todos os elementos na chave definida.
Conhecendo os comandos comuns para manipulação de objetos de coleção, podemos verificar o tipo e a codificação do objeto hash mencionado acima.Antes de testar, para evitar a interferência de outros valores de chave, primeiro executamos o comando flushall para limpar o banco de dados Redis.
Execute os seguintes comandos em sequência:
sadd num 1 2 3 //设置 3 个整数的集合,会使用 intset 编码
type num //查看类型
object encoding num //查看编码
sadd name 1 2 3 test //设置 3 个整数和 1 个字符串的集合,会使用 hashtable 编码
type name //查看类型
object encoding name //查看编码
复制代码Obtenha o seguinte efeito:

Pode-se ver que quando há apenas inteiros nos elementos do conjunto, o conjunto usa a codificação intset, e quando os elementos do conjunto contêm não inteiros, a codificação hashtable é usada.
Cinco tipos básicos de objetos de coleção ordenados
A diferença entre um conjunto ordenado e um conjunto no Redis é que cada elemento no conjunto ordenado está associado a uma pontuação de tipo duplo e, em seguida, classificado em ordem crescente da pontuação. Em outras palavras, a ordem do conjunto classificado é determinada pela fração quando definimos o valor nós mesmos.
Existem duas estruturas de dados subjacentes para objetos de conjunto ordenados: skiplist e ziplist. Internamente, também se distingue pela codificação:

codificação da lista de saltos
skiplist é a lista de pulos, às vezes chamada simplesmente de lista de pulos. O objeto de conjunto ordenado codificado com skiplist usa a estrutura zset como a implementação subjacente, e o zset contém um dicionário e uma lista de ignorar.
mesa de salto
A tabela de saltos é uma estrutura de dados ordenada, e sua principal característica é atingir o propósito de acessar nós rapidamente, mantendo múltiplos ponteiros para outros nós em cada nó.
Na maioria dos casos, a eficiência da tabela de saltos pode ser igual à da árvore balanceada, mas a implementação da tabela de saltos é muito mais simples do que a implementação da árvore balanceada, então o Redis opta por usar a tabela de saltos para implementar a tabela de saltos ordenada. definir.
A figura a seguir é uma lista encadeada ordenada comum. Se quisermos encontrar o elemento 35, podemos percorrer apenas do início ao fim (os elementos da lista encadeada não suportam acesso aleatório, portanto, a pesquisa binária não pode ser usada e a matriz pode ser acessada aleatoriamente por meio de subscritos), de modo que a pesquisa binária é geralmente aplicável a matrizes classificadas), e a complexidade de tempo é O(n).

Então, se pudermos pular diretamente para o meio da lista vinculada, podemos economizar muitos recursos. Este é o princípio da lista de saltos. Como mostrado na figura a seguir, é um exemplo da estrutura de dados da lista de saltos :
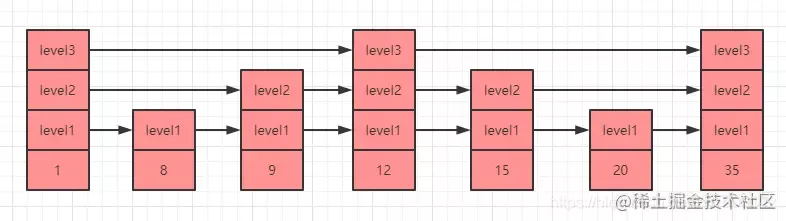
Na figura acima, nível1, nível2 e nível3 são os níveis da lista de saltos. Cada nível tem um ponteiro para o próximo elemento do mesmo nível. Por exemplo, quando percorremos para encontrar o elemento 35 na figura acima, há três opções:
- A primeira é executar o ponteiro do nível level1, que precisa ser percorrido 7 vezes (1->8->9->12->15->20->35) para encontrar o elemento 35.
- A segunda é executar o ponteiro de nível level2, e só precisa percorrer 5 vezes (1->9->12->15->35) para encontrar o elemento 35.
- O terceiro tipo é executar os elementos do nível level 3. Neste momento, basta percorrer 3 vezes (1->12->35) para encontrar o elemento 35, o que melhora muito a eficiência.
Estrutura de armazenamento de skiplist
Cada nó na lista de saltos é um nó zskiplistNode (no código-fonte server.h):
typedef struct zskiplistNode {
sds ele;//元素
double score;//分值
struct zskiplistNode *backward;//后退指针
struct zskiplistLevel {//层
struct zskiplistNode *forward;//前进指针
unsigned long span;//当前节点到下一个节点的跨度(跨越的节点数)
} level[];
} zskiplistNode;
复制代码- nível
level é o nível na tabela de salto, que é um array, o que significa que um elemento de um nó pode ter vários níveis, ou seja, vários ponteiros para outros nós, e o programa pode escolher o caminho mais rápido para melhorar o acesso através de ponteiros em velocidade de diferentes níveis.
nível é um número entre 1 e 32 que é gerado aleatoriamente de acordo com a lei de potência toda vez que um novo nó é criado.
- para a frente (ponteiro para a frente)
Cada camada terá um ponteiro para o elemento no final da lista vinculada, e o ponteiro para frente precisa ser usado ao percorrer o elemento.
- período
O span registra a distância entre dois nós. Deve-se notar que se apontar para NULL, o span é 0.
- para trás (ponteiro para trás)
Ao contrário do ponteiro para frente, há apenas um ponteiro para trás, então você só pode voltar para o nó anterior a cada vez (o ponteiro para trás não é desenhado na figura acima).
- ele (elemento)
O elemento na tabela de salto é um objeto sds (a versão anterior usava o objeto redisObject) e o elemento deve ser exclusivo e não pode ser repetido.
- pontuação
A pontuação do nó é um número de ponto flutuante do tipo duplo. Na tabela de salto, os nós são organizados em ordem crescente de acordo com suas pontuações. As pontuações de diferentes nós podem ser repetidas.
A descrição acima é apenas um nó na lista de saltos e vários nós zskiplistNode formam um objeto zskiplist:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//跳跃表的头节点和尾结点指针
unsigned long length;//跳跃表的节点数
int level;//所有节点中最大的层数
} zskiplist;
复制代码Neste ponto, você pode pensar que o conjunto ordenado é implementado com este zskiplist, mas, na verdade, o Redis não usa diretamente o zskiplist para implementar, mas usa o objeto zset para envolvê-lo novamente.
typedef struct zset {
dict *dict;//字典对象
zskiplist *zsl;//跳跃表对象
} zset;
复制代码Então, no final, se um conjunto ordenado usa a codificação skiplist, sua estrutura de dados é mostrada na figura a seguir:
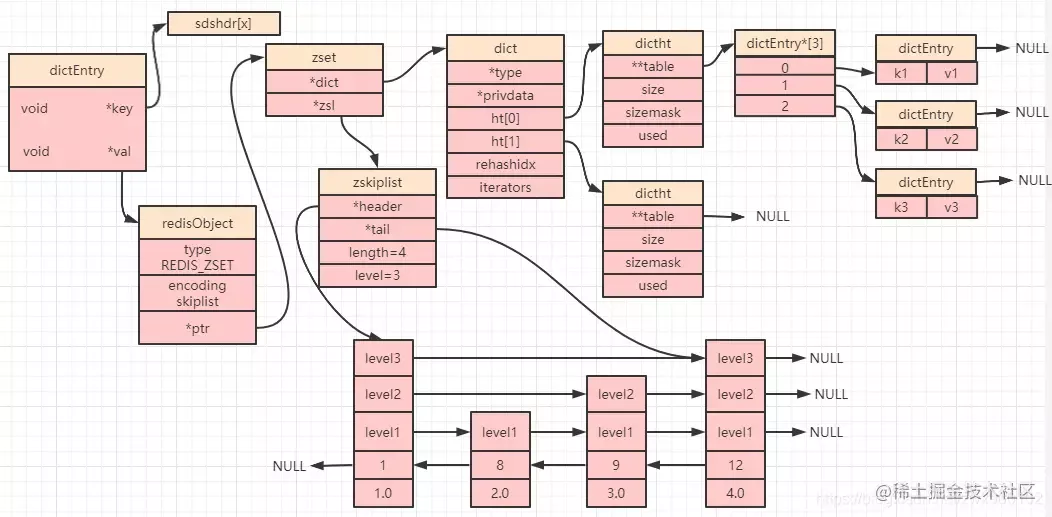
A chave do dicionário na parte superior da figura acima corresponde ao elemento do conjunto ordenado (membro), e o valor corresponde à pontuação (pontuação). Na parte inferior da figura acima, os inteiros da tabela de saltos 1, 8, 9 e 12 também correspondem ao elemento (membro), e o número de tipo duplo na última linha é a pontuação (pontuação).
Ou seja, os dados no dicionário e na tabela de salto apontam para os elementos que armazenamos (as duas estruturas de dados apontam para o mesmo endereço, portanto, os dados não serão armazenados de forma redundante).Por que o Redis faz isso?
Por que optar por usar um dicionário e uma tabela de pular
Conjuntos ordenados podem ser implementados usando skip table diretamente ou usando dicionário sozinho, mas vamos pensar sobre isso, se usarmos skip table sozinho, embora possamos usar um ponteiro com um grande intervalo para percorrer os elementos para encontrar os dados que precisamos, é complicado. O grau ainda chega a O(logN), e a complexidade de obter um elemento em um dicionário é O(1). Se você usar um dicionário sozinho para obter elementos, é muito rápido, mas o dicionário é desordenado, Portanto, se você deseja encontrar um intervalo, é necessário Classificar é uma operação demorada, portanto, o Redis combina duas estruturas de dados para maximizar o desempenho, que também é a sutileza do design do Redis.
codificação de lista zip
As listas compactadas são usadas em objetos de lista e objetos de hash. Para obter detalhes, clique aqui.
blog.csdn.net/zwx900102/a…
conversão de codificação ziplist e skiplist
Quando um objeto de conjunto ordenado atende a ambas as condições a seguir, ele usará a codificação ziplist para armazenamento:
- O número de elementos armazenados no objeto de conjunto classificado é menor que 128 (pode ser modificado configurando zset-max-ziplist-entries).
- O comprimento total de todos os elementos armazenados no objeto de conjunto classificado é menor que 64 bytes (pode ser modificado configurando zset-max-ziplist-value).
Comandos Comuns do Objeto de Coleção Ordenado
- zadd key score1 member1 score2 member2: Adicione um ou mais elementos (membros) e suas pontuações à chave do conjunto ordenado.
- zscore key member: Retorna a pontuação do membro membro na chave do conjunto classificado.
- zincrby key num member: adiciona num ao membro na chave de conjunto ordenada e num pode ser um número negativo.
- zcount key min max: Retorna o número de membros cujo valor de pontuação está no intervalo [min,max] na chave do conjunto classificado.
- zrange key start stop: Retorna todos os membros no intervalo [start, stop] depois que a pontuação na chave do conjunto ordenado é organizada de pequeno para grande.
- zrevrange key start stop: Retorna todos os membros no intervalo [start, stop] depois que as pontuações na chave do conjunto ordenado são organizadas de grande para pequeno.
- zrangebyscore key min max: Retorna todos os elementos no intervalo [min,max] no conjunto classificado classificado por pontuação de pequeno a grande. Observe que o padrão é um intervalo fechado, mas você pode adicionar ( ou [ antes dos valores de max e min para controlar o intervalo aberto e fechado.
- zrevrangebyscore key max min: Retorna todos os elementos no intervalo [min,max] no conjunto classificado classificado por pontuação de grande a pequeno. Observe que o padrão é um intervalo fechado, mas você pode adicionar ( ou [ antes dos valores de max e min para controlar o intervalo aberto e fechado.
- zrank key member: Retorna a classificação (de pequeno a grande) de elementos em member no conjunto classificado e o resultado retornado começa em 0.
- zrevrank key member: Retorna a classificação dos elementos no membro no conjunto classificado (de grande para pequeno) e o resultado retornado começa em 0.
- zlexcount key min max: Retorna o número de membros entre min e max no conjunto classificado. Observe que min e max neste comando devem ser precedidos por ( ou [ para controlar o intervalo aberto e fechado, e os valores especiais - e + representam infinito negativo e infinito positivo, respectivamente.
Conhecendo os comandos comuns para operar objetos conjuntos ordenados, podemos verificar o tipo e a codificação do objeto hash mencionado acima.Antes de testar, para evitar a interferência de outros valores de chave, primeiro executamos o comando flushall para limpar o banco de dados Redis.
Antes de executar o comando, primeiro modificamos o parâmetro zset-max-ziplist-entries no arquivo de configuração para 2 e, em seguida, reiniciamos o serviço Redis.
Após a conclusão da reinicialização, execute os seguintes comandos em sequência:
zadd name 1 zs 2 lisi //设置 2 个元素会使用 ziplist
type name //查看类型
object encoding name //查看编码
zadd address 1 beijing 2 shanghai 3 guangzhou 4 shenzhen //设置4个元素则会使用 skiplist编码
type address //查看类型
object encoding address //查看编码
复制代码Obtenha o seguinte efeito:

Resumir
Este artigo analisa principalmente os princípios de implementação das estruturas de armazenamento subjacentes intset e skiplist de objetos de conjunto e objetos de conjunto ordenados, e se concentra em como conjuntos ordenados implementam ordenação e por que duas estruturas de dados (dicionário e lista de saltos) são usadas para armazenamento simultâneo. os dados.
Autor:
Official Account_IT Link do irmão: https://juejin.cn/post/7075575482669858824